ผู้อ่านบทความนี้ควรอ่านบทความ Q learning และ Deep Q Learning มาก่อน
บทความนี้อธิบายวิธีจากเปเปอร์ Dueling Network Architectures for Deep Reinforcement Learning
State Value Function และ Advantage Function
ก่อนจะเริ่มเรื่อง dueling-DQN อยากให้ทุกคนได้รู้จักสองค่านี้ก่อน
-
State-value function หรือ $V(s)$ เป็น ค่า cumulative reward ที่คาดว่าจะได้รับ หลังจากการอยู่ใน state $s$ ณ เวลาปัจจุบัน และ ปฎิบัติตาม policy $\pi$ ไปเรื่อย ๆ ในอนาคต ดังแสดงตามสมการด้านล่าง
\begin{equation} \label{eq:V} V_{\color{blue}\pi}(s_t) = {\color{purple}\mathbb{E}}[{\color{red}\sum_{i=0}^{\infty} \gamma^i r_{t+i}} | {\color{green}s=s_t}] \end{equation}
หรือพูดง่าย ๆ ก็คือค่านี้บอกว่าความดีงามโดยรวมของ state นี้ โดยที่ไม่ได้เจาะจงไปที่ action ใด action หนึ่งโดยเฉพาะ เช่น ถ้าเรามีสอง state ดังรูปด้านล่าง ค่า $V(s_A)$ นั้นจะมีค่ามากกว่าค่า $V(s_B)$
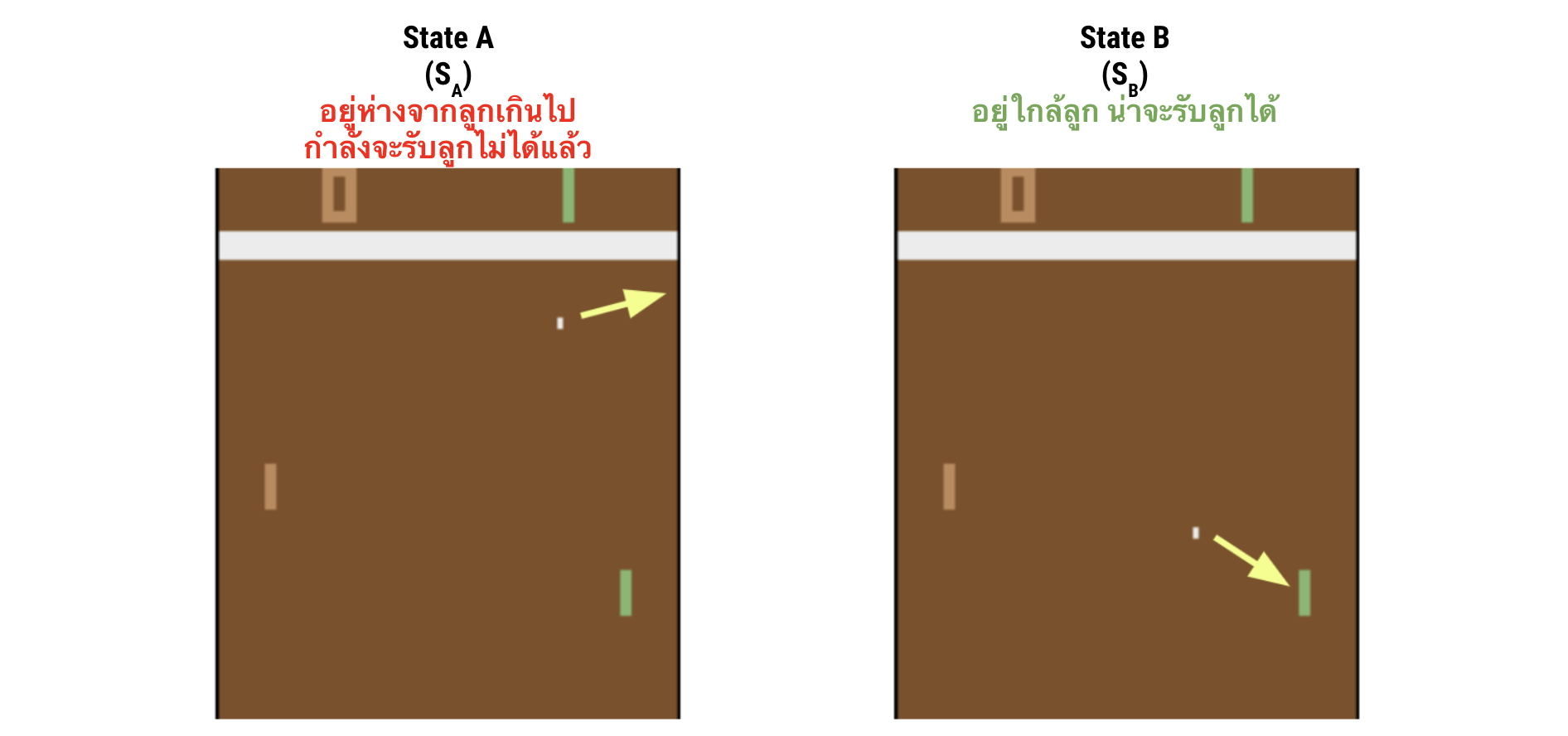
อย่าสับสนกับค่า $Q(s,a)$ ตอนเราดูค่า $Q(s,a)$ นั้นเราดูใน state และเทียบระหว่าง action ว่าใน state นั้น action ใดดีที่สุด แต่ตอนดูค่า $V(s)$ นั้น เราพยายามจะเทียบระหว่าง state ว่า state ใดดีกว่ากัน
-
Advantage function หรือ $A(s,a)$ นั้นบอกว่า action $a$ ใน state $s$ นั้น เป็นอย่างไรเมื่อเทียบกับ action อื่น ๆ ใน state $s$ นั้น
ซึ่งคำว่า “เป็นอย่างไรเมื่อเทียบกับ action อื่น ๆ ใน state นั้น” ที่จริงแล้วมันก็คือการที่บอกว่าค่า $Q(s,a)$ ของ action นั้น ๆ มีค่ามากกว่าหรือน้อยกว่าค่า $V(s)$ เท่าไหร่
อย่าลืมว่าค่า $V(s)$ มันบ่งบอกภาพรวมของ state หรือก็คือถ้ามาอยู่ที่ state นี้แล้ว cumulative reward ในระยะยาวเป็นเท่าไหร่
ส่วน $Q(s,a)$ บอกเจาะจงไปถึง action หรือก็คือใน state นี้ถ้าทำ action นี้จะได้ cumulative reward เท่าไหร่
เพราะฉะนั้นเราสามารถเขียนความสัมพันธ์ระหว่าง $V(s)$, $A(s,a)$ และ $Q(s,a)$ ได้ดังสมการด้านล่าง
\begin{equation} \label{eq:Q} A(s,a) = Q(s,a) - V(s) \end{equation}
Dueling DQN
Motivation
ในหลาย ๆ ปัญหา มันมักจะมี state ที่ไม่ว่าจะทำ action ใด ก็ได้ผลเหมือน ๆ กัน หรือมี action ที่ซ้ำ ๆ กันอยู่ เช่น เราเล่นเกมขับรถหลบรถคันอื่นบนถนน ใน state ที่บนถนนไม่มีรถเลย ทุก action ก็มีค่าเท่ากัน เพราะบังคับไปทางไหนก็ได้ ไม่ชนรถคันอื่นอยู่ดี
ในกรณีเหล่านี้ advantage function ของทุก action ก็จะเป็น 0 หมดเลย และถ้าย้อนไปดูในสมการที่ \eqref{eq:Q} นั้นเราก็จะได้ว่าค่า $Q(s,a)$ นั้นจะเท่ากับ $V(s,a)$ ไปโดยปริยาย
ซึ่งถ้าเราใช้วิธี DQN เหมือนที่เคยทำกันมา ในการอัพเดท neural network ด้วยแต่ละ experience เราจะอัพเดทแค่ค่า $Q(s,a)$ ของ action ใน experience นั้น ๆ ซึ่งถ้าเกิดกรณีอย่างที่กล่าวไว้ขึ้นมา เราก็ต้องค่อย ๆ ปรับค่า $Q(s,a)$ ของทุก action เท่ากันหมด ซึ่งก็อาจจะใช้เวลานานหน่อย
แต่ถ้าเรามีวิธีที่เราสามารถแยกการอัพเดทค่า $V(s)$ และ $A(s,a)$ ออกมาได้ แล้วเราสามารถอัพเดทค่า $V(s)$ ทุกครั้ง (ไม่ว่า experience นั้นจะทำ action ไหนก็ตาม) อย่างน้อย ๆ มันก็จะทำให้เราได้ค่าโดยรวมว่า state นั้นเป็นอย่างไรได้เร็วขึ้น
Proposed Method
ซึ่งวิธีที่เค้าใช้ในการแชร์ค่า $V(s)$ นั้นก็คือ เค้าบอกให้เปลี่ยนตัว network architecture ของ DQN เล็กน้อยดังรูปด้านล่าง
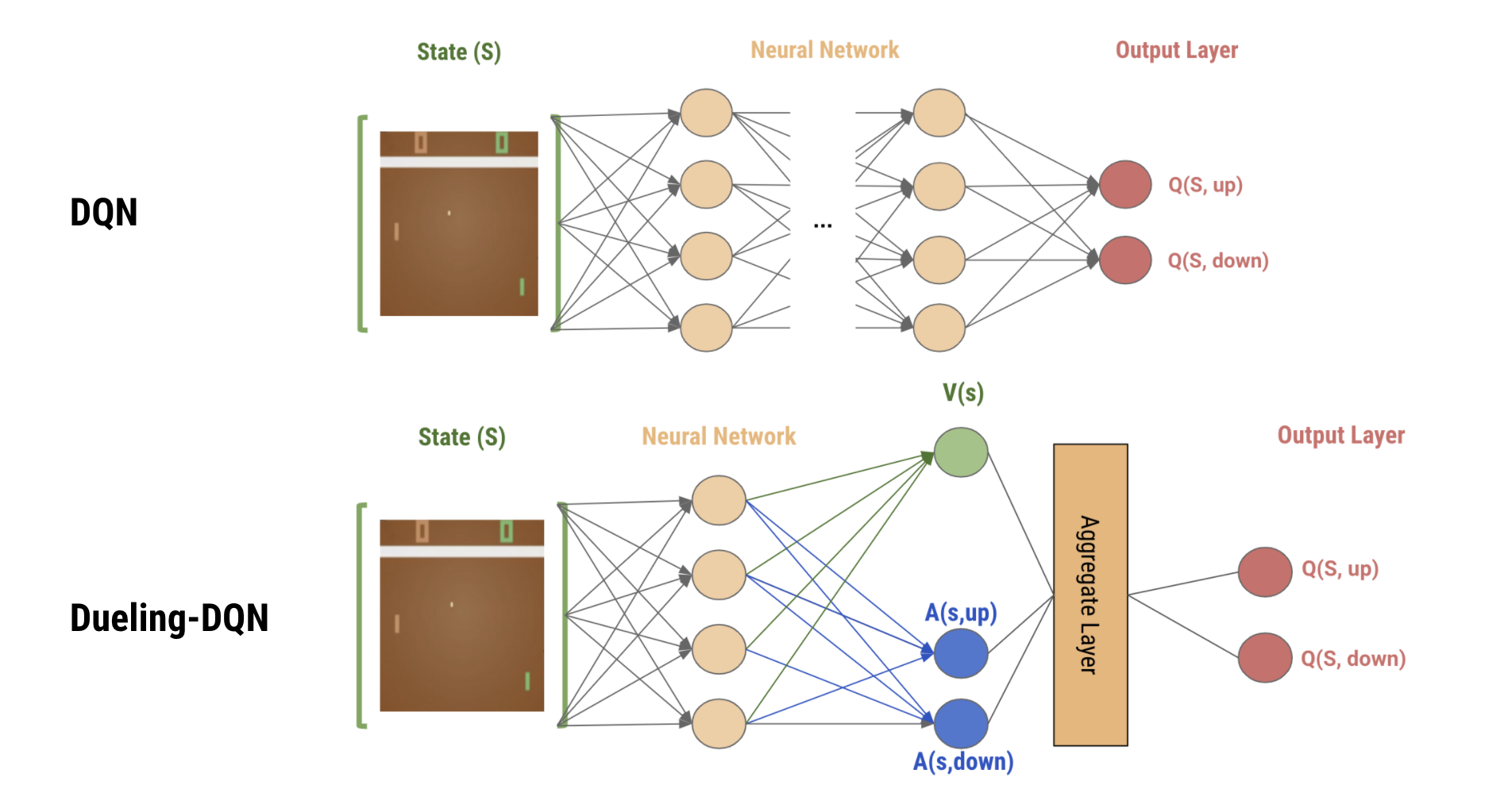
จากภาพด้านบนจะเห็นได้ว่า ใน Dueling-DQN นั้น
-
เราจะเริ่มด้วยการใส่ state ไปใน shared neural network ซึ่งในส่วนนี้เราคาดหวังว่าให้มันเรียนรู้ low-level feature ของ state นั้น ๆ ให้ก่อน เช่น ถ้าเราใส่ภาพเกม Pong เข้าไป ในส่วนนี้ก็ควรจะเรียนรู้ตำแหน่งของลูกบอลหรืออะไรแบบนี้
-
หลังจากนั้น เราจะแบ่ง network ออกมาเป็น 2 ทาง
- ทางแรกใช้สำหรับประมาณค่า state-value function หรือ $V(s)$ ซึ่งจะเป็น fully connected ที่ต่อมาจาก layer ก่อนหน้า ซึ่งจะต่อไปกี่ layers ก็ได้ แต่สุดท้ายแล้ว output ของทางนี้จะมีเพียง node เดียวซึ่งก็คือ $V(s)$ นั่นเอง
- ทางที่สองจะมีไว้ประมาณค่า advantage function หรือ $A(s,a)$ ซึ่งก็จะเป็น fully connected เช่นเดียวกัน จะต่อไปกี่ layers ก็ได้ แต่สุดท้ายแล้วที่ output จะมีจำนวน node เท่ากับ จำนวน action ซึ่งแต่ละ node มีหน้าที่ประมาณค่า $A(s,a)$ ของแต่ละ action $a$ นั่นเอง
-
ต่อมา เราจะนำผลลัพธ์จากทั้ง 2 ทางมาผ่าน aggregate layer เราก็จะได้ค่า $Q(s,a)$ ของแต่ละ action มา
วิธีคำนวณค่า $Q(s,a)$ ใน aggregate layer
ถ้าเราดูจากสมการที่ \eqref{eq:Q} เราก็แค่ย้ายข้างสมการซะ จะได้ว่า $Q(s,a)$ เกิดจากการนำค่า $V(s)$ มาบวกกับ $A(s,a)$ แค่นั้นเอง
\begin{equation} \label{eq:Q-2} \color{red} Q(s,a) = V(s) + A(s,a) \end{equation}
งั้นเราเอาสมการนี้ไปใช้เป็น aggregate layer เลยได้บ่ ? –> คำตอบก็คือไม่ได้นะะะะะะ
เพราะสมการ \eqref{eq:Q-2} มันมีปัญหาที่ชื่อว่า unindentifiable ชื่อดูน่ากลัว แต่จริง ๆ แล้วมันเป็นปัญหาแบบบ้าน ๆ เลย ก็คือถ้าเรารู้ค่า $Q(s,a)$ เนี่ย เราก็ไม่รู้ค่า $V(s)$ และ $A(s,a)$ อยู่ดี แล้วเราจะ back propagate แยกสองทางกลับไปอัพเดทค่า $V(s)$ กับ $A(s,a)$ ได้ยังไง
ยกตัวอย่างเช่น ถ้าเราต้องการจะอัพเดท dueling network ให้ทำนายค่า $Q(s,a)$ ของ state หนึ่งออกมาเป็น $[15,20,25]$ เราก็ต้อง back propagate กลับไปอัพเดทค่า $V$ และ $A$ แต่ละตัว แต่ว่าถ้าสมการที่ \eqref{eq:Q-2} เป็น aggregate layer นั้น เราอาจจะได้ค่า target ของ $V(s)$ และ $A(s,a)$ ได้หลาย ๆ แบบ เช่น
- $V(s)=0$ และ $A(s,a) = [15,20,25]$
- $V(s)=5$ และ $A(s,a) = [10,15,10]$
- $V(s)=10$ และ $A(s,a) = [5,10,15]$
- ETC.
วิธีการแก้ปัญหา unidentifiability
เริ่มจากย้อนไปมองว่าตอนเราทำ DQN หรือ Dueling-DQN เนี่ย policy ที่เราใช้คือเราจะเลือก action ที่ให้ค่า $Q(s,a)$ มากที่สุด หรือก็คือ
\begin{equation} \label{eq:policy} a^\ast = \pi(s) = argmax_a Q(s,a) \end{equation}
ถ้าเป็นแบบนั้นก็แสดงว่าใน state ใด ๆ เราก็เลือกแต่ action ที่เป็น optimal action แค่อันเดียวอยู่แล้ว เพราะฉะนั้น $V(s)$ ของ state ใด ๆ จะมีค่าเท่ากับ $Q(s,a)$ ของ optimal action ใน state นั้น ๆ
\begin{equation} \label{eq:V-t} V_\pi (s) = V_{argmax_a Q(s,a)} (s) = Q(s,a^\ast) \end{equation}
ถ้าเรานำสมการที่ \eqref{eq:V-t} ไปใช้ร่วมกับสมการที่ \eqref{eq:Q-2} จะทำให้เราสามารถหาค่า $A(s,a)$ และ $V(s)$ ที่ unique จากค่า $Q(s,a)$
ยกตัวอย่างเช่น ถ้าเรารู้ว่าค่า $Q(s,a)$ ของทั้ง 3 actions เป็นดังนี้ $[15,20,25]$ ก็แปลว่า
- $V(s)$ นั้นเท่ากับ $25$ เพราะ $V(s)$ จะมีค่าเท่ากับ $Q(s,a^\ast)$
- และเมื่อเราล็อคค่า $V(s)$ ไว้แล้ว เราก็หาค่า $A(s,a)$ ได้ไม่ยาก ซึ่งค่า $A(s,a)$ ในกรณีนี้มีค่าเป็น $[-10,-5,0]$
โดยสรุปก็คือ ถ้าเราสามารถล็อคค่า $V(s)$ ให้เท่ากับ $Q(s,a^\ast)$ ได้นั้นเราก็จะสามารถแก้ปัญหานี้ได้
เพราะฉะนั้น ในเปเปอร์เค้าก็เลยเปลี่ยนสมการที่ \eqref{eq:Q-2} เป็นสมการด้านล่าง
\begin{equation} \label{eq:aggregate_layer_max} Q(s,a) = V(s) + (A(s,a) - max_{a’} A(s,{a’})) \end{equation}
จะเห็นได้ว่าสมการที่ $\eqref{eq:aggregate_layer_max}$ จะกลายเป็น
- $Q(s,a^\ast) = V(s) + 0$ เมื่อ $a^\ast$ เป็น optimal action
- $Q(s,a) = V(s) + negative \; value$ ในกรณีของ action อื่น ๆ
ซึ่งเราจะใช้สมการที่ \eqref{eq:aggregate_layer_max} มาเป็น aggregate layer เลยก็ได้ แต่ว่าคนเขียนเปเปอร์เค้าก็ได้นำเสนออีกสมการนึงขึ้นมาใช้แทน เพื่อเพิ่ม stability ระหว่างการเทรนด้วยการเปลี่ยนจากการหาค่า max มาเป็นการคำนวณค่า mean แทน ดังแสดงในสมการที่ \eqref{eq:aggregate_layer} ซึ่งจะทำให้ค่า $Q(s,a)$ ที่ทำนายออกมานั้นค่อย ๆ เปลี่ยนไปตามค่า mean ที่เปลี่ยนไป
\begin{equation} \label{eq:aggregate_layer} Q(s,a) = V(s) + (A(s,a) - \frac{1}{|A|} \sum_{a’} A(s,a’)) \end{equation}
อันที่จริงแล้วมันจะทำให้ความสัมพันธ์ระหว่างค่า $Q(s,a)$, $V(s)$ และ $A(s,a)$ มันผิดเพี้ยนไปจากเดิมหน่อย ๆ อย่างไรก็ตามอันดับของค่า $A(s,a)$ ของแต่ละ action มันยังเหมือนเดิมอยู่ มันก็ทำให้ค่า $Q(s,a)$ มี rank ที่เหมือนเดิม เราก็เลยใช้ได้
เช่น สมมติว่าถ้าคำนวณค่า $Q(s,a)$ ตามสมการที่ \eqref{eq:aggregate_layer_max} แล้วเราเอาค่า $Q(s,a)$ มาเรียงได้ดังนี้ $Q(s,1) > Q(s,2) > Q(s,3)$ ต่อมาเรามาคำนวณด้วยสมการที่ \eqref{eq:aggregate_layer} ก็ขอแค่ให้ได้ลำดับ $Q(s,1) > Q(s,2) > Q(s,3)$ เหมือนเดิมก็พอ
เพราะที่จริงแล้วเราก็ไม่ได้แคร์ว่าค่า $Q(s,a)$ มันจะเป็นเท่าไหร่ เราแค่เลือกอันที่ดีที่สุดมาทำ ขอแค่อันที่ดีที่สุดที่คำนวณตามสมการ \eqref{eq:aggregate_layer_max} ยังเป็นอันที่ดีที่สุดถ้าคำนวณจากสมการ \eqref{eq:aggregate_layer} ก็เป็นอันใช้ได้
กล่าวโดยสรุปก็คือ ตัว Dueling-DQN นั้น เค้าก็ได้นำเสนอ network architecture ใหม่เท่านั้น ซึ่งจะเห็นได้ว่าตัว input และ output สุดท้ายของ neural network นั้นเหมือนกันกับ DQN หมดทุกอย่าง เพราะฉะนั้นแล้ว การเปลี่ยนจาก DQN มาเป็น Dueling-DQN นั้น เราแค่เปลี่ยนการต่อ neural network เท่านั้นเอง ซึ่งตัวอย่างการการเปลี่ยนโค้ดของการสร้าง neural network จาก DQN มาเป็น Dueling-DQN ก็ง่าย ๆ แค่นี้เอง
### Simple DQN
def build_neural_network_dqn(n_action):
input_layer = Input(shape=(8,)) #input shape เอามาจาก env.observation_space
dense = Dense(100, activation='relu', kernel_initializer='random_normal')(input_layer)
dense = Dense(100, activation='relu', kernel_initializer='random_normal')(dense)
dense = Dense(50, activation='relu', kernel_initializer='random_normal')(dense)
Q = Dense(n_action, activation='linear', kernel_initializer='random_normal')(dense)
model = Model(input_layer,Q)
adam = Adam(learning_rate = 0.001)
model.compile(loss='mean_squared_error', optimizer=adam)
return model
### Simple Dueling DQN
def build_neural_network_dueling_dqn(n_action):
input_layer = Input(shape=(8,)) #input shape เอามาจาก env.observation_space
dense = Dense(100, activation='relu', kernel_initializer='random_normal')(input_layer)
V = Dense(50, activation='relu', kernel_initializer='random_normal')(dense)
V = Dense(1, activation='linear', kernel_initializer='random_normal')(V) # มี 1 node ใช้สำหรับประมาณค่า V(s)
A = Dense(100, activation='relu', kernel_initializer='random_normal')(dense)
A = Dense(n_action, activation='linear', kernel_initializer='random_normal')(A) # มีจำนวน nodes เท่ากับจำนวน actions สำหรับประมาณค่า A(s,a) ของแต่ละ action
Q = V + (A - tf.math.reduce_mean(A, axis=1, keepdims=True)) # สร้าง aggregate layer ด้วยสมการที่ 7
model = Model(input_layer,Q)
adam = Adam(learning_rate = 0.001)
model.compile(loss='mean_squared_error', optimizer=adam)
return model
นอกนั้นในกระบวนการเทรนโมเดลก็ทำเหมือนเดิมหมดทุกอย่าง เช่น การใช้ experience replay, การใช้ target network, ฯลฯ
Experiment
ในเปเปอร์เค้าก็ได้ทดลองเปรียบเทียบ DQN และ Dueling-DQN ใน environment เบสิค ๆ แบบรูปด้านล่าง
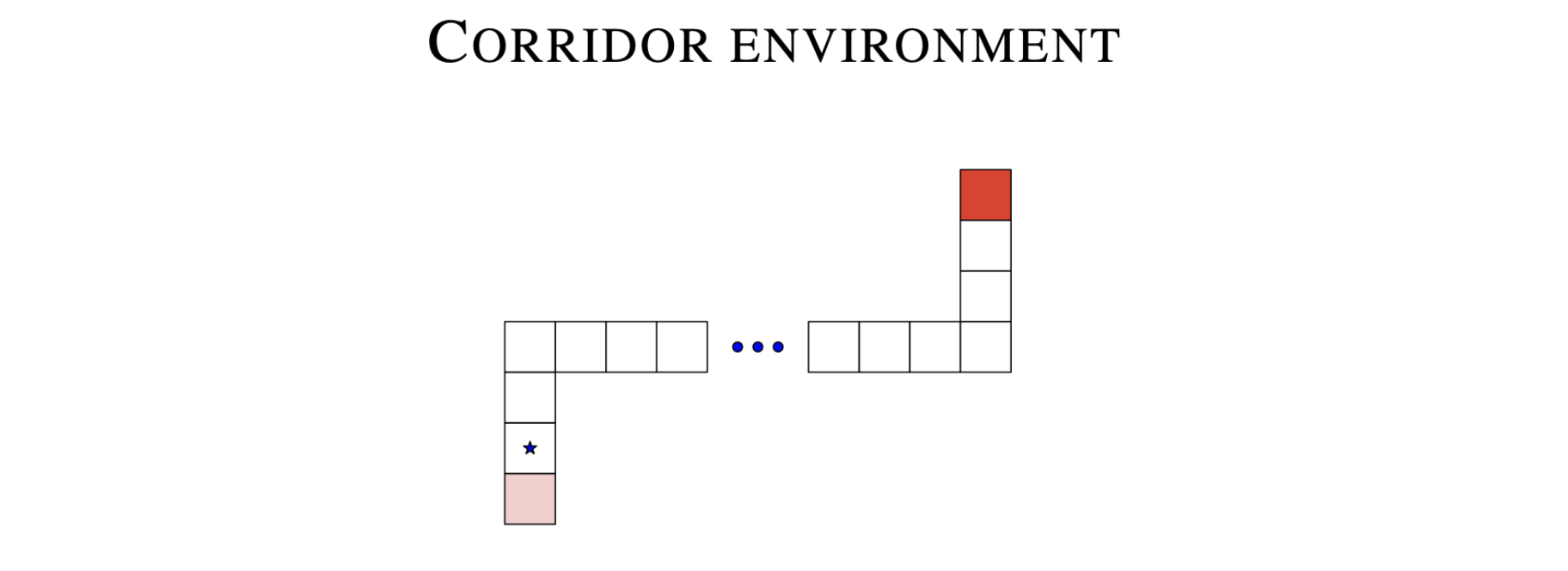
โดยที่ agent นั้นจะเริ่มที่จุด $\star$ และมี action ให้เลือกทำได้แก่ ไปทางซ้าย,ทางขวา,ข้างบน,ข้างล่าง, และอยู่เฉย ๆ โดยที่ episode จะสิ้นสุดต่อเมื่อ agent สามารถไปถึงปลายทางที่มีสีแดงอยู่ได้ โดยที่ความเข้มของสีแดงนั้นแสดงถึงจำนวน reward ที่จะได้รับเมื่อจบ episode
ซึ่งด้วยความที่ environment มันค่อนข้างง่าย เค้าก็เลยสามารถคำนวณค่า $Q^\ast(s,a)$ ที่ถูกต้องไว้ได้ก่อนหน้า (ถ้าใคร งงๆ ว่าเค้าหาค่า $Q^\ast(s,a)$ ยังไงก็กลับไปทวนเรื่อง Q learning ได้นะ)
จากนั้นเค้าลองเทรนทั้ง DQN และ Dueling DQN กับ environment นี้ และในระหว่างที่เทรน เค้าก็หา squared error ระหว่าง $\hat{Q}(s,a)$ กับ $Q^\ast(s,a)$ ไปด้วยระหว่างเทรนเพื่อดูว่าตัว algorithm นั้นสามารถทำนายค่า Q ได้แม่นยำเท่าไหร่
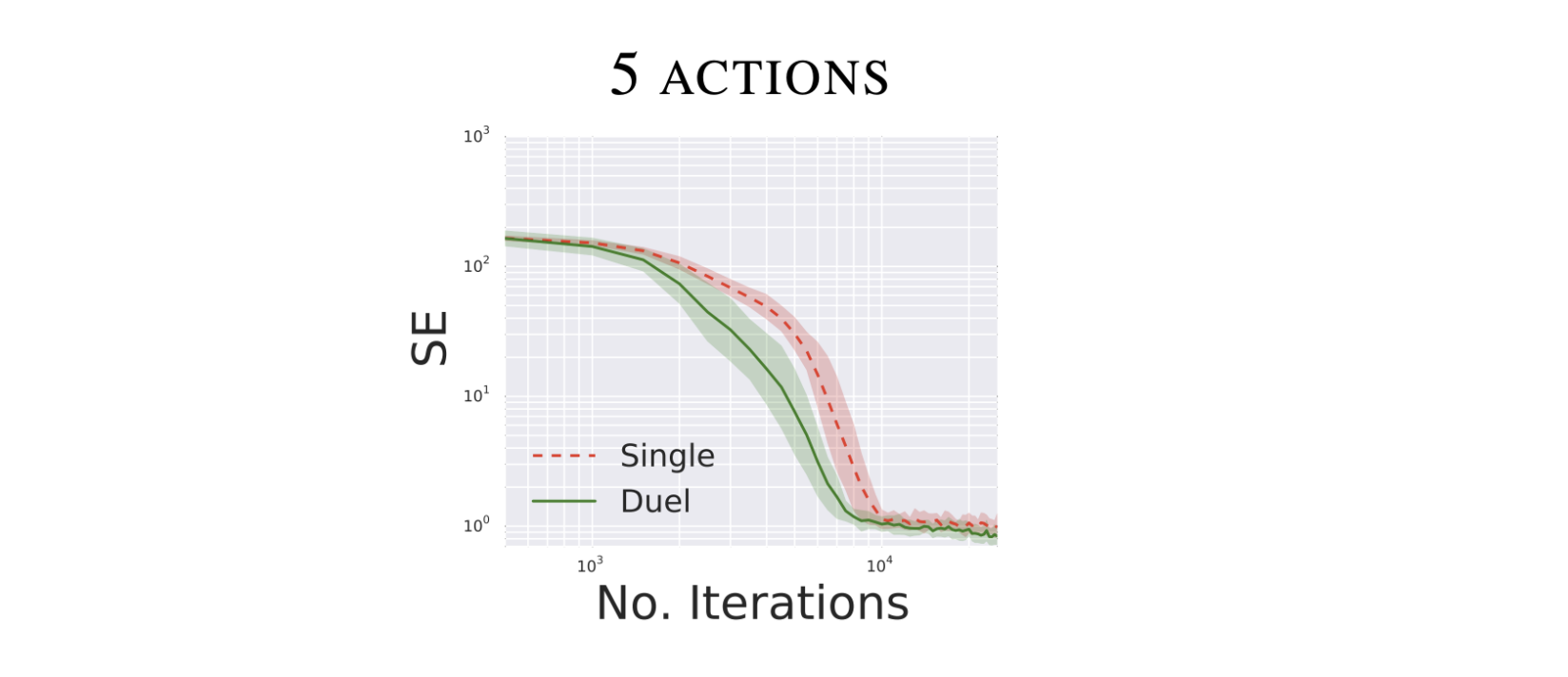
การทดลองแรก
- agent มี 5 actions ด้วยกัน ได้แก่ ไปทางซ้าย,ทางขวา,ข้างบน,ข้างล่าง, และอยู่เฉย ๆ
- พบว่าตัว dueling dqn สามารถทำนายค่า Q ที่แม่นยำได้เร็วกว่า dqn ธรรมดาเล็กน้อย
การทดลองที่ 2
- agent มี 10 actions ด้วยกัน ได้แก่ ไปทางซ้าย,ทางขวา,ข้างบน,ข้างล่าง อย่างละ 1 action และเพิ่ม action การอยู่เฉย ๆ เข้าไป (เพิ่ม action ซ้ำ ๆ เข้าไปน่ะแหละ)
- เราจะพบว่าความแตกต่างระหว่างประสิทธิภาพของ dueling dqn กับ dqn นั้นจะเห็นชัดมากขึ้น ซึ่งก็เป็นเพราะว่า dueling dqn นั้นสามารถอัพเดทค่า $V(s)$ แยกออกมาซึ่งค่า $V(s)$ นี้มันถูกใช้ร่วมกันเพื่อคำนวณค่า $Q(s,อยู่เฉยๆ)$ จำนวนหลาย ๆ ค่า
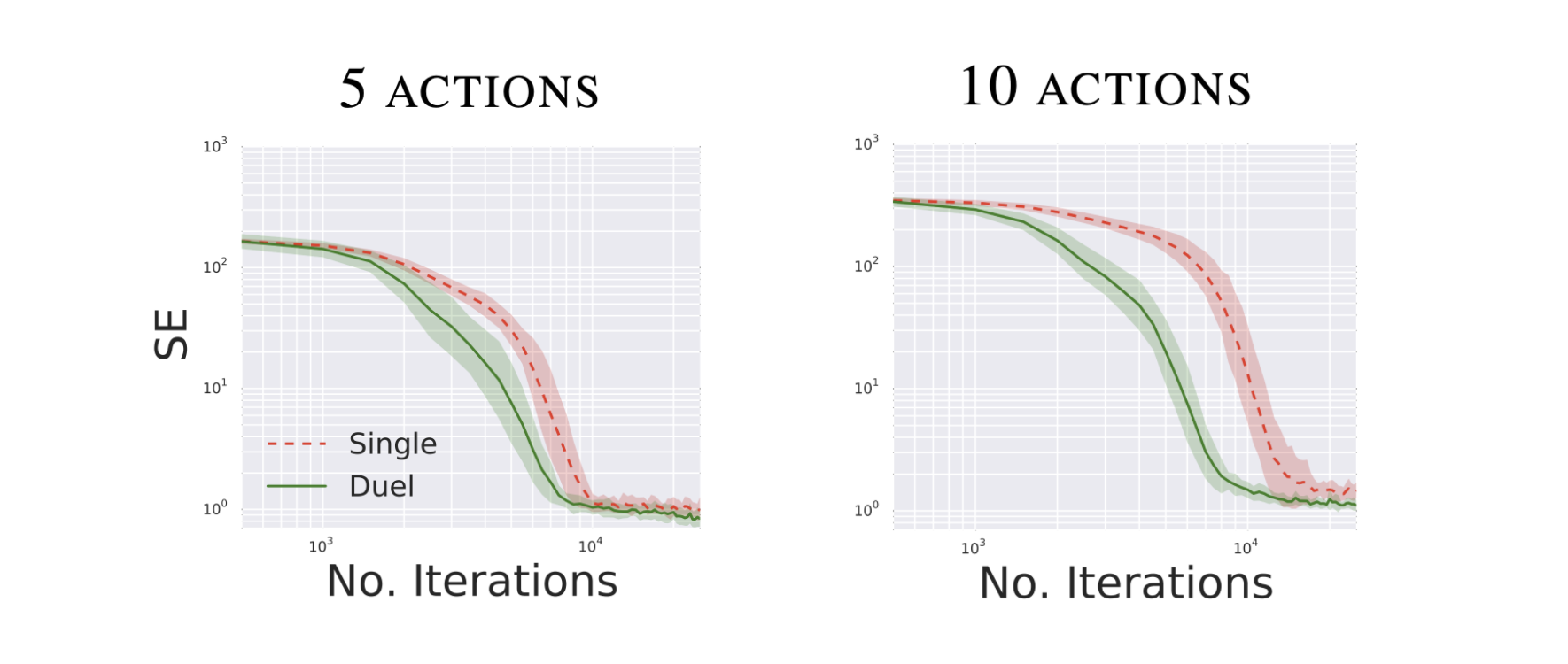
จะเห็นได้ว่า dueling dqn นั้นจะมีประโยชน์มาก ๆ เมื่อเราอยู่ใน environment ที่มี action ที่คล้าย ๆ กัน ในบาง state (แต่ที่จริงแล้วในกรณีนี้คือทุก state เลย)
Disclaimer
รายละเอียดในบทความนี้มาจากความเข้าใจส่วนตัว อาจมีข้อผิดพลาด หากพบจุดผิดพลาด ขอความกรุณาแจ้งทาง facebook หรือ email: thammasorn.han@hotmail.com