List of Variable and Function
- \(s_t\) = state ณ เวลา \(t\)
- \(a_t\) = action ณ เวลา \(t\)
- \(r_t\) = reward ที่ได้จากการทำ \(a_t\) ใน \(s_t\)
- \(\gamma\) = reward discount factor เอาไว้ควบคุมความสำคัญของ reward ในอนาคต
- \(a^\ast\) = optimal action
- \(\pi\) = Policy function เป็นฟังก์ชันที่จับคู่ระหว่าง state กับ optimal action หรือ \(a^{\ast}_t = \pi(s_t)\)
- \(\alpha\) = learning rate
- \(\mathbb{E} [y \vert x=x_1]\) คือค่าประมาณของ \(y\) เมื่อค่าของ \(x\) เท่ากับ \(x_1\)
- \(max_x f(x)\) คือการหาค่า \(f(x)\) ที่มากที่สุดโดยการปรับค่า \(x\)
- \(argmax_x f(x)\) คือการหาค่า \(x\) ที่ทำให้ได้ \(f(x)\) มากที่สุด
Q-learning คืออะไร
ถ้ายังจำกันได้ reinforcement learning คือการสร้าง policy ที่เป็นฟังก์ชันซึ่งจะแมพจาก state ไป action ที่จะทำให้เราได้ reward มากที่สุดในระยะยาว ถ้าเขียนเป็นรูปแบบทางคณิตศาสตร์ก็จะเป็นแบบนี้
\begin{equation} \label{eq:eq_1} a^\ast_t = \pi(s_t) \end{equation}
โดยที่ใน Q learning เนี่ย เป็น value-based reinforcement learning ชนิดหนึ่ง ซึ่งจะสร้าง policy ด้วยการประมาณค่า reward ระยะยาวที่จะได้จากการทำแต่ละ action ในแต่ละ state หรือ \(Q(s,a)\) value ก่อน แล้วเราค่อยสร้าง policy จากค่า \(Q(s,a)\) ที่เราประมาณไว้
\begin{equation} \label{eq:eq_2} Q(s_t,a_t) = \mathbb{E}[r_t + \gamma^1r_{t+1}+ \gamma^2r_{t+2}+…|s = s_t, a= a_t] \end{equation}
จะเห็นได้ว่า
- \(Q(s,a)\) คือผลรวมของ reward ทั้งในเวลาปัจจุบัน และในอนาคต
- แต่ reward ในอนาคตจะถูกคูณด้วย \(\gamma\) ยกกำลัง 1 2 3 4 5 6 … ไปเรื่อย ๆ
- ค่า \(\gamma\) เป็น parameter ที่ชื่อว่า reward discount factor มีค่าระหว่าง 0–1 อยู่ที่ว่าเราให้ความสำคัญกับ reward ในอนาคตมากแค่ไหน ถ้าเราอยากให้ความสำคัญกับ reward ในอนาคตมากหน่อย เราก็ตั้ง \(\gamma\) ให้เยอะ ๆ ไว้ เช่น 0.9999999
สมมติเรารู้ค่า \(Q(s,a)\) ที่แม่นยำแล้ว เราก็สามารถคิด policy ของการเลือก action ในแต่ละ state ได้แบบง่ายๆเลย ก็คือในแต่ละ state ใด ๆ เราจะเลือก action ที่ให้ค่า \(Q(s_t,a_t)\) มากที่สุด หรือเขียนได้ดังนี้
\begin{equation} \label{eq:eq_3} a^\ast_t = \pi(s_t) = argmax_a (Q(s_t,a)) \end{equation}
วิธีประมาณค่า \(Q(s_t,a_t)\)
ใน section ข้างบนเรารู้แล้วว่าค่า \(Q(s_t,a_t)\) คืออะไร และเราสามารถนำไป optimize ค่า long-term reward ได้ยังไง เพราะฉะนั้นในส่วนนี้เราจะอธิบายวิธีการคำนวณค่า Q ที่แม่นยำเด้อ
จากสมการที่ \eqref{eq:eq_2} และ \eqref{eq:eq_3} ทำให้เราสามารถเขียนค่า \(Q(s_t,a_t)\) ได้ในอีกรูปแบบหนึ่งโดยใช้หลักการง่าย ๆ คือ เราจะแทนค่า reward ในอนาคตหรือ \(\gamma^1r_{t+1}+ \gamma^2r_{t+2}+…\) ด้วย ค่า Q ของ optimal action ใน state ถัดไปหรือ \(\gamma Q(s_{t+1},a^\ast)\) ทำให้เราได้สมการด้านล่าง ซึ่งมีชื่อว่า Bellman Equation
ซึ่งเราสามารถ
\begin{equation} \label{eq:eq_4} Q(s_t,a_t) = r_t + \gamma max_a Q(s_{t+1},a) =r_t + \gamma Q(s_{t+1},a^\ast) \end{equation}
เพื่อความเข้าใจง่าย เราสามารถกระจายสมการด้านบนเป็นดังรูปด้านล่างได้
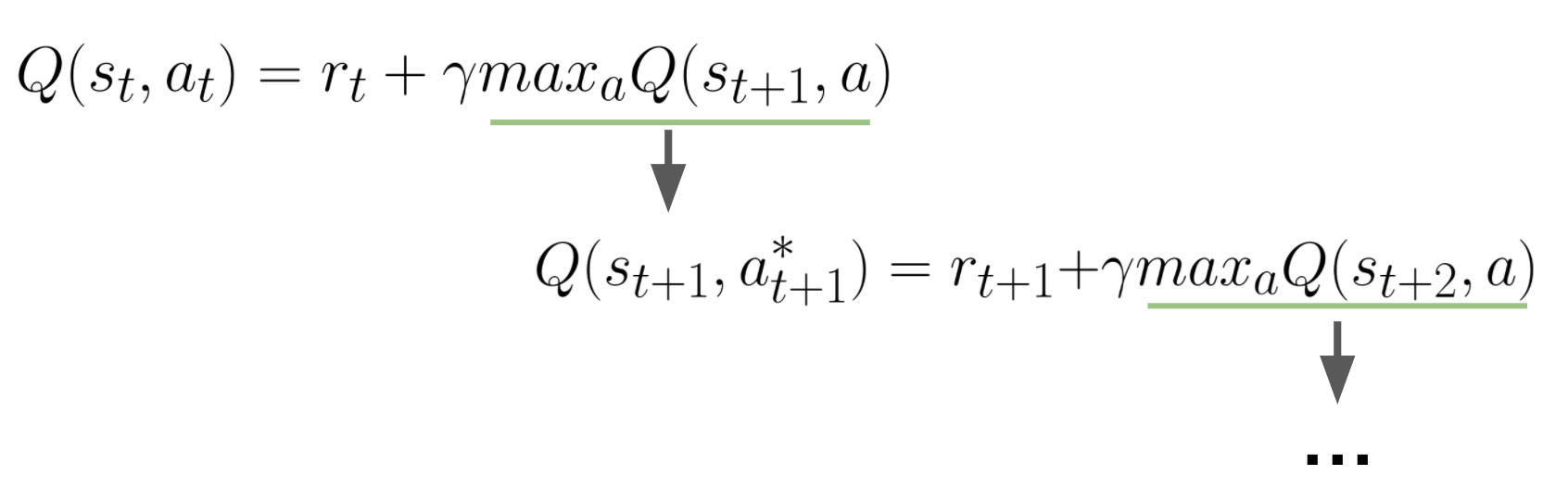
จะเห็นได้ว่าในสมการด้านบนนั้น การที่เราจะประมาณค่า Q ได้ เราต้องมีตัวแปรอย่างน้อย 4 ตัว ก็คือ
- \(s_t\) = state ปัจจุบัน
- \(a_t\) = action ปัจจุบัน
- \(r_t\) = reward ปัจจุบัน
- \(s_{t+1}\) = state ในเวลาถัดไป
ในการฝึก agent ให้ประมาณค่า Q ได้นั้น ในตอนแรกเราจะตั้งค่า Q ขึ้นมามั่ว ๆ ก่อน จากนั้นเราจะให้ agent ได้ลองผิดลองถูกใน environment ที่กำหนดให้ไปเรื่อย ๆ และในแต่ละ timestep นั้น มันจะเก็บ experience ที่ประกอบไปด้วยตัวแปร 4 ตัวด้านบนมาเพื่ออัพเดทค่า Q ของแต่ละ state และ action ไปเรื่อย ๆ จนกว่าค่า Q ของแต่ละ state และ action นั้นจะลู่เข้าสู่ค่าใดค่าหนึ่ง
ขั้นตอนโดยละเอียดมีดังนี้

- สร้างตารางเอาไว้เก็บค่า \(Q(s,a)\) ของทุก state-action โดยที่ตารางนั้นจะมีจำนวน row เท่ากับจำนวน state และจำนวน column เท่ากับจำนวน action
- สุ่มค่า Q มั่ว ๆ ใส่ในตารางไปก่อน หรือจะเริ่มด้วย 0 อะไรงี้ก็ได้
- จากนั้นให้ agent เราได้โลดแล่นอยู่ใน environment โดยส่วนใหญ่ขั้นตอนนี้จะถูกแบ่งออกเป็น episode โดยที่ในแต่ละ episode จะมีขั้นตอนดังนี้
- รับค่า state ปัจจุบันมาจาก environment
- เลือก action ด้วยการใช้ policy ในสมการที่ \eqref{eq:eq_3} และ epsilon-greedy
- Epsilon-Greedy เป็นการสำรวจ environment กล่าวคือเราจะเลือก action แบบสุ่มด้วยความน่าจะเป็น \(\epsilon\) และเลือก action ที่ดีที่สุดตาม policy ด้วยความน่าจะเป็น \(1-\epsilon\)
- โดยที่ค่า \(\epsilon\) นั้นตอนแรกจะถูกตั้งไว้สูง ๆ ก่อน ก็คือประมาณ 1 และค่อย ๆ ลดลงมาเมื่อ train ไปเรื่อย ๆ
- สาเหตุที่เราต้องใช้ epsilon-greedy ก็เพราะว่าเราต้องการให้ agent เราได้รู้จักกับ environment ให้ได้กว้าง ๆ เผื่อจะค้นพบ policy ที่ดีที่สุดจริง ๆ คือสมมติว่าเรามัวแต่เลือก action ที่เราคิดในตอนนี้ว่ามันดีที่สุดแล้ว เราก็จะไม่เคยได้ไปทดลองในทางอื่นเลย และจะไม่มีทางรู้ได้ว่า policy ที่เรามีอยู่ตอนนี้มันดีที่สุดจริง ๆ แล้วหรือยัง
- ทำ action ที่เลือกในขั้นตอนที่แล้วใส่ environment และเก็บ reward และ state ถัดไป
- อัพเดทค่า Q ด้วยสมการด้านล่าง
\begin{equation}
\label{eq:eq_5}
Q(s_t,a_t) = Q(s_t,a_t) + \alpha (r_t + max_aQ(s_{t+1},a) - Q(s_t,a_t))
\end{equation}
- จะเห็นได้ว่าเทอม \((r_t + max_aQ(s_{t+1},a) - Q(s_t,a_t))\) เป็นการคำนวณ error ระหว่างค่า target หรือเทอม \(r_t + max_aQ(s_{t+1},a)\) และค่า \(Q(s_t,a_t)\) ที่อยู่ในตาราง
- Error นี้มีชื่อว่า Temporal-Difference Error หรือย่อว่า TD Error
- ในการคำนวณนั้น เราเลือกค่า \(max_aQ(s_{t+1},a)\) จากตารางได้เลย
- จากนั้นนำค่า error มาอัพเดทค่า Q ที่อยู่ในตาราง ด้วยการคูณกับ learning rate หรือ \(\alpha\) และบวกเข้าไปที่ค่า \(Q(s_t,a_t)\) เดิม
- ก๊อป \(s_{t+1}\) มายัง \(s_{t}\) เพื่อเป็นการก้าวสู่ step ถัดไป และวนไปเรื่อย ๆ จนกว่า episode จะสิ้นสุด ซึ่งถ้าเทียบกับเกมก็คือจนกว่าตัวละครจะตาย/ตกน้ำ/แพ้/ชนะ
Implementation
ในบทความนี้จะยกตัวอย่างการสร้าง agent ให้เดินจากจุดหนึ่งไปอีกจุดหนึ่งได้โดยไม่ตกน้ำด้วยการใช้ Q learning นะครับ โดยที่เราจะใช้ภาษา python ในการทดลอง ซึ่งจะใช้ library หลัก ๆ ดังนี้ครับ
- Numpy: เป็น library ที่เอาไว้ใช้คำนวณ matrix คำสั่งคล้าย ๆ matlab
- Gym: เป็น library ที่ provide environment ต่าง ๆ ตั้งแต่เขาวงกตง่าย ๆ ไปยันเกมต่าง ๆ ซึ่งเราสามารถนำมาใช้ทดลอง reinforcement algorithm
ถ้าใครไม่มี python ในเครื่อง ไม่สะดวกลง แนะนำให้ใช้ google colab แทนนะครับ
Environment
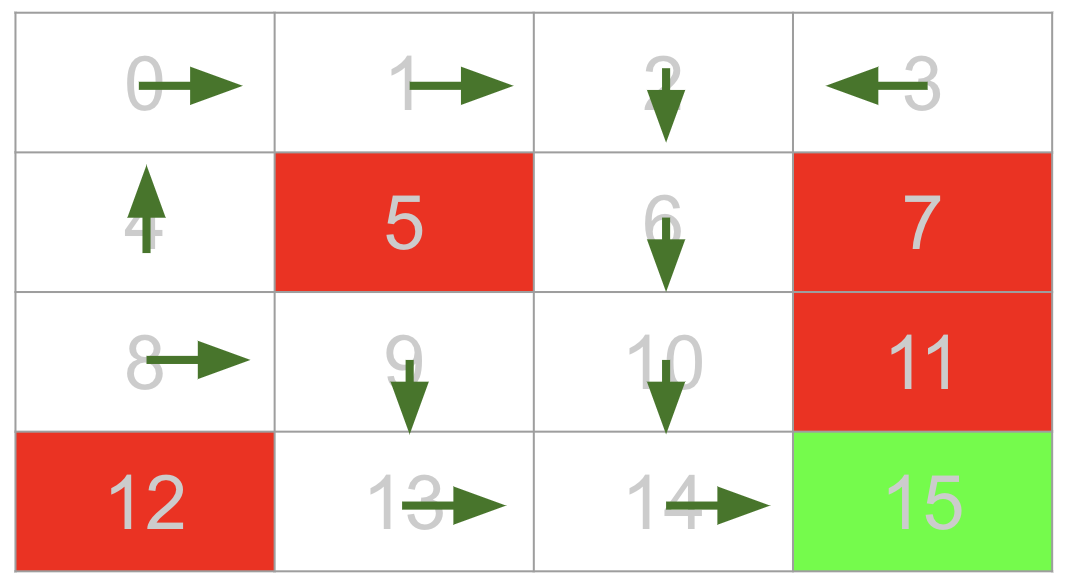
ก่อนที่จะเริ่มทำ Q-learning ขออธิบาย environment ก่อน โดยที่ environment ที่เราจะใช้ในบทความนี้มีชื่อว่า FrozenLake-V0 ซึ่งโจทย์ของ environment นี้คือให้เราเดินจากจุด start ไปยังจุดหมายปลายทางให้ได้ โดยที่ระหว่างทางจะมีบ่อน้ำอยู่ โดยที่แต่ละ episode นั้นจะสิ้นสุดเมื่อหุ่นยนต์เราตกน้ำหรือไปถึงจุดหมายปลายทาง
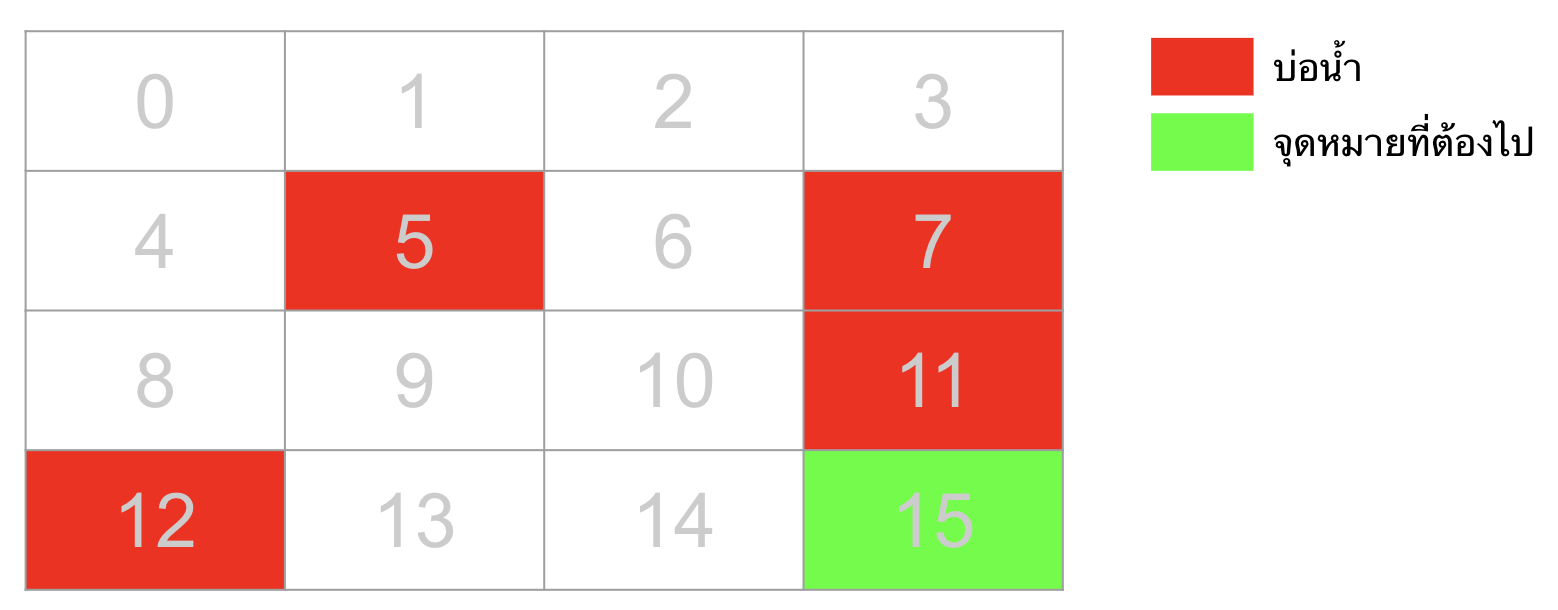
- State: ตำแหน่งปัจจุบันของหุ่นยนต์ (เลข 0-15)
- Action: เลข 0-3 แทนทิศทางของการก้าว (0:ซ้าย, 1:ลง, 2:ขวา, 3:บน)
- Reward: ระหว่าง episode จะเป็น 0 ทั้งหมด จะได้ reward 1 ก็ต่อเมื่อจบ episode ด้วยการไปถึงจุดหมายปลายทางเท่านั้น
Coding
ขั้นตอนโดยละเอียดมีดังนี้
-
ต้อง Import library ที่ใช้ก่อน
import numpy as np import gym -
สร้าง Environment แล้วเก็บไว้ในตัวแปร env
env = gym.make('FrozenLake-v0', is_slippery=False) -
สร้างตารางของ random number ที่มีจำนวน row เท่ากับจำนวน state และจำนวน column เท่ากับจำนวน action โดยที่เราสามารถดึงจำนวน state ได้จากคำสั่ง env.observation_space.n และดึงจำนวน action ได้จากคำสั่ง env.action_space.n
Q_table = np.random.rand(env.observation_space.n, env.action_space.n) -
ตั้งค่า parameter ต่าง ๆ
number_of_episodes =1000 epsilon = 1 epsilon_decay_factor = 0.99999 learning_rate = 0.1 reward_discount_factor = 0.99 -
เขียน For loop เพื่อวนให้ agent เราได้เทรนใน environment ตามจำนวน episode ที่เราตั้งไว้
for i in range(number_of_episodes): ## Episodeโดยที่ในแต่ละ Episode เขียน While loop เพื่อวนให้ agent เราได้ interact กับ environment ในแต่ละ timestep โดยที่รูปแบบจะเป็นดังนี้
for i in range(number_of_episodes): state = env.reset() while True: # Interact with the Environment and Update the Q table if done: breakซึ่งใน While loop นั้น
- เราจะให้ agent เราเลือก action ด้วย epsilon-greedy ซึ่งเขียนโค้ดได้ดังนี้
optimal_action = np.argmax(Q_table[state]) random_action = random.randint(0,env.action_space.n-1) action = np.random.choice([random_action,optimal_action],p=[epsilon,1-epsilon])- ให้ agent เดินไปตาม action ที่เลือกมา
next_state,reward,done,_ = env.step(action)- Trick เล็ก ๆ น้อย ๆ เพื่อกระตุ้นให้ agent เราหา path ไปยังจุดหมายได้เร็วขึ้นโดยที่ไม่ตกน้ำคือการลงโทษมัน ถ้ามันตกน้ำเราจะให้ reward เป็น -1
if done and reward == 0: reward = -1- Update ค่า Q ในตารางด้วยสมการ \eqref{eq:eq_5}
target = reward+reward_discount_factor*np.max(Q_table[next_state]) error = target - Q_table[state][action] Q_table[state][action] = Q_table[state][action] + learning_rate*error-
ลดค่า Epsilon ลงด้วยการคูณค่า epsilon กับค่า epsilon_decay_factor
epsilon = epsilon*epsilon_decay_factor
-
สรุปรวม code ทั้งหมดจะประมาณนี้
## สร้าง Environment env = gym.make('FrozenLake-v0', is_slippery=False) ## สร้างตารางที่เก็บค่า Q Q_table = np.random.rand(env.observation_space.n, env.action_space.n) ## ตั้งค่า paramter number_of_episodes =1000 epsilon = 1 epsilon_decay_factor = 0.99999 learning_rate = 0.1 reward_discount_factor = 0.99 ## วน loop ตามจำนวน episode for i in range(number_of_episodes): ## Reset environment เพื่อให้ได้ state แรกมา state = env.reset() while True: ## หา optimal action ของ state ปัจจุบัน ด้วยการพิจารณาจากตาราง Q ในปัจจุบัน optimal_action = np.argmax(Q_table[state]) ## random action random_action = random.randint(0,env.action_space.n-1) ## เลือก action ด้วย epsilon greedy action = np.random.choice([random_action,optimal_action],p=[epsilon,1-epsilon]) ## สั่งให้ agent ก้าวไปตาม action ที่เลือก และเก็บค่า next_state, reward, done มา next_state,reward,done,_ = env.step(action) ## ถ้า episode นี้จบแล้ว แต่ reward เป็น 0 แสดงว่าจบแบบตกน้ำ เราจะลงโทษมันด้วยการปรับเป็น reward -1 if done and reward != 1: reward = -1 ## คำนวณค่า Target Q Value ด้วย bellman equation target = reward+reward_discount_factor*np.max(Q_table[next_state]) ## คำนวณ TD error error = target - Q_table[state][action] ## อัพเดทค่า Q ใน table โดยอัพเดทเฉพาะค่า Q ของ state ปัจจุบันและ action ที่เพิ่งทำไปเท่านั้น Q_table[state][action] = Q_table[state][action] + learning_rate*error ## ลดค่า epsilon epsilon = epsilon*epsilon_decay_factor ## ก๊อป state ในเวลาถัดไปมาเป็น state ปัจจุบัน state = next_state ## ถ้า episode จบแล้ว (done==True) ให้ break While loop ไปสู่ episode ถัดไป if done: break -
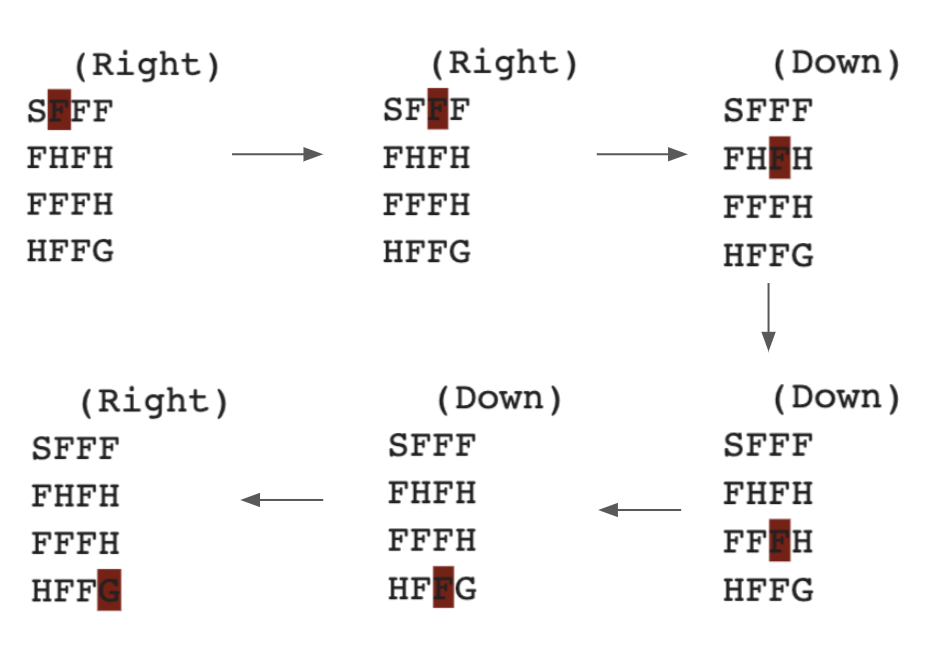
พอเราเทรนเสร็จแล้วเราก็ลองเอามาทดสอบดูว่า agent เราสามารถเดินจากจุดเริ่มไปจุดสุดท้ายได้โดยไม่ตกน้ำหรือยังด้วย code ด้านล่าง ซึ่งก็คล้าย ๆ กับ code ของแต่ละ episode ตอนเทรน แค่ตัดส่วนของการเลือก action ด้วย epsilon-greedy ออก เปลี่ยนไปเลือกแต่ optimal action อย่างเดียว และตัดส่วนของการอัพเดทค่า Q ออกไป
state = env.reset() while True: ## เลือก optimal action ด้วยการดูจากตาราง Q optimal_action = np.argmax(Q_table[state]) ## เดินไปตาม optimal action next_state,reward,done,_ = env.step(optimal_action) ## ก้าวสู่ step ถัดไป ด้วยการก๊อป state ในเวลาถัดไปมาเป็น state ปัจจุบัน state = next_state ## คำสั่งให้แสดงผลว่าตอนนี้ agent เราอยู่จุดไหน และมาจากทางไหน env.render() ## สิ้นสุด episode การเทส if done: breakจะได้ผลลัพธ์ดังนี้ จะเห็นได้ว่า agent เราสามารถเดินไปได้จนถึง Goal แล้ว (ในรูปด้านล่าง F คือพื้นที่เราเหยียบได้/ H คือหลุมหรือบ่อน้ำ/ G คือ goal ที่ต้องไป)
-
หรือจะ print ค่า Q ออกมาดูด้วยคำสั่ง
print (Q_table)จะได้ผลลัพธ์ดังนี้ โดยที่เวลาดูก็ดูเอาว่าแต่ละ row คือ state แต่ละ column คือ action
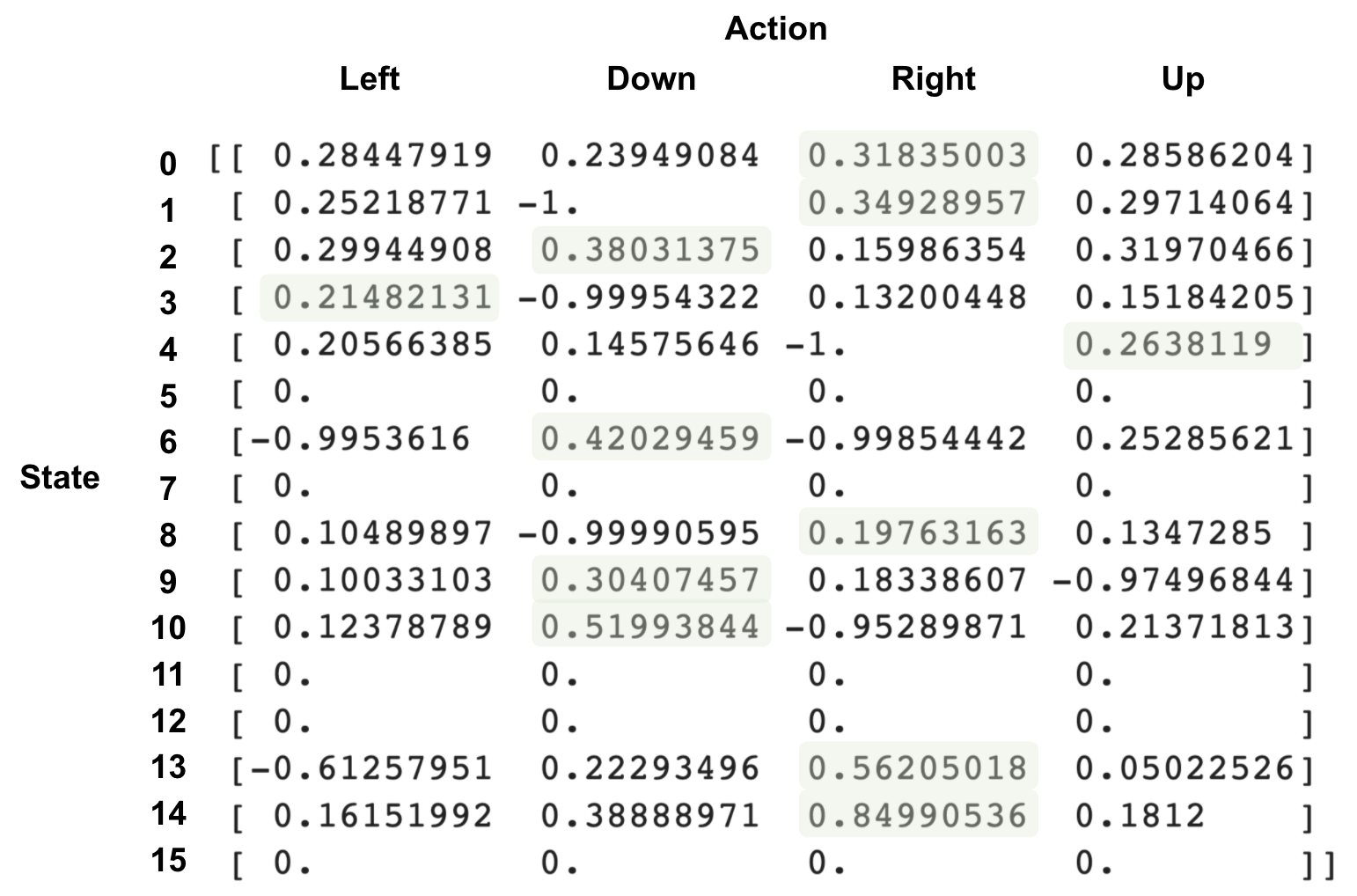
ซึ่งเราสามารถนำมาวาดแผนการเดินของ agent ได้ดังนี้
Reference:
- Introduction to Reinforcement Learning (Richard S. Sutton, Andrew Barto)