List of Variables
- $X$ คือ dataset เช่น ข้อมูล 1000 rows, รูป 10000 รูป, ฯลฯ
- $x$ คือข้อมูลจุดที่เราสนใจ ซึ่งเป็นสมาชิกของ dataset $X$ เช่น ข้อมูล row เดียว, รูป 1 รูป, ฯลฯ
- $f$ คือโมเดลที่เทรนด้วย dataset $X$ ซึ่งเราจะเรียกว่าโมเดลหลัก
- $Z$ คือ fake dataset หรือ perturbed dataset เป็น dataset ที่เรา generate ขึ้นมา
- $z$ คือสมาชิกของ Z
- $x’$ คือ x เวอร์ชันที่ถูก simplify หรือ transform ไปอยู่ในอีกรูปแบบหนึ่ง
- $z’$ คือ z เวอร์ชันที่ถูก simplify หรือ transform ไปอยู่ในอีกรูปแบบหนึ่ง
- $g$ คือ surrogate model หรือ explainer เป็นโมเดลที่เทรนด้วย $Z$ โดยที่ตั้งใจจะให้มันสามารถได้ผลการทำนายได้ใกล้เคียงกับโมเดล $f$ ซึ่งในบทความนี้โมเดล $g$ จะเป็น linear regression
- $\pi_x(z)$ คือฟังก์ชันที่เอาไว้หาค่าความเหมือนกัน (proximity) ของ $x$ และ $z$ เพื่อใช้เป็น weight ในตอนเทรนโมเดล $g$
- $\sigma^2$ คือความกว้าง kernel ใช้ในการคำนวณ $\pi$
Learning Performance vs. Interpretability
ในความเป็นจริงแล้ว โมเดลที่เราแปลความหมายได้ (มี interpretability) กับ โมเดลที่มีความสามารถในการเรียนรู้ complex function มาก ๆ (มี learning performance) นั้นมักจะสวนทางกัน
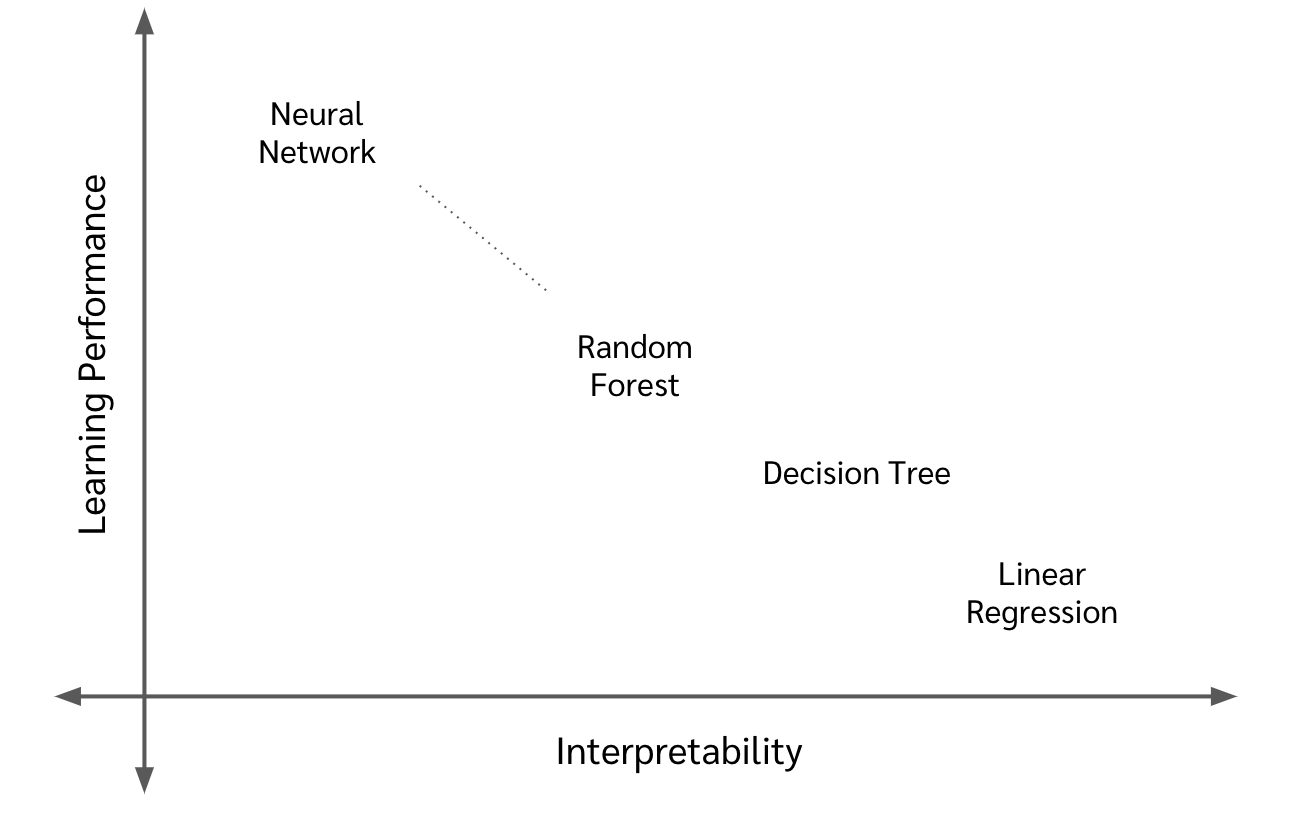
ยกตัวอย่างเช่นใน linear regression คือเราพยายามจะโมเดลข้อมูลด้วยสมการเส้นตรง
\begin{equation} \label{eq:linear_reg} y= \beta_0 + \beta_1 x_1 + \beta_2 x_2 + … + \beta_n x_n \end{equation}
เพราะฉะนั้น ถ้าเราอยากรู้่ว่า effect ของฟีเจอร์ \(x_1\) ต่อผลทำนาย \(y\) เป็นเท่าไหร่ เราก็แค่ดูค่า \(\beta_1\) การที่เป็นแบบนี้คือเราสามารถแปลความหมาย หรือดูพฤติกรรมของโมเดลมันได้ ซึ่งเราทำได้เพราะว่าโมเดลมันเป็นสมการง่าย ๆ
แต่ด้วยความที่มันเป็นสมการง่าย ๆ มันก็ไม่สามารถใช้กับปัญหาที่ complex มากนัก ซึ่งเราก็เลยต้องขยับไปใช้พวกโมเดลที่ complex ขึ้นไป เช่น neural network แต่ว่าใน neural network นั้น เต็มไปด้วยตัวแปร weight และ bias จำนวนมาก การที่เราจะไปไล่แกะสมการของ neural network ออกมาดูมันก็เป็นไปไม่ได้
ทำไมการหาว่า Model คิดอย่างไรถึงสำคัญ ?
-
อาจจะช่วยหา insight ของ business ได้ เช่นถ้าเราสร้างโมเดลทำนายราคาบ้านขึ้นมาด้วยการใช้ neural network ซึ่งสมมติว่าแม่นมาก แล้วเกิดเราอยากรู้ว่าทำไมบ้านแต่ละหลังถึงได้ราคานี้ล่ะ? ฟีเจอร์ใดเป็นส่วนเสริมราคาบ้านและฟีเจอร์ใดเป็นส่วนทำให้ราคาบ้านถูกลง?
-
ช่วยตรวจสอบความน่าเชื่อถือให้กับโมเดลและ dataset
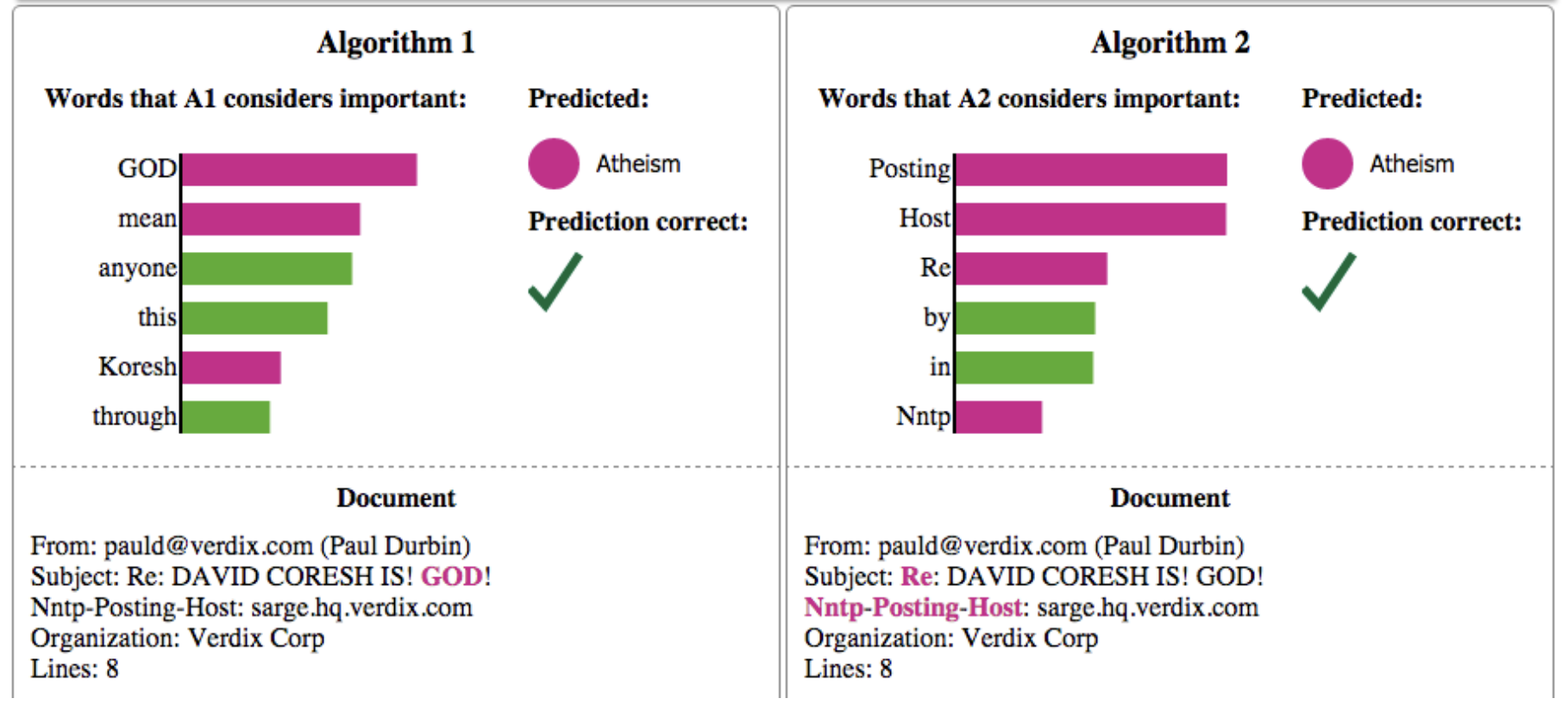 Image Ref: “Why Should I Trust You?”,Explaining the Predictions of Any Classifier
Image Ref: “Why Should I Trust You?”,Explaining the Predictions of Any Classifierยกตัวอย่างดังรูปด้านบน เค้าทำ text classification แบ่งว่า text นั้นเกี่ยวข้องกับ “Christianity” หรือ “Atheism” ผลการเทรนข้อมูลจากสอง model หรือ algorithm นั้นพบว่าค่า accuracy ใน validation set ของ algorithm ที่ 2 นั้นมากกว่า algorithm ที่ 1
แต่ว่าเมื่อเค้าหยิบ text มาอันนึง (instance นึง) มาหาว่าทำไม text นี้ถึงถูกทำนายว่าเกี่ยวกับ “Atheism” ด้วยการใช้ LIME ปรากฎว่า
- algorithm แรกให้ความสนใจไปที่คำว่า {God, mean, anyone, this, koresh, through}
- algorithm ที่สองให้ความสนใจกับคำว่า {Posting, Host, Re, by, in , Nntp}
จะเห็นได้ว่า algorithm แรกนั้นน่าเชื่อถือมากกว่า เนื่องจากคำที่มันสนใจนั้น มีความ make sense กว่า แต่ที่จริงแล้วอีกอย่างนึงที่พบก็คือ dataset นี้มีปัญหา ซึ่งเค้าพบว่าคำว่า Posting นั้นโผล่อยู่ในทั้ง training และ validation set โดยที่ 99% ของ text ที่มีคำว่า Posting นั้น เป็น class “Altheism” โมเดลที่ 2 มันเลย overfit กับคำนี้ไปเลย
LIME คืออะไร?
LIME ย่อมาจาก Local Interpretable Model-agnostic Explanations ซึ่งหมายความว่า
-
Local ซึ่งหมายความว่า LIME เป็นวิธีในการหา contribution ของแต่ละ feature บนผลการทำนายของ instance เดียว (หรือก็คือข้อมูล row เดียว/ รูปเดียว/ ฯลฯ) เช่น ทำไมบ้านหลังนี้ถึงราคาเท่านี้? ทำไม text ที่ให้มาถึงเป็น positive? ทำไมรูปนี้ถึงเป็นรูปหมา? โดยจะทำการหาว่าฟีเจอร์ใด ส่งผลต่อผลการทำนายเท่าใดบ้าง ซึ่งจะแตกต่างกับวิธี PDP หรือ ICE plot ที่เราดูภาพโดยรวมทั้งโมเดลว่าแต่ละฟีเจอร์มีผลต่อผลการทำนายของทั้ง dataset อย่างไรบ้าง
-
Interpretable ก็แปลตรงตัวเลยคือ LIME เป็นวิธีในการแปลพฤติกรรมของโมเดลที่เข้าใจยาก ๆ ออกมาให้คนปกติอย่างเรา ๆ สามารถเข้าใจได้
-
Model-Agnostic หมายความว่าวิธี LIME นั้น สามารถใช้ได้กับทุก model ไม่ว่า model นั้นจะเป็นพวก model ที่สามารถอ่านพฤติกรรมมันได้ (เช่น linear regression, decision tree) หรือ model นั้นจะ complex มากจนเราไม่รู้พฤติกรรมข้างในของมัน (เช่น neural network) ซึ่งก็คือเราสามารถมองโมเดลที่เราใช้เป็น black-box ได้เลย
ซึ่ง LIME นี้ คนออกแบบเค้าออกแบบมาให้ใช้ได้กับทั้งข้อมูลแบบ table, text, แล้วก็ image เลยทีเดียวเชียว
Concept ของ LIME
แนวคิดของ LIME คือแนวคิดของ surrogate model ซึ่งเป็นการใช้ model อื่นที่เบสิคและสามารถแปลความได้ (เช่น linear regression) มาช่วยอธิบายผลการทำนายในบริเวณของข้อมูลที่เราสนใจ แทนที่จะไปนั่งหาว่า model เราทั้งหมดคิดยังไง
model ที่เบสิคที่ใช้ในการแปลความเราเรียกว่า explainer
ยกตัวอย่างดังรูปด้านล่าง
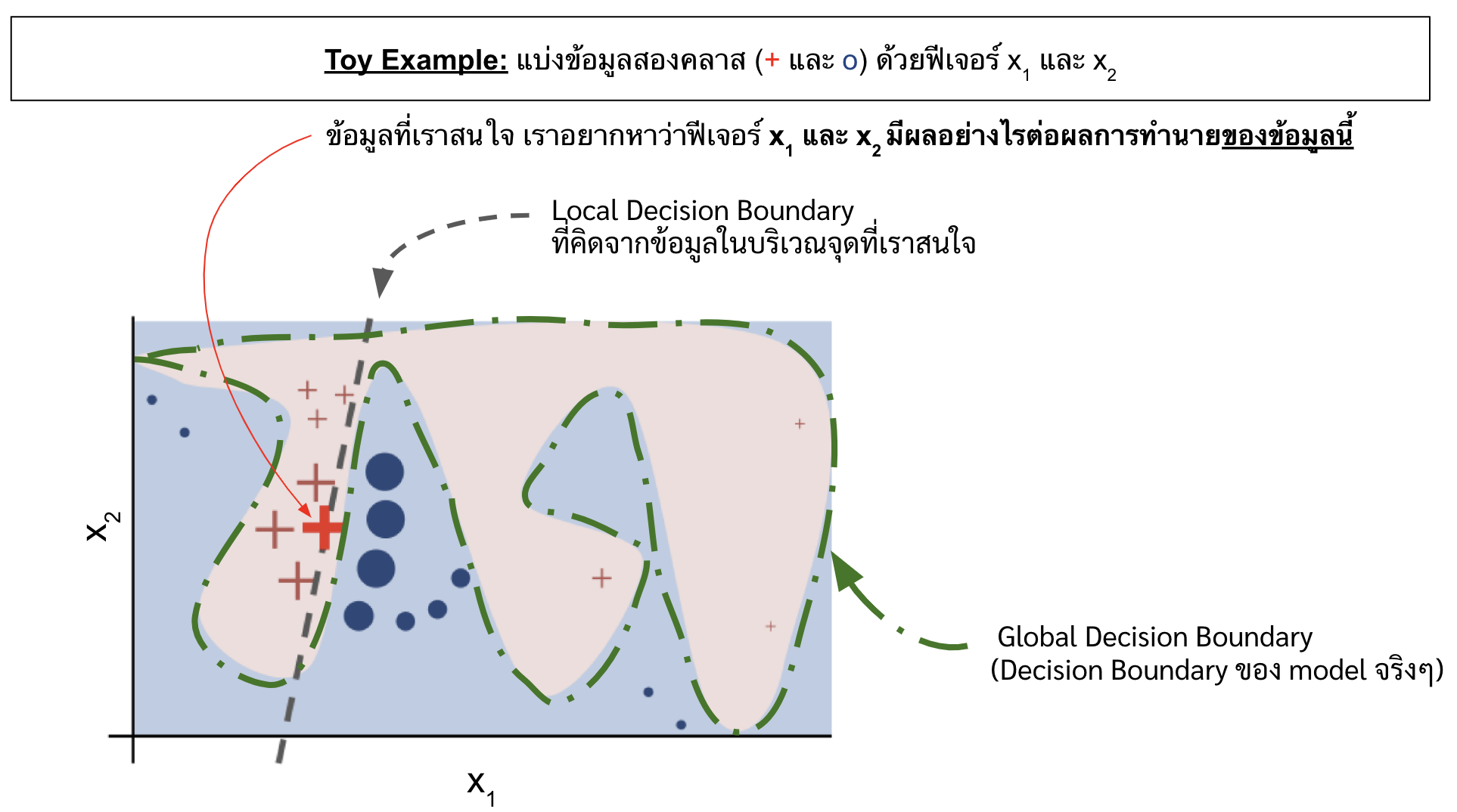 Image Ref: “Why Should I Trust You?”,Explaining the Predictions of Any Classifier
Image Ref: “Why Should I Trust You?”,Explaining the Predictions of Any Classifier
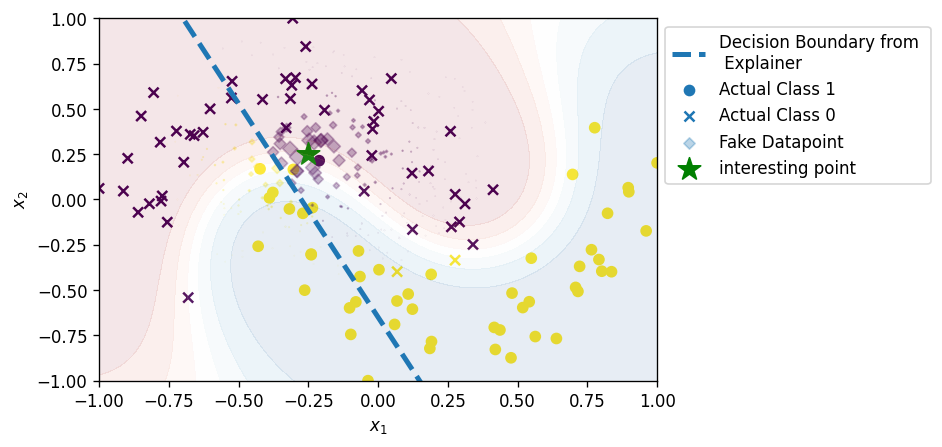
ดังรูป สมมติเราใช้ neural network ในการแยกคลาส + กับคลาส o ออกจากกันด้วยฟีเจอร์ \(x_1\) และ \(x_2\) ต่อมาเราเกิดอยากรู้ว่าที่จุด + (ตัวหนา) นั้น ทำไมถึงถูกทำนายออกมาเป็น class + ได้ (อยากรู้ว่า \(x_1\) และ \(x_2\) ส่งผลอย่างไร ต่อ probability ในการเป็น class +)
คือถ้าเราอยากรู้แค่การอธิบายบนจุดนั้น เราก็ไม่จำเป็นต้องไปนั่งไล่แกะ complex function ใน neural network ให้เวียนหัวกัน (ซึ่งจริง ๆ มันก็ไม่น่ามีใครทำนะ) แต่ว่าเราสามารถพุ่งเป้าในการวิเคราะห์ไปที่จุดนั้น และข้อมูลที่ใกล้เคียงจุดนั้น ๆ และสร้าง explainer มา classify ข้อมูลในละแวกนั้นก็พอ ซึ่งจะเห็นจากรูปด้านบนว่า explainer เราสร้าง boundary decsion ใหม่ที่เป็นเส้นตรงธรรมดาขึ้นมาเส้นนึง ในขณะที่จริง ๆ แล้ว boundary decision ของโมเดลเรามันยึกยือกว่านั้น (เส้นสีเขียว) ซึ่งเราไม่ได้แคร์ว่าเส้นยึกยือทั้งหมดนั้นจะเป็นยังไง เราแคร์แค่ ณ จุดที่เราสนใจ มันเป็นยังไง
เพราะฉะนั้นแล้ว เวลาเราดูผลจาก LIME เราต้องพึงระลึกเสมอว่า พวก contribution ของฟีเจอร์ที่เราเห็นนั้น มันเป็นแค่ local หรือของข้อมูลในแถบนั้น ไม่ใช่ของทั้ง dataset
โดยที่ในการเทรน Explainer นั้น (อย่าลืมว่า explainer ก็เป็น machine learning model เหมือนกัน และเราก็ต้องเทรนเหมือนกัน) เราจะ weight ข้อมูลแต่ละจุดด้วยค่าความเหมือนกัน (proximity) ของ sample นั้น ๆ กับข้อมูลจุดที่เราสนใจ อย่างเช่นรูปด้านบนนั้น ขนาดของ + และ o บ่งบอกถึง weight ของข้อมูลนั้น ๆ ในการเทรน explainer จะเห็นได้ว่าจุดที่อยู่ใกล้จะมีขนาดใหญ่ กว่าจุดที่อยู่ไกล ซึ่งหมายความว่ายิ่ง sample มีความใกล้เคียงกับข้อมูลที่เราสนใจมากเท่าไหร่ เรายิ่งให้ความสำคัญมันมากเท่านั้น
*** ส่วนด้านล่างนี้ ถ้าอยากข้าม ก็ข้ามไปเลยก็ได้ อ่านอีกที section ขั้นตอนของ LIME เลย
ซึ่งถ้าเราเขียน objective ของ LIME ให้อยู่ในรูปของสมการจะได้ว่า LIME นั้นต้องการจะ minimize สมการด้านล่าง
\begin{equation} \label{eq:objective} \xi (x) = argmin_{g \in G} \mathcal{L}(f,g,\pi_x) + \Omega(g) \end{equation}
โดยที่
- \(f\) คือ model ที่เราใช้ทำนายจริง ๆ
- \(G\) คือ เดอะแก๊งของ model ที่เราสามารถแปลความได้โดยง่าย เช่น linear regression, decision tree แต่ในเปเปอร์ original เค้าใช้แค่ linear model
- \(g\) คือ explainer หรือโมเดลที่เราใช้หา contribution ของแต่ละฟีเจอร์ต่อผลการทำนาย ซึ่งเราก็เลือกโมเดลมาซักอันนึงจาก \(G\) น่ะแหละ
-
\(\pi_x\) คือ function ที่คำนวณ weight ของแต่ละ sample ซึ่งคิดจากความเหมือนกันของ sample แต่ละจุดที่เราใช้เทรน explainer กับจุดที่เราสนใจ
\begin{equation} \label{eq:pi} \pi_x(z) = \sqrt{e^{-\frac{D(x,z)^2}{\sigma^2}}} \end{equation}
ซึ่งในเปเปอร์เค้าใช้สมการที่ \eqref{eq:pi} คิดค่า weight ของ sample \(z\) โดยที่
- \(x\) คือ datapoint ที่เราสนใจ
- \(D(x,z)\) คือระยะห่างระหว่าง datapoint ที่เราสนใจ \(x\) กับ sample นั้น ๆ \(z\) ซึ่งการคำนวณ distance นี้จะคำนวณด้วยฟังก์ชันอะไรก็ได้ ขึ้นอยู่กับชนิดของ data เช่น เป็น euclidean distance เมื่อข้อมูลเป็นตัวเลข, เป็น cosine distance เมื่อข้อมูลเป็น text
- ยิ่งค่า \(D(x,z)\) มากเท่าไหร่ค่า weight \(\pi_x(z)\) ของ sample นั้น ๆ จะยิ่งน้อยลงเท่านั้น เพราะถือว่ามันอยู่ไกลเกินไปแล้ว เราสนใจเฉพาะ local แถบ ๆ จุด $x$ เท่านั้น
- \(\sigma^2\) คือขนาด kernel ซึ่งก็เป็นตัวแปรที่เราต้องกำหนด
- ยิ่งเยอะจะยิ่งให้ความสำคัญกับ sample ที่อยู่ไกล ๆ มากขึ้น
- ยิ่งน้อยจะยิ่งให้ความสำคัญกับ sample ที่อยู่ใกล้ ๆ มากขึ้น
- \(\Omega(g)\) คือค่าความ complexity ของ g
จากสมการที่ \eqref{eq:objective} นั้น เราสนใจเทอม \(\mathcal{L}(f,g,\pi_x)\) เป็นหลัก ซึ่งมันคือค่าที่ช่วยเราวัดว่าตัว explainer นั้น สามารถให้ผลได้เหมือนกับโมเดลจริง ๆ ที่เราใช้ได้ขนาดไหน
ยิ่ง \(\mathcal{L}(f,g,\pi_x)\) น้อยแสดงว่า ตัว explainer เราสามารถให้ผลการทำนายได้ใกล้เคียงกับโมเดลจริง ๆ ที่เราใช้ ซึ่งก็สามารถ imply ต่อไปได้ว่าการที่เราพยายามหา contribution ของแต่ละฟีเจอร์ต่อผลการทำนายจาก explainer นั้นจะให้ค่า contribution ใกล้เคียงกับที่เราหาได้จากของโมเดลจริง ๆ อย่างไรก็ตาม เราไม่รู้นะว่าค่า contribution ที่คำนวณจากโมเดลจริง ๆ เป็นเท่าไหร่ เพราะมัน complex เกินไป
ซึ่งเราสามารถเขียนสมการของเทอมนี้ออกมาได้ดังนี้
\begin{equation} \label{eq:loss} \mathcal{L}(f,g,\pi_x) = \sum_{z,z’ \in \mathcal{Z}} \pi_x(z) (f(z)-g(z’))^2 \end{equation}
โดยที่
- \(f(z)\) คือผลการทำนายของโมเดลหลักของเรา จาก input sample \(z\)
-
\(g(z')\) คือผลการทำนายของ explainer จาก input sample \(z'\)
ถึงตอนนี้อาจจะงงกันว่า \(f(z)\) แต่ทำไม \(g(z')\) แล้วตัว \('\) มาจากไหน ทำไมเราต้องแยก \(z\) กับ \(z'\) ด้วย?
ที่จริงแล้วตัว input ของ explainer \(z'\) อาจจะอยู่ในรูปแบบที่แตกต่างจากตัว input ของโมเดลหลัก \(z\) เราก็ได้ เพื่อให้เห็นภาพชัดเจนมากขึ้นจะอธิบายเพิ่มเติมใน section การใช้ LIME กับ Image ด้านล่าง
โดยที่วิธี minimize เทอม \(\mathcal{L}(f,g,\pi_x)\) นี้ ก็คือการที่เราจะ train ตัว explainer model \(g\) ให้ทำนายผลการทำนายของโมเดลหลักเรา หรือก็คือ $f(z)$ ด้วยข้อมูล $z$ โดยตอนเทรนนั้น เราจะตั้ง sample weight ของ $z$ แต่ละตัวด้วยค่า $\pi_x(z)$ นั่นเอง
นอกจากนี้ จากสมการที่ \eqref{eq:objective} ถ้าเราคิดดี ๆ จะพบว่าเทอม \(\mathcal{L}(f,g,\pi_x)\) กับ \(\Omega(g)\) มักจะกลับกัน หรือก็คือถ้า \(\mathcal{L}(f,g,\pi_x)\) มีค่ามาก อาจจะเป็นเพราะว่า ตัว explainer \(g\) นั้น มี learning performance ต่ำ ไม่สามารถบิดไปตาม complex function ของตัวโมเดลหลัก \(f\) ได้ แต่ถ้าเราเพิ่ม learning performance มันก็คือการเพิ่ม complexity หรือเทอม \(\Omega(g)\) ไปด้วย
ขั้นตอนของ LIME โดยคร่าว (Toy Problem)
สำหรับโค้ดทั้งหมด สามารถดูได้ที่ link นี้ ครับ
สิ่งที่ต้องมีก่อนเริ่มทำ
- Dataset \(X\)
-
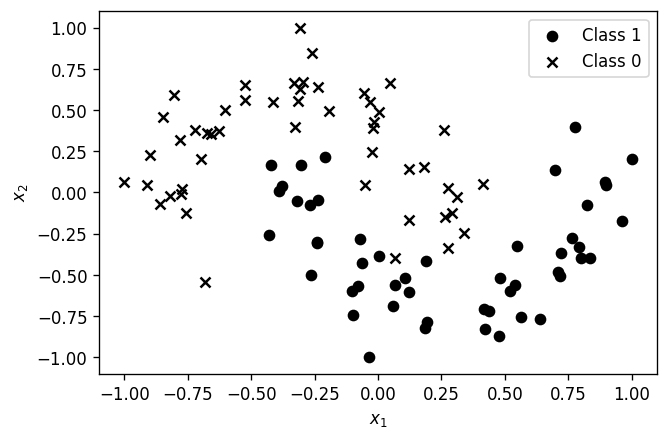
ในที่นี้เราจะใช้ฟังก์ชัน
sklearn.datasets.make_moonsมาสร้าง dataset สำหรับ 2 classes ขึ้นมาfrom sklearn.datasets import make_moons X,y = make_moons(n_samples=100, shuffle=True, noise=0.15, random_state=None) from sklearn.preprocessing import MinMaxScaler X = MinMaxScaler((-1,1)).fit_transform(X)
-
- ML model \(f(x)\) ที่เทรนกับข้อมูล \(X\) มาแล้ว เช่น neural network, SVC, ฯลฯ
-
ในบทความนี้จะขอใช้โมเดล
sklearn.svm.SVCfrom sklearn.svm import SVC svc = SVC(gamma=2, C=1, probability=True) f = svc.fit(X,y)ซึ่งเราจะได้ boundary decision หน้าตาแบบนี้ออกมา (สีของ scatter plot แทนผลการทำนาย สีม่วง class 0, สีเหลือง class 1)
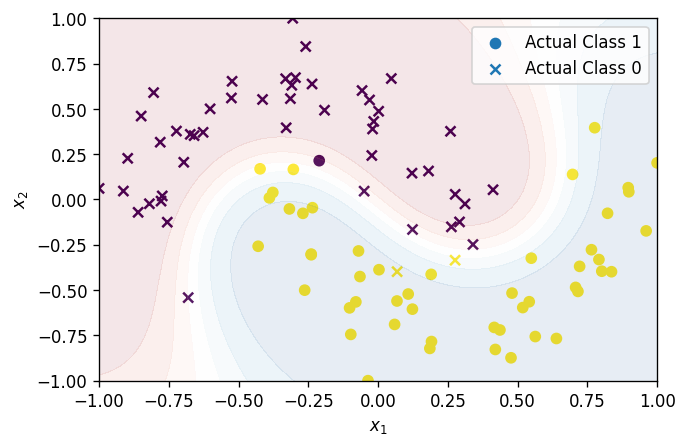
-
- จุดข้อมูลที่เราสนใจ \(x \in X\)
- จะขอเลือกเป็นจุด $(-0.25,0.25)$ แล้วกัน
ที่จริงแล้ว เราควรจะดึงซักจุดมาจาก dataset แต่เพื่อความง่าย เลยขอตั้งขึ้นมาเองนะ
x = [-0.25,0.25]
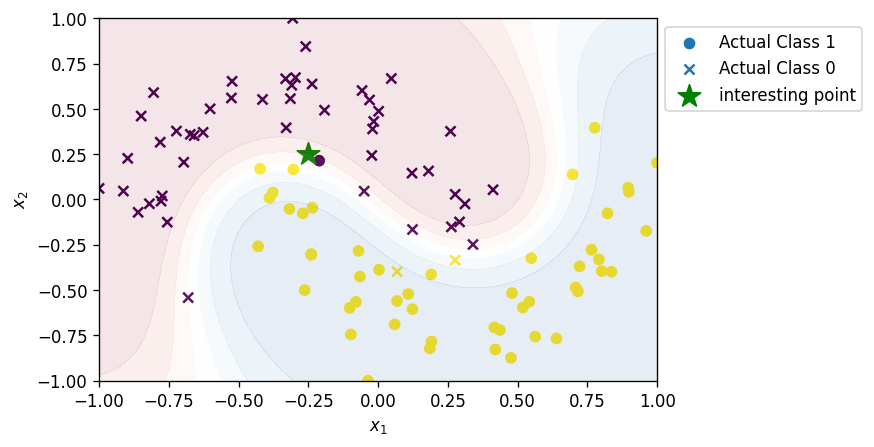
-
ถ้าเราเอา datapoint นี้ไป predict จะพบว่า probability ของ class 1 นั้นคือ 0.28 เดี๋ยวเราจะมากันว่าในเลข 0.28 นี้มี contribution ของ $x1$ และ $x2$ อยู่ประมาณเท่าไหร่
f.predict_proba(np.array([x])) ## Result : array([[0.71393299, 0.28606701]])
- จะขอเลือกเป็นจุด $(-0.25,0.25)$ แล้วกัน
- เลือกประเภทโมเดล \(g\) สำหรับใช้เป็น explainer (ยังไม่ต้องเทรน)
- เราจะเลือกใช้เป็น linear regression
- ออกแบบฟังก์ชัน \(D\) สำหรับคำนวณ distance ระหว่าง 2 datapoints
- เราจะใช้ euclidean distance
ขั้นตอน
- สร้าง fake dataset (บางที่ก็เรียกว่า perturbed dataset) ต่อจากนี้เราจะเรียก dataset นี้ว่า $Z$ และเรียกสมาชิกของ $Z$ ด้วยตัวแปร $z$
number_of_fake_datapoints = 500 Z = np.random.normal(loc=[0,0], scale=0.5 ,size = (number_of_fake_datapoints,2))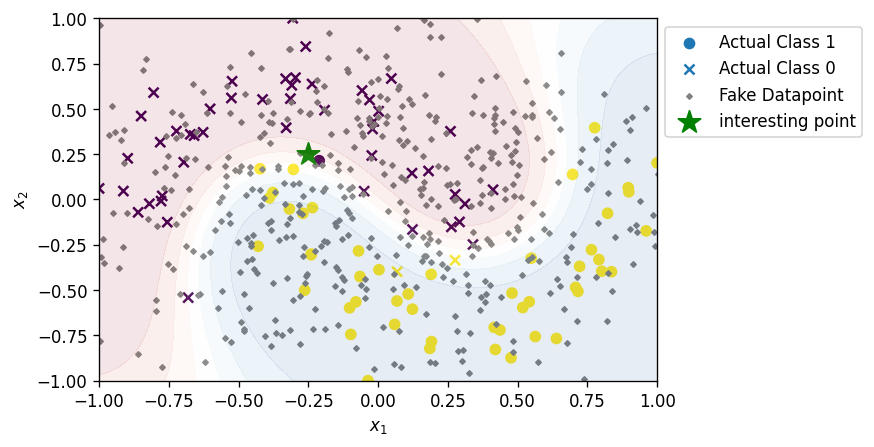
- หา euclidean distance ระหว่าง fake dataset แต่ละจุด ($z$ แต่ละตัว) กับจุดที่เราสนใจ ($x$) และนำมาคำนวณ weight ($\pi$) ด้วยสมการที่ \eqref{eq:pi}
## Calculate Distance dist = np.linalg.norm(Z-np.array([x]), axis=1)#np.sum((Z - np.array(x))**2,axis=1) #np.linalg.norm(Z-np.array([x]), axis=1) ## Calculate Weight kernel_width = 0.1 pi = np.sqrt(np.exp(-((dist ** 2) / kernel_width ** 2)))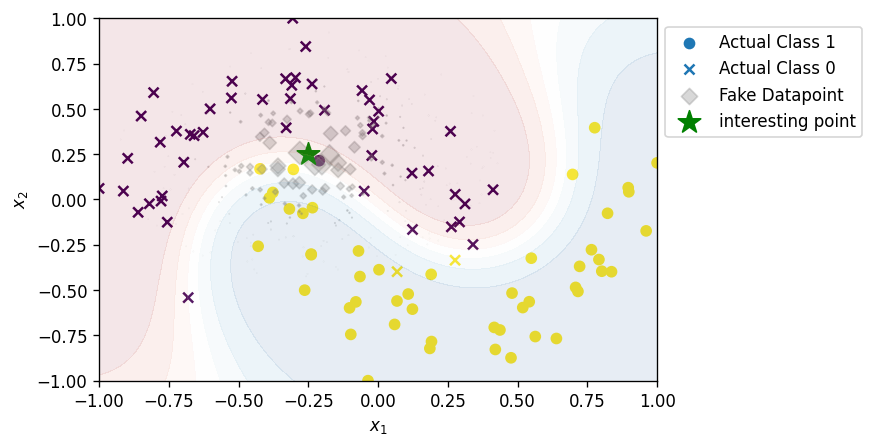
- นำ dataset $Z$ ไป classify ด้วย model หลักของเรา ที่เราเทรนไว้แล้ว แล้วดึง probability ของ class ที่ 1 ออกมา (ขั้นตอนนี้คือการหา $f(z)$)
f_z = f.predict_proba(Z)[:,1] -
สร้าง explainer ด้วยการเทรน Linear regression ด้วยข้อมูล dataset $Z$ และ label $f(z)$ ที่หามาในข้อก่อนหน้า แล้วอย่าลืมตั้ง sample weight เป็น $\pi$ ด้วย
from sklearn.linear_model import LinearRegression lr = LinearRegression(intercept=False) explainer = lr.fit(X=Z, y=f_z, sample_weight=pi.ravel())- แล้วก็ print ตัว coefficient ของ $x_1$ และ $x_2$ ออกมาดู
print ('Coefficient: ', explainer.coef_) # Result Coefficient: [-1.81405856 -0.76955154]
ก็คือเราได้สมการของ linear regression ดังนี้
\begin{equation} \label{eq:reg_toy} probabilty \; of \; class \; 1 = x_1(-1.814) + x_2(-0.7695) \end{equation}
แสดงว่า
- contribution ของฟีเจอร์ $x_1$ ต่อ probability ของ class 1 ณ จุด $(-0.25,0.25)$ เท่ากับ $-0.25 \times -1.814 = +0.4535$
- contribution ของฟีเจอร์ $x_2$ ต่อ probability ของ class 2 ณ จุด $(-0.25,0.25)$ เท่ากับ $0.25 \times -0.7695 = -0.192$
เมื่่อรวม contribution ของทั้ง 2 ฟีเจอร์ เราจะได้ probability ในการเป็น class 1 ของจุด $x$ ที่ประมาณโดย explainer ได้เท่ากับ $0.4535 - 0.192 = 0.2615$ ซึ่งก็ใกล้เคียงกับที่เราหาไว้ตอนแรก
โดยที่เราสามารถพล็อต decision boundary ของ explainer ได้ดังรูปด้านล่าง
วิธีพล็อต decision boundary ก็แค่แก้สมการ $y = x_1(-1.814) + x_2(-0.7695)$ โดยการหาคู่อันดับ $(x_1,x_2)$ ทีทำให้ค่า $y=0.5$
- แล้วก็ print ตัว coefficient ของ $x_1$ และ $x_2$ ออกมาดู
ขั้นตอนของ LIME สำหรับ Image Classification
ที่จริงแล้ว LIME ยังสามารถใช้ได้กับข้อมูลหลากหลายประเภท ในบทความนี้เลยยกตัวอย่างการใช้ LIME กับ image ขึ้นมาด้วย
สิ่งที่ต้องมีก่อนเริ่มทำ
- Dataset \(X\)
- ML model \(f(x)\) ที่เทรนกับข้อมูล \(X\) มาแล้ว เช่น neural network, SVC, ฯลฯ
-
ในบทความนี้จะขอใช้โมเดล Google pre-trained Inception V3 เลยแล้วกัน จะได้ไม่ต้องเทรนใหม่
import keras model = keras.applications.inception_v3.InceptionV3()
-
- จุดข้อมูลที่เราสนใจ \(x \in X\)
-
จะขอเลือกเป็นรูปที่เค้าใช้ในเปเปอร์เลยแล้วกัน
import skimage.io x = skimage.io.imread("dog-guitar.jpg") x = skimage.transform.resize(x, (299,299)) skimage.io.imshow(x)
-
ซึ่งรูปนี้ เมื่อเราเอาไปเข้าโมเดล Inception V3 มันจะบอกว่ารูปนี้คือ acoustic guitar แล้วเดี๋ยวเราจะมาหากันว่า โมเดลมันดูตรงไหนว่าเป็น acoustic guitar
preds = model.predict(x.reshape((1,)+x.shape)) decode_predictions(preds)[0] ### Result # [('n02676566', 'acoustic_guitar', 0.59938663), # ('n02099601', 'golden_retriever', 0.0535729), # ('n03272010', 'electric_guitar', 0.02401211), # ('n02099712', 'Labrador_retriever', 0.022983445), # ('n02787622', 'banjo', 0.0123473685)]
-
- เลือกประเภทโมเดล \(g\) สำหรับใช้เป็น explainer (ยังไม่เทรน) ซึ่งเราจะเลือกใช้เป็น linear regression
- ออกแบบฟังก์ชัน \(D\) สำหรับคำนวณ distance ระหว่าง 2 datapoints
- ใช้ cosine distance ธรรมดา
จะเห็นได้ว่าสิ่งที่เราต้องมีก็เหมือนกับใน Toy problem ด้านบน แต่ว่าเมื่อเราใช้ LIME ใน image classification นั้น สิ่งที่เราต้องมีเพิ่มเติมขึ้นมาคือ
-
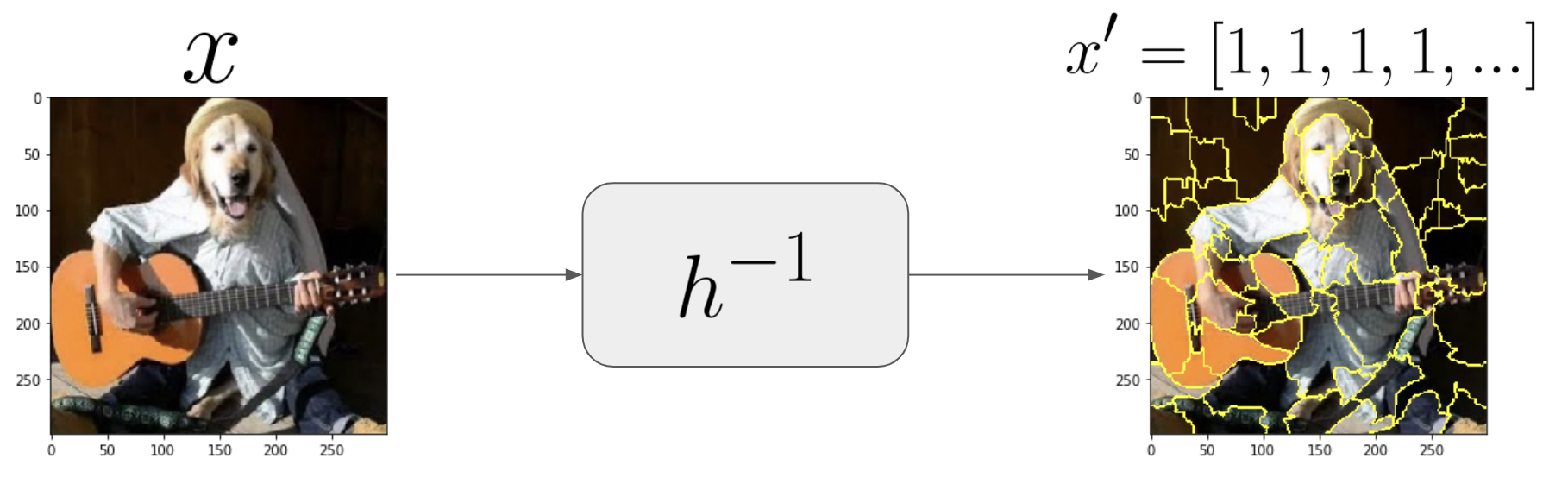
ฟังก์ชัน \(h\) ที่เอาไว้แปลง representation ของฟีเจอร์ จาก input ฟีเจอร์ของ explainer (\(z'\)) ไปเป็น input ของ model หลัก (\(z\)) และฟังก์ชันสำหรับแปลงกลับ
ย้อนไปตอนสมการที่ $\eqref{eq:loss}$ ที่อาจจะมีคนสงสัยกันว่าทำไม input ของ $f$ เป็น $z$ ธรรมดา แต่ทำไม input ของ $g$ เป็น $z’$
เหตุผลก็เพราะว่าในบางกรณีเราต้อง simplify ตัวฟีเจอร์มันก่อนที่จะเอาไปเข้า explainer เราก็เลยแยก $z$ เป็น input ของโมเดลหลักของเรา ส่วน $z’$ เป็น simplified version ของ $z$ อีกที
การที่เราต้อง simplify มันก็เพราะว่า
- ต้องอย่าลืมว่า explainer มันเป็นโมเดลเบสิค ๆ น่ารัก ๆ แล้วเราจะเทรนมันด้วย input ที่มีเป็นล้านฟีเจอร์ เช่น รูป (มีเป็นล้าน pixel) เลย ก็คงลำบาก
- อีกอย่างก็คือ จริง ๆ แล้ว user หรือเรา ๆ เนี่ย ก็คงไม่ได้อยากรู้ไปถึงขนาดว่าแต่ละ pixel มี contribution เท่าไหร่ต่อผลการ classify ของรูปที่กำหนดให้ เราก็คงกรุ๊ป ๆ มันเป็นพาร์ท ๆ ก่อน (เช่นกรุ๊ปเป็น super-pixel) แล้วค่อยหาว่าพาร์ทนี้มี contribution ต่อผลการทำนายรึเปล่า ซึ่งพอกรุ๊ปเป็นพาร์ท ๆ เราก็สามารถ represent มันได้ในอีกรูปแบบหนึ่ง
ซึ่งก็คือเราจะมีฟังก์ชันนึงที่เอาไว้แปลงค่า \(z'\) ไปเป็น \(z\)
\begin{equation} \label{eq:h} z = h(z’) \end{equation}
ซึ่ง function \(h(z')\) นี้ก็จะเปลี่ยนไปตามแต่ประเภทข้อมูล โดยที่ใน image classification นั้น เราจะแบ่งภาพออกเป็นส่วน ๆ แล้ว แปลงจากรูปภาพไปเป็นเวคเตอร์ของ 1 และ 0 โดยที่สมาชิกแต่ละตัวของเวคเตอร์นั้นจะแทนการเปิดปิดภาพส่วนนั้น ๆ ซึ่งเดี๋ยวจะเห็นตัวอย่างในด้านล่าง
ขั้นตอน
- แปลงจุดข้อมูลที่เราสนใจ \(x\) ให้เป็น \(x'\)
- ซึ่งในปัญหาของ image นั้น เราจะทำการ segment รูปตามสี (แบ่ง super-pixel)
from skimage.segmentation import slic,quickshift from skimage.segmentation import mark_boundaries import matplotlib.pyplot as plt segments = quickshift(x, kernel_size=4, max_dist=200, ratio=0.2) skimage.io.imshow(mark_boundaries(x, segments)) number_of_superpixel = np.unique(segments).shape[0] print ('There are {} super-pixels in image'.format(number_of_superpixel)) # 60 super pixels

- แล้วเราก็จะทำการสร้าง array ที่เป็นเลข 1 ทั้งหมด และมีความยาวเท่ากับจำนวน superpixels ในรูป ซึ่งแต่ละตำแหน่งของสมาชิกใน array จะอิงไปแต่ละ super pixel และตัวเลขก็คือแทนการเปิด-ปิดส่วนนั้น ๆ ของภาพ (1 เปิด, 0 ปิด) จะเห็นได้ว่าในรูป \(x\) ของเรานั้น คือรูปเต็ม ๆ ที่สมบูรณ์ ตัว \(x'\) เราเลยเป็น 1 ทั้งหมด
x_dat = np.ones(number_of_superpixel)
- ซึ่งในปัญหาของ image นั้น เราจะทำการ segment รูปตามสี (แบ่ง super-pixel)
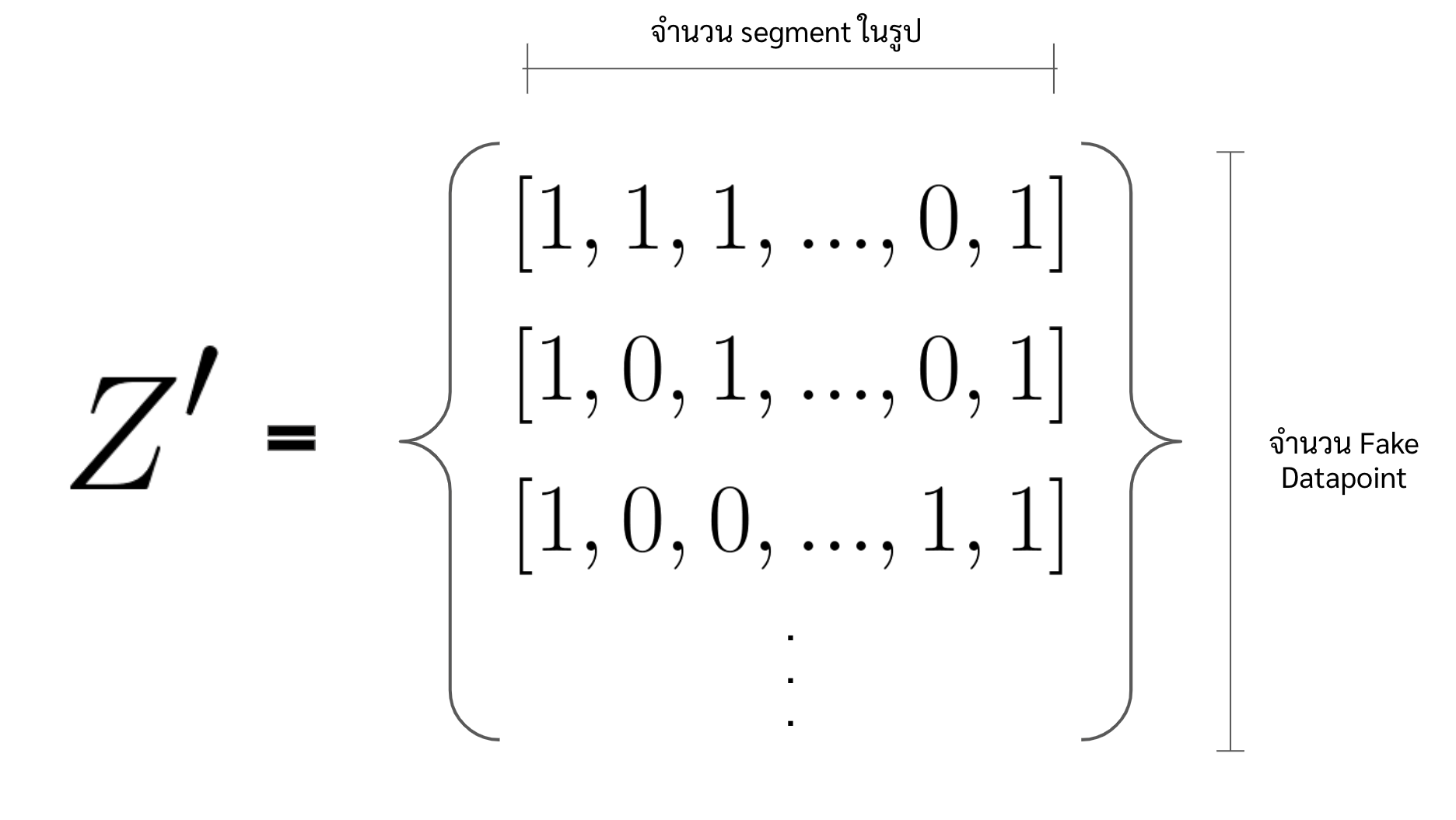
- สร้าง fake dataset หรือ purturbed dataset โดยการ permute ค่าของแต่ละฟีเจอร์ใน \(x'\) ในที่นี้จะขอแทน fake dataset ว่า \(Z'\) และแทน datapoint แต่ละจุดของ \(Z'\) ด้วย \(z'\)
- ซึ่งเราจะทำการสุ่มสร้าง array ที่ประกอบไปด้วย 0 และ 1 มีความยาวเท่ากับจำนวน superpixels ขึ้นมาหลาย ๆ array
number_of_fake_datapoints = 200 Z_dat = np.random.randint(0,2,size=(number_of_fake_datapoints,number_of_superpixel)) # Z_dat shape is (200,60)
- ซึ่งเราจะทำการสุ่มสร้าง array ที่ประกอบไปด้วย 0 และ 1 มีความยาวเท่ากับจำนวน superpixels ขึ้นมาหลาย ๆ array
-
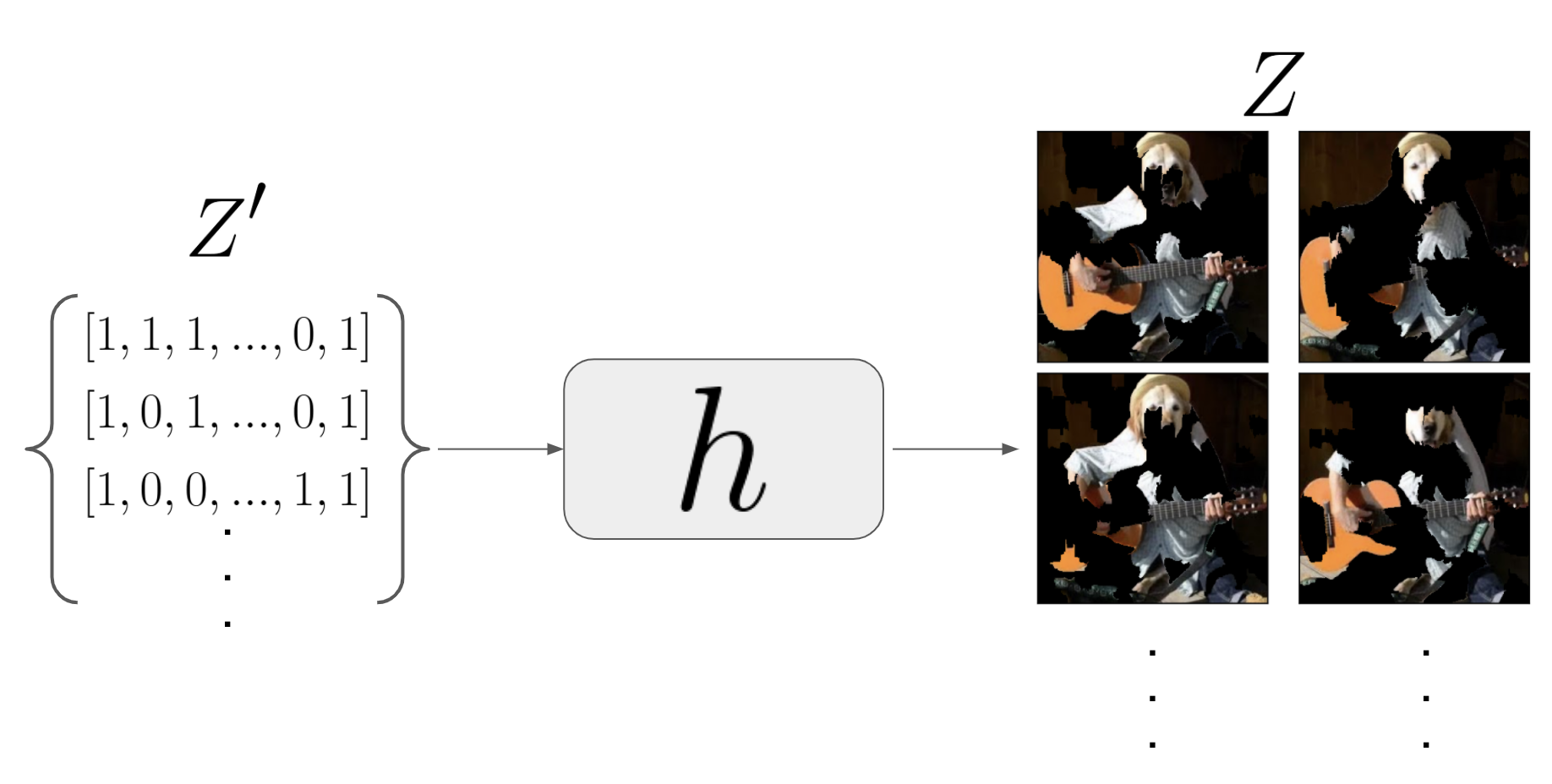
เปลี่ยน fake dataset ซึ่งตอนนี้อยู่ใน representation ของ input ของ explainer ให้อยู่ใน representation ของ input ของโมเดลหลัก หรือก็คือเปลี่ยน \(Z'\) เป็น \(Z\)
Z = [] for i in range(number_of_fake_datapoints): z = np.nonzero(Z_dat[i]) mask = np.isin(segments,z) z = x*mask[...,None] Z.append(z) Z = np.array(Z) Z.shapeในภาพด้านล่างจะเห็นว่าใน dataset $Z$ นั้นจะเป็นภาพที่ขาด ๆ หาย ๆ ไปบางส่วน โดยที่แต่ละภาพก็จะขาดไปไม่เท่ากัน
-
นำ dataset \(Z\) ไปเข้าโมเดล \(f\) และหา probability ของ acoustic guitar ของแต่ละ fake datapoint ออกมา หรือก็คือจะได้ \(f(z)\)
# ดึงคอลัมน์ที่ 402 ซึ่งก็คือ index ของ probability ของ 'acoustic guitar' f_z = model.predict(Z)[:,402]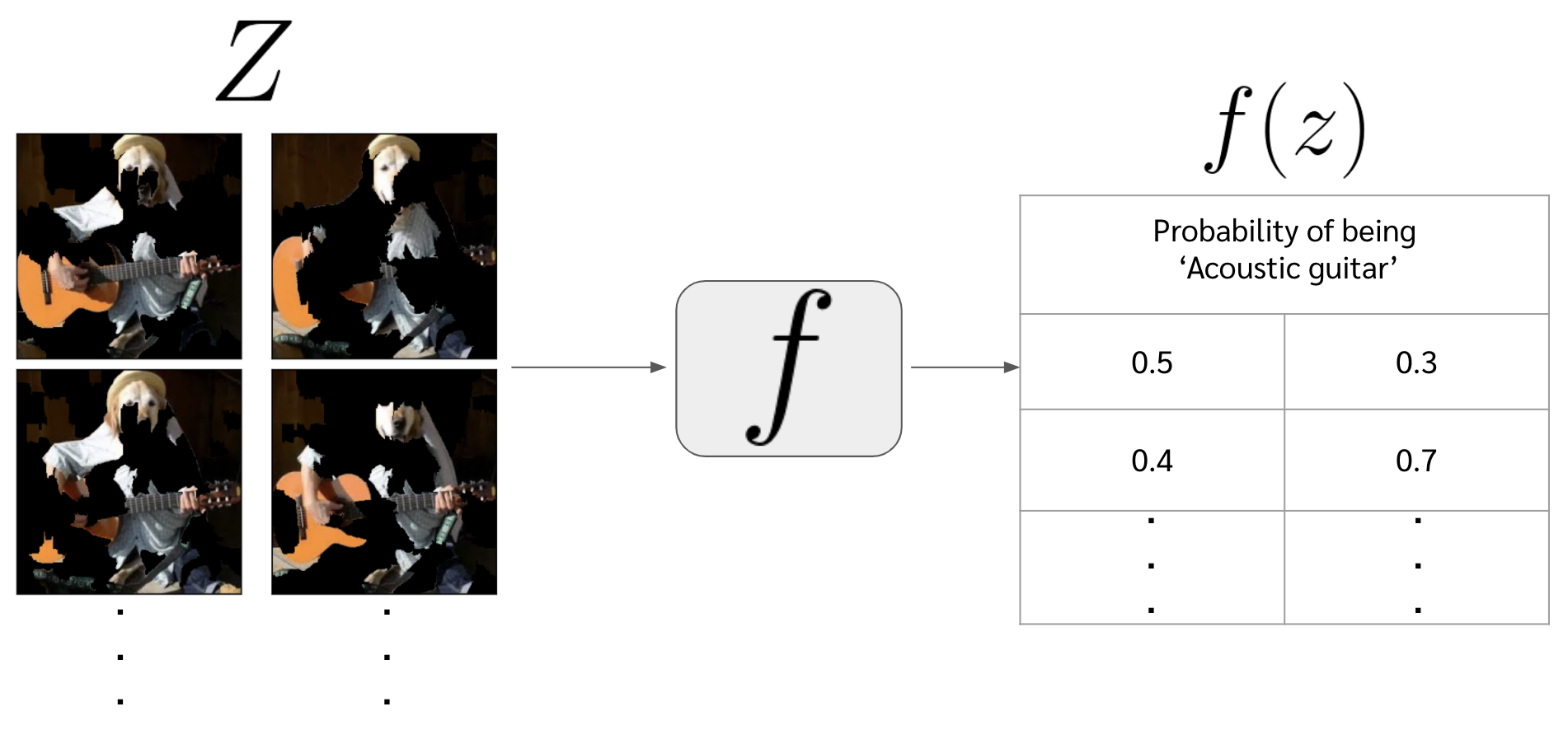
- หา distance ระหว่าง fake datapoint แต่ละจุดหรือ \(z'\) กับข้อมูลจริงหรือ \(x'\) ด้วยฟังก์ชัน \(D\) และนำไปคำนวณ weight ของ fake datapoint นั้น ๆ ด้วยสมการที่ \eqref{eq:pi} (แต่ที่จริงสมการนี้เราจะ design เองใหม่ก็ได้)
- หา distance ระหว่าง fake datapoint \(z'\) กับ \(x'\)
from sklearn.metrics import pairwise_distances distance = pairwise_distances(x_dat.reshape(1,-1),Z_dat) - คำนวณ weight หรือ \(\pi\) ของแต่ละ \(z\)
pi = np.sqrt(np.exp(-(distance ** 2) / kernel_width ** 2))
- หา distance ระหว่าง fake datapoint \(z'\) กับ \(x'\)
- นำ dataset \(Z'\) ไปเทรนโมเดล explainer หรือ \(g\) โดยที่มี label เป็น \(f(z)\) ที่เพิ่งได้มาในข้อที่ 4 และกำหนด sample weight ตามค่า \(\pi\) ด้วย
from sklearn.linear_model import LinearRegression lr = LinearRegression() lr_model = lr.fit(X=Z_dat, y=f_z, sample_weight=pi.ravel())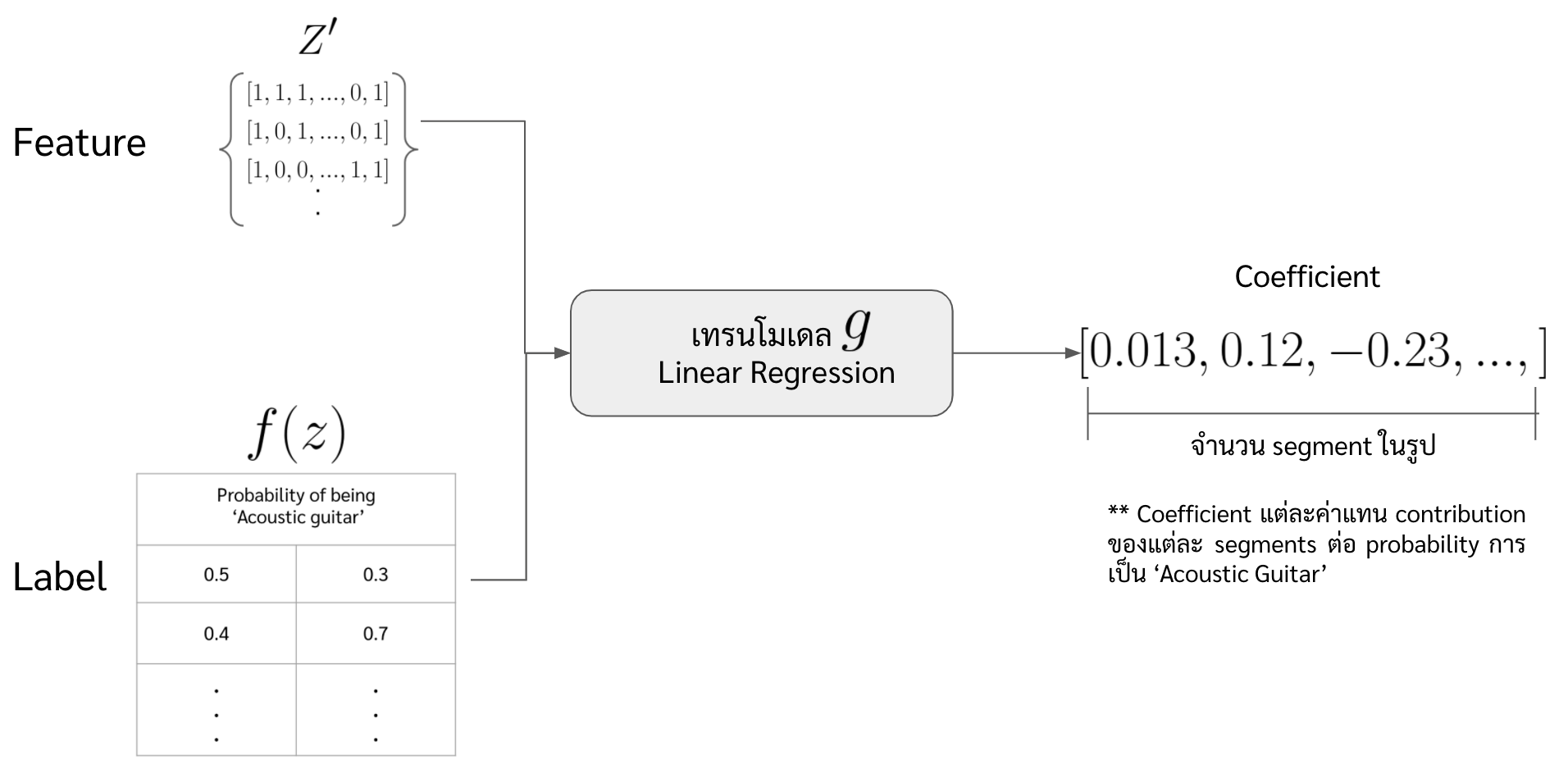
- ดู coefficient ของแต่ละฟีเจอร์ในโมเดล \(g\) เราก็จะรู้ว่า แต่ละฟีเจอร์ใน \(z'\) (ในที่นี้คือแต่ละ super pixel) ส่งผลยังไงกับผลการทำนายบ้าง
- อย่างในกรณีนี้จะทำการเลือก superpixel ที่มี coeffficient ที่มากที่สุดมา 10 อันดับ มาพล็อตดูว่า โมเดลเราดู segment ไหน ถึงบอกว่านี่คือรูปของ acoustic guitar
## เลือก index ของ 5 coefficient มีที่ค่าสูงที่สุด importance_part = lr_model.coef_.argsort()[-5:][::-1] ## สร้างรูปแสดงส่วนที่ model เราดู mask = np.isin(segments,importance_part) importance_image = x*mask[...,None] skimage.io.imshow((mark_boundaries(importance_image, segments)))

- อย่างในกรณีนี้จะทำการเลือก superpixel ที่มี coeffficient ที่มากที่สุดมา 10 อันดับ มาพล็อตดูว่า โมเดลเราดู segment ไหน ถึงบอกว่านี่คือรูปของ acoustic guitar
-
ที่นี้ถ้าเราย้อนไปดูจะพบว่า โมเดลเราบอกว่ารูปนี้เป็นรูปของ golden retriever ด้วย เราก็ลองทำของ golden retriever บ้าง ด้วยการเปลี่ยน index ของ column ที่เราสนใจที่ข้อ 4 แล้วก็รันลงมาใหม่
#### ข้อ 4 f_z = model.predict(Z) # ดึงคอลัมน์ที่ 207 ซึ่งก็คือ index ของ probability ของ 'golden retriever' f_z = f_z[:,207] f_z.shape #### ข้อ 5 from sklearn.metrics import pairwise_distances kernel_width = 0.25 distance = pairwise_distances(x_dat.reshape(1,-1),Z_dat) pi = np.sqrt(np.exp(-(distance ** 2) / kernel_width ** 2)) pi.shape #### ข้อ 6 from sklearn.linear_model import LinearRegression lr = LinearRegression() lr_model = lr.fit(X=Z_dat, y=f_z, sample_weight=pi.ravel()) #### ข้อ 7 importance_part = lr_model.coef_.argsort()[-5:][::-1] mask = np.isin(segments,importance_part) importance_image = x*mask[...,None] skimage.io.imshow((mark_boundaries(importance_image, segments)))
ในการทำ LIME กับ image classification นั้น ถ้าสรุปเพื่อให้เข้าใจง่ายแล้วก็คือเราลองปิดภาพบางส่วนไป แล้วเอาไปให้โมเดลเราทำนาย แล้วดู probability ของการเป็น guitar
- ถ้าปิดส่วนนั้นไปแล้ว probability ของการเป็น guitar ของทั้งภาพมันต่ำ ก็แปลว่าภาพส่วนที่ปิดไปเป็นส่วนที่โมเดลเรามันมองว่าเป็น guitar น่ะแหละ พอปิดไปมันเลยมองไม่เห็น
- แต่ถ้าปิดส่วนนั้นไปแล้ว probability ของการเป็น guitar ของทั้งภาพมันเท่าเดิม ก็แปลว่าโมเดลเราไม่ได้สนใจภาพส่วนตรงนั้น
จากขั้นตอนทั้งหมดข้างบนนั้น จริง ๆ แล้วคนเขียนเปเปอร์ LIME นี้เค้า implement มาเป็น library ให้หมดแล้ว ซึ่งเราจะเหลือโค้ดแค่ไม่กี่บรรทัดเท่านั้น
-
อ่านรูปกับ model มาก่อน
## อ่านรูป import skimage.io x = skimage.io.imread("dog-guitar.jpg") x = skimage.transform.resize(x, (299,299)) ## อ่านโมเดล import keras model = keras.applications.inception_v3.InceptionV3() - เอารูปกับ model ไปสร้าง explainer ได้เลย
from lime import lime_image explainer = lime_image.LimeImageExplainer() explanation = explainer.explain_instance(x, model.predict, top_labels=5, hide_color=0, num_samples=1000) - พล็อตออกมาดู
- segment ที่สำคัญของ acoustic guitar
from skimage.segmentation import mark_boundaries import matplotlib.pyplot as plt # 402 เป็น index ของ acoustic guitar temp, mask = explanation.get_image_and_mask(402, positive_only=True, num_features=5, hide_rest=True) plt.imshow(mark_boundaries(temp, mask))

- segment ที่สำคัญของ golden retriever
# 207 เป็น index ของ golden retriever temp, mask = explanation.get_image_and_mask(207, positive_only=True, num_features=5, hide_rest=True) plt.imshow(mark_boundaries(temp, mask))

- segment ที่สำคัญของ acoustic guitar
หวังว่าในบทความนี้พอจะทำให้เห็นภาพว่าจริง ๆ แล้ว concept และขั้นตอนของ LIME มันเป็นอย่างไร จะได้เอาไปใช้ประโยชน์ได้ถูก สำหรับผู้อ่านที่คิดจะใช้ LIME จริง ๆ ก็อย่าเมื่อยตุ้มเขียนโค้ดเองแบบที่เราทำกันในบทความนี้ ทางผู้เขียนเปเปอร์เค้าทำ lib ไว้ให้เราใช้อย่างง่ายดายพร้อมกับตัวอย่างการใช้งาน LIME กับข้อมูลหลากหลายประเภท เช่น tabular data, text, image ซึ่งสามารถตาม link นี้ ไปได้เลย ซึ่งเค้าทำออกมาดูดีมากเลยแหละ ไปดูเถอะ
ในบทความต่อไปน่าจะพูดถึง DeepLIFT และ SHAP ที่เป็นวิธีในการทำ local interpretation เหมือนกัน
Discliamer
รายละเอียดในบทความนี้มาจากความเข้าใจส่วนตัว อาจมีข้อผิดพลาด หากพบจุดผิดพลาด ขอความกรุณาแจ้งทาง facebook หรือ email: thammasorn.han@hotmail.com