ตามปกติแล้ว เมื่อเราสร้าง model สำหรับ classification มาแล้ว เช่น ทำนายว่าลูกค้าคนใดจะมาชำระเงินล่าช้า, ทำนายว่าลูกค้าจะตอบรับการแนะนำโปรโมชั่นใหม่ๆรึเปล่า ฯลฯ เราอาจจะอยากศึกษาเพิ่มเติมว่าฟีเจอร์ไหน หรือปัจจัยใดบ้างที่มีผลต่อ model ของเรา แล้วถ้ามันส่งผลต่อโมเดลของเราแล้วมันส่งผลไปในทิศทางไหน ส่งผลอย่างไร
ซึ่งปกติแล้วถ้าเป็น algorithm แบบ tree-based เราก็จะมักจะไปดู feature importance กัน ซึ่งก็จะบอกเราได้ระดับหนึ่งว่าฟีเจอร์ใดส่งผลต่อโมเดลเราบ้าง แต่การดูแค่ feature importance เนี่ย มันก็จะมีข้อจำกัดอยู่บ้าง เช่น เราไม่สามารถบอกได้ว่าความสัมพันธ์ระหว่างฟีเจอร์นั้น ๆ กับผลการทำนายมันเป็นอย่างไรบ้าง ซึ่งเราก็อาจจะต้องไปพล็อตดูอีกที เช่น อาจจะพล็อต boxplot ของฟีเจอร์เทียบระหว่าง 2 classes นอกจากนี้อาจจะมีบางฟีเจอร์ที่ไม่ได้ส่งผลต่อ model เราแบบ monotonic (ทางเดียว) หรือ linear นั้น การทำ boxplot อย่างเดียว อาจจะไม่เห็นความสัมพันธ์นี้ หรือในกรณีที่ถ้าเราใช้โมเดลอื่น ๆ ในการ classify ข้อมูลของเรา แล้วโมเดลนั้นไม่มี feature importance ให้ดูนี่เราจะไม่รู้เลยว่า model มันคิดยังไง
ทำให้ด้วยเหตุฉะนี้แล้ว เลยมีวิธีการที่ชื่อว่า Partial Dependence Plot (PDP) ขึ้นมา ซึ่งมันเป็นวิธีที่ใช้หา marginal effect ของแต่ละฟีเจอร์ที่มีผลต่อ output ของโมเดล (probability ในกรณีของ classification หรือค่าที่ทำนายออกมาในกรณีของ regression) ซึ่งดูได้ว่าฟีเจอร์ใดมีผลมากหรือน้อย และฟีเจอร์นั้นมีความสัมพันธ์กันอย่างไรกับผลการทำนายของโมเดล นอกจากนี้เราสามารถดูผลการ interact กันระหว่างสองฟีเจอร์กับผลที่โมเดลทำนายออกมาได้ด้วย
ซึ่ง PDP นั้นสามารถนำไปใช้ได้กับทุกโมเดลที่นำมาแก้ปัญหา classification และ regression ไม่ว่าจะเป็นพวก tree-based model หรือ neural network ทำให้มันมีประโยชน์มาก ๆ ในการวิเคราะห์พฤติกรรมของโมเดลเพื่อจะนำไปใช้ในทาง business หรือในด้านอื่น ๆ ต่อไป
อินโทรมาซะยาว ได้เวลาเข้าเนื้อหาแล้ว ในบทความนี้เราจะแบ่งออกเป็น 2 ส่วนหลัก ๆ คือ
- วิธีการพล็อต PDP ด้วย library sklearn และวิธีดู
- เนื้อหาเชิงลึกว่า PDP นั้นสร้างมายังไง ซึ่งจะเขียนในส่วนที่ 1 ก่อน เผื่อใครไม่ต้องการรู้ว่ามันคำนวณยังไง อยากรู้แค่วิธีเขียนโค้ดให้พล็อตแล้วตีความยังไงจะได้อ่านแค่ส่วนแรกเด้อ
ขั้นตอนการพล็อตและการตีความPDP
-
ก่อนอื่นเราต้องสร้างโมเดลก่อนเด้อ ในตัวอย่างจะขอใช้ titanic แล้วกันนะ มันง่ายดี 555 ที่จริงการสร้างโมเดลที่ดีเราต้องทำพวก fine-tune โมเดล ทำ cross-validation แต่ในบทความนี้ขอข้ามไปก่อนเนอะ ^3^
## Import lib ที่ใช้ import numpy as np import pandas as pd import matplotlib.pyplot as plt ## อ่านข้อมูล และลบฟีเจอร์ที่ไม่ใช้ออก (ฟีเจอร์ Name) df = pd.read_csv('titanic.csv') del df['Name'] ## แบ่ง dataframe สำหรับฟีเจอร์ และ label features = pd.get_dummies(df.drop('Survived',axis=1)) labels = df['Survived'] ## แบ่ง data สำหรับ train กับ test from sklearn.model_selection import train_test_split train_features,\ test_features,\ train_labels,\ test_labels = train_test_split(features,\ labels,\ test_size = 0.25) # เทรนโมเดล from sklearn.ensemble import RandomForestClassifier rf = RandomForestClassifier(n_estimators=100, max_depth=10) rf.fit(train_features, train_labels)เทรนโมเดลเสร็จแล้วก็มาเช็คความแม่นยำของโมเดลซักหน่อย ยิ่งโมเดลแม่นยำมากเท่าไหร่ ค่า importance และกราฟ PDP ที่ได้จะยิ่งน่าเชื่อถือมากขึ้นเท่านั้น
from sklearn.metrics import classification_report print (classification_report(test_labels, rf.predict(test_features)))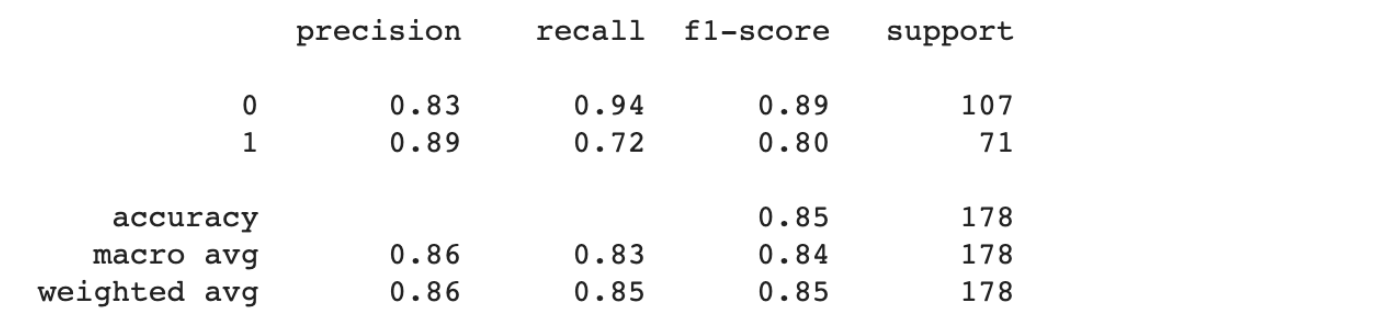
หลังจากนั้นเราก็ดู feature importance พอเป็นพิธี จะพบว่า อายุ(Age) นั้นมี importance มากที่สุด ตามด้วย ค่าโดยสาร(Fare), และ เพศ(male/female)
#################### ## Feature Importance #################### fig, ax = plt.subplots(figsize=(3, 2),dpi=150) pd.Series(rf.feature_importances_, index=features.columns)\ .nlargest(10)\ .plot(kind='barh', ax=ax)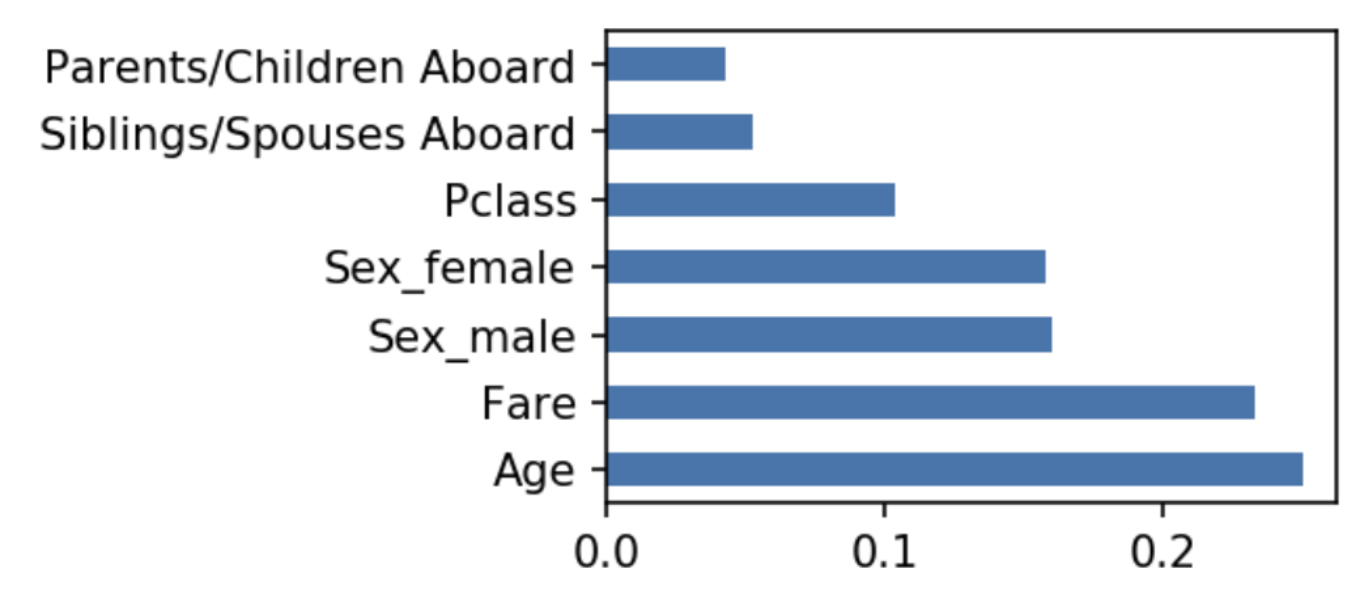
-
หลังจากนั้นเราก็ใช้ฟังก์ชัน plot_partial_dependence ใน sklearn.inspection พล็อตโลด โดยที่ parameters ที่ต้องใส่มีดังนี้
from sklearn.inspection import plot_partial_dependence fig, ax = plt.subplots(figsize=(3, 3),dpi=125) plot_partial_dependence(estimator = rf,\ X = train_features,\ features = ['Age'],\ grid_resolution=6,ax=ax)- estimator: โมเดลที่เราเพิ่ง train มาในข้อที่แล้ว
- X: dataset ที่เราใช้ train โมเดลในข้อที่แล้ว
- features: list ของชื่อ column ที่เราจะพล็อตดู effect ของมันต่อผล predict ของโมเดล ในกรณีที่อยากพล็อตแบบ interact ระหว่าง 2 ฟีเจอร์ด้วย ก็ใส่เป็น list ซ้อน list ไปโลด
- grid_resolution: ความละเอียดของกราฟที่เราจะพล็อต ยิ่งใส่ค่าเยอะกราฟจะยิ่งมีหยักเยอะ ถ้าใส่น้อยก็จะเรียบ ๆ ต้องเลือกให้พอดี ๆ ถ้าเยอะไปเส้นมันหยักเกินไปเราจะดูไม่รู้เรื่อง แต่ถ้าน้อยไปมันก็อาจจะตรงเกินไป อาจจะทำให้เราตีความผิด นอกจากนี้ถ้า grid_resolution มีค่าสูง ๆ จะยิ่งทำให้การพล็อตกราฟนี้ใช้เวลานานขึ้น เนื่องจากต้องไปคำนวณค่าหลาย ๆ จุดเพื่อมาพล็อต รูปข้างล่างแสดงตัวอย่างการเปลี่ยนแปลงของค่า grid resolution ไปเรื่อย ๆ
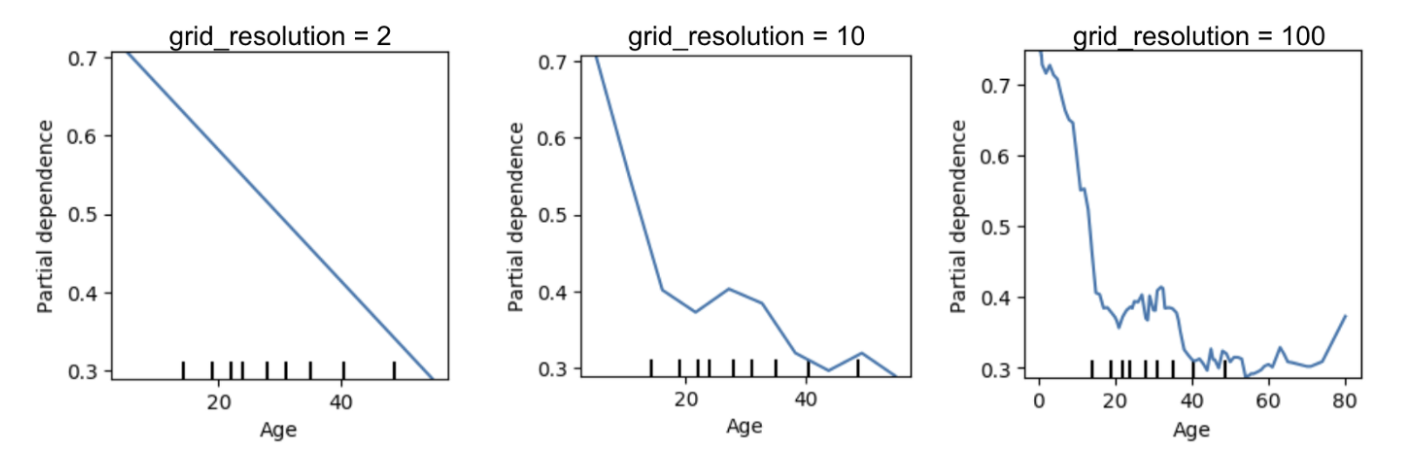
หลังจากนั้นเราจะได้กราฟ PDP ของแต่ละฟีเจอร์มาโดยที่
- แกน x คือ range ค่าของฟีเจอร์ตั้งแต่ min ถึง max ของแต่ละฟีเจอร์ใน dataset เรา
- แกน y คืออิทธิพลของฟีเจอร์นั้น ณ ค่านั้นต่อผลการ predict (ถ้าเป็น classification ก็คือต่อ probability / ถ้าเป็น regression ก็คือค่าที่ predict ออกมา) ถ้าอยากรู้ว่าจริง ๆ มันคือค่าอะไรก็อ่านพาร์ทข้างล่างเด้อ
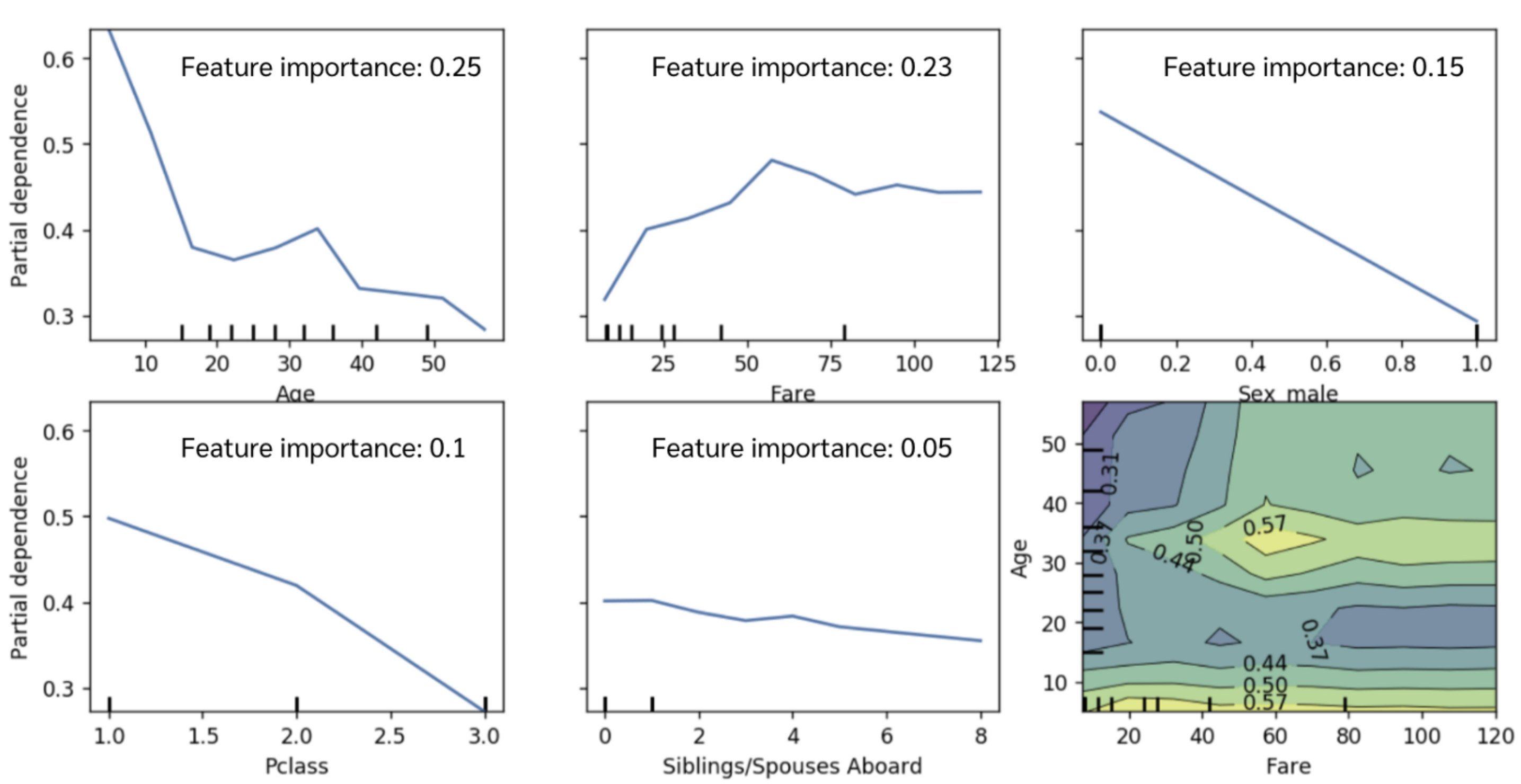
ส่วนวิธีดูกราฟ PDP ก็ง่าย ๆ เลย Range ของแกน y หรือ (\(y_{max}\) - \(y_{min}\))ในกราฟยิ่งกว้างแสดงว่ายิ่งมีผลต่อโมเดลเยอะ ส่วนใหญ่ฟีเจอร์ที่มี importance สูงก็จะมี range นี้กว้างตามไปด้วย เพราะมันแสดงว่าตลอดช่วงของค่า X ที่เป็นไปได้ สามารถเปลี่ยนค่า y ได้กว้างขนาดไหน ซึ่งแสดงให้เห็นดังภาพด้านบนจะเห็นว่าในฟีเจอร์ age ซึ่งเป็นฟีเจอร์ที่มี feature importance มากที่สุดนั้น range ของแกน y จะอยู่ระหว่าง 0.3 ถึง 0.6 ในขณะที่ในฟีเจอร์ Siblings/Spouses Aboard ที่ importance ต่ำเกือบจะที่สุดนั้นกราฟแทบจะเป็นเส้นตรง ค่าในแกน y จะอยู่แค่ระหว่าง 0.3 ปลาย ๆ ถึง 0.4 เท่านั้น นอกนั้นก็ดูทรงของกราฟได้เลยว่าถ้าค่าของฟีเจอร์ประมาณนี้แล้วค่าแกน y สูงหรือต่ำตรงไหนอะไรยังไงบ้าง ยกตัวอย่างเช่น จากกราฟด้านบนจะเห็นได้ว่า หากมีอายุน้อยจะยิ่งมีโอกาสที่จะรอดในเหตุการณ์เรือไททานิคสูงและค่อย ๆ ลดลงมา นอกจากนี้ในกราฟ Fare นั้นจะเห็นได้ว่า ยิ่งตั๋วแพงเท่าไหร่ ยิ่งมีโอกาสรอดมากเท่านั้น
ข้อควรระวัง ในการดูกราฟ PDP !!!
-
เวลาเราดูรูปแบบของกราฟ PDP ต้องดูจำนวนข้อมูลในแต่ละช่วงเสมอ หรือดู distribution ของ data ด้วยเสมอ เพื่อเป็นน้ำหนักให้กับ pattern ในแต่ละช่วงนั้น ๆ ไม่อย่างนั้นเราอาจจะไปตีความส่วนของแพทเทินที่แทบจะไม่มีข้อมูลอยู่เลย ซึ่ง distribution ของ data นั้นมักจะถูกแสดงเป็น rug plot ข้างใต้กราฟ จากรูปด้านล่างจะเห็นว่าช่วงที่ระบายสีแดงนั้น แทบไม่มีข้อมูลเลย อาจจะทำให้ความน่าเชื่อถือของแพทเทินในส่วนนั้นต่ำ
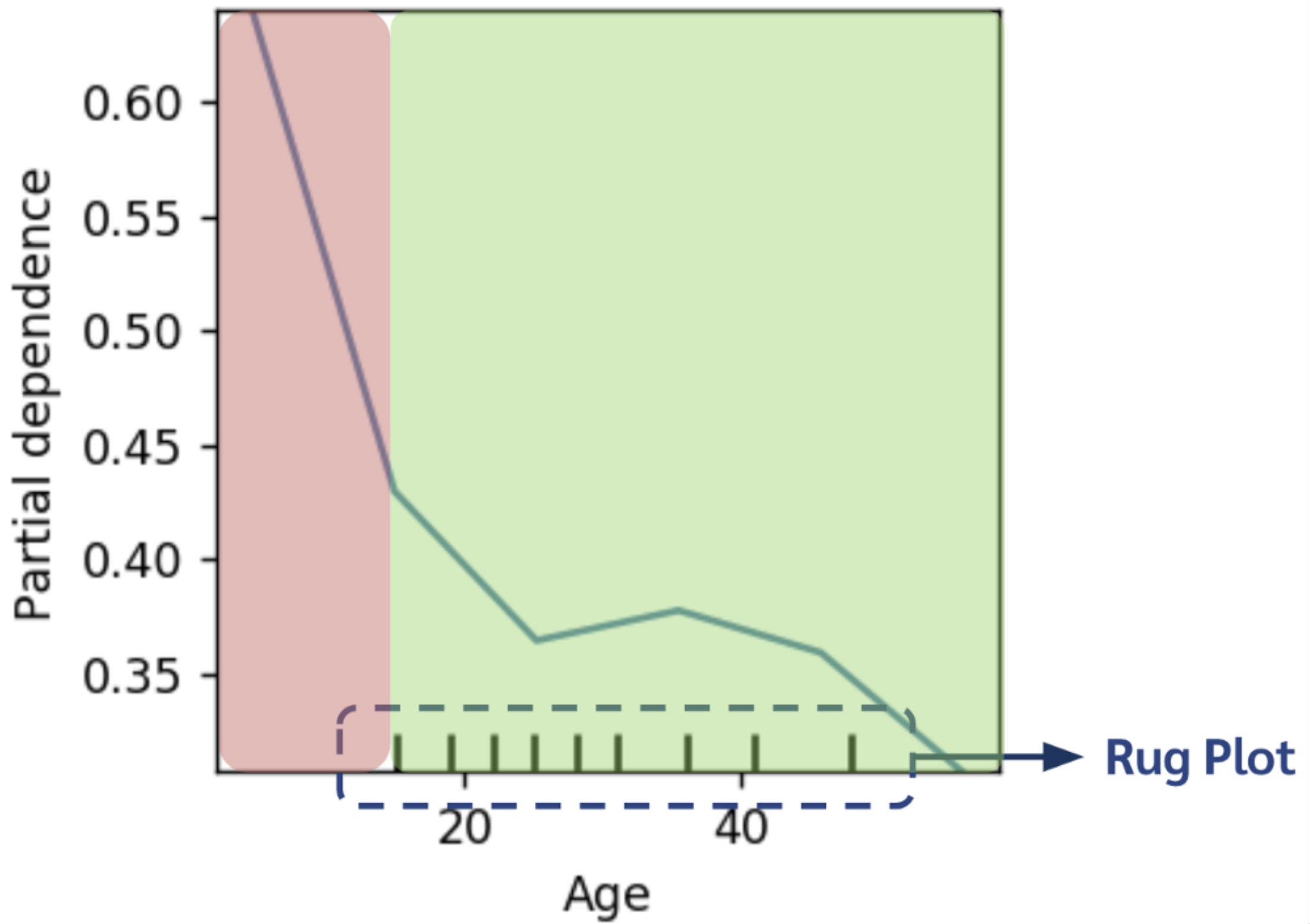
-
PDP นั้นถูกคิดขึ้นมาภายใต้สมมติฐานว่าไม่มี correlation กันระหว่างฟีเจอร์ ถ้าหากมีฟีเจอร์ที่ correlation กันอาจจะทำให้กราฟ PDP ออกมาผิดเพี้ยนกว่าที่ควรจะเป็นได้ (เป็นเพราะอะไร อ่านในพาร์ทถัดไป)
เบื้องหลังการทำงานของ PDP !!!
จริง ๆ แล้ว การพล็อต PDP แต่ละจุดนั้น จะต้องถูกคำนวณด้วยสมการที่ \eqref{eq:eq_1} โดยที่
- \(x_S\) คือเซ็ตของฟีเจอร์ที่เราสนใจ (1-2 ฟีเจอร์)
- \(x_C\) คือเซ็ตของฟีเจอร์อื่น ๆ นอกเหนือจากที่เราสนใจ
- \(\hat{f}\) คือโมเดลที่เราเทรนมา ซึ่งจะให้ output เป็นค่าที่ทำนาย (regression) หรือ probability ของ positive class (classification) (แต่ในหลาย ๆ ที่ \(\hat{f}\) คือ logit probability ไม่ใช่แค่ raw probability เช่นใน ภาษา R เป็นต้น [3])
\begin{equation} \label{eq:eq_1} \hat{f}(x_S) = E_{x_C}[\hat{f}(x_S,x_C)] = \int \hat{f}(x_S,x_C) d \mathbb{P}(x_C) \end{equation}
จะเห็นได้ว่าสมการที่ \eqref{eq:eq_1} เป็นการหาค่า Expected Value ของค่า \(\hat{f}(x_S,X_C)\) ณ จุด X_S ใด ๆ ด้วยวิธี integrate นั่นเอง หากหลาย ๆ คนคิดว่าสมการข้างบนมันช่างงงงวยซะเหลือเกิน เค้าก็คิดวิธีการประมาณ ๆ เอาด้วยสมการที่ \eqref{eq:eq_2} ด้านล่างไว้ให้แล้ว โดยที่ n คือจำนวนข้อมูลใน dataset
\begin{equation} \label{eq:eq_2} \hat{f}(x_S) = \frac{1}{n} \sum_{i=1}^{n} \hat{f}(x_S,x^{(i)}_{C}) \end{equation}
ถ้าดูสมการที่ 2 แล้วยังรู้สึกว่างง ๆ อยู่ก็เชิญดู step ด้านล่างเอาได้เลย
-
สมมติเรามี dataset หน้าตาแบบรูปด้านล่าง และฟีเจอร์ที่เราสนใจคือ Feature A หรือก็คือ \((x_S = \{A\}, x_C = \{B,C\})\) แล้วเรานำ dataset ชุดนี้ไปเทรนโมเดลไว้เรียบร้อยแล้ว
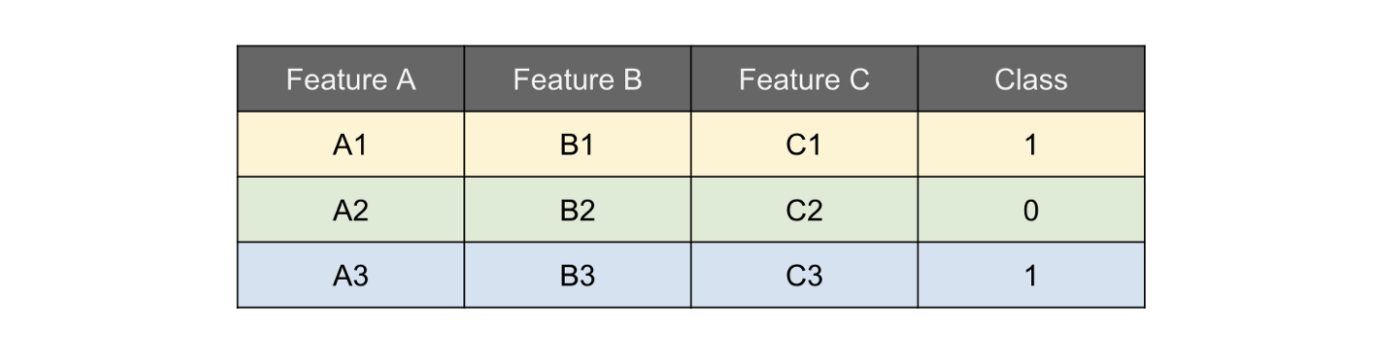
-
เราจะทำการ expand ตัว dataset ของเราออกมาให้ได้ดังรูปด้านล่าง จะเห็นว่า ในแต่ละ unique value ของ \(x_C\) จะมีค่า A1,A2, และA
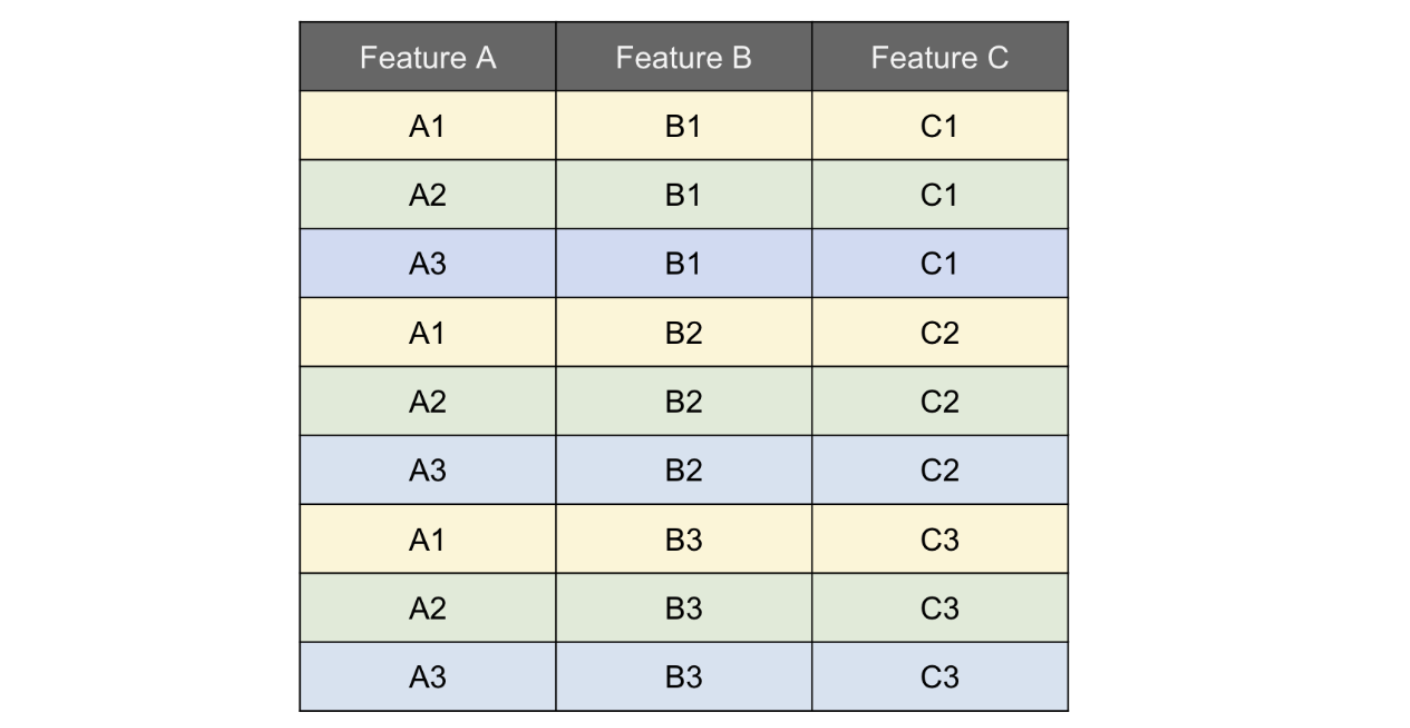
-
จับมันโยนเข้าโมเดลที่เราเทรนไว้แล้ว ให้ทำนายค่า probability ของ class 1 ออกมาแล้วนำ probability พวกนั้นไปเข้า logit function ขั้นตอนนี้คือการทำฟังก์ชัน f^
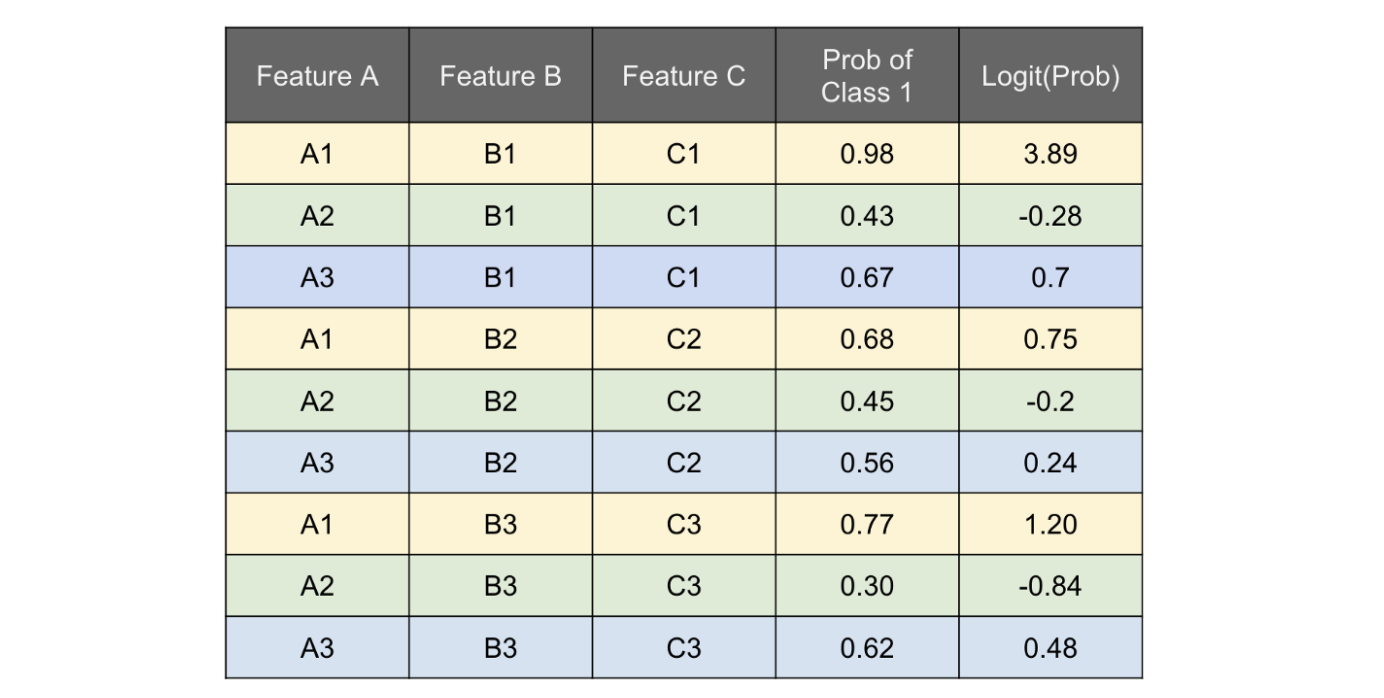
-
หลังจากนั้น จัดกลุ่ม dataset ด้วย feature A (ฟีเจอร์ที่เราสนใจ) แล้วหาค่า average ของ logit ของแต่ละกลุ่มออกมา
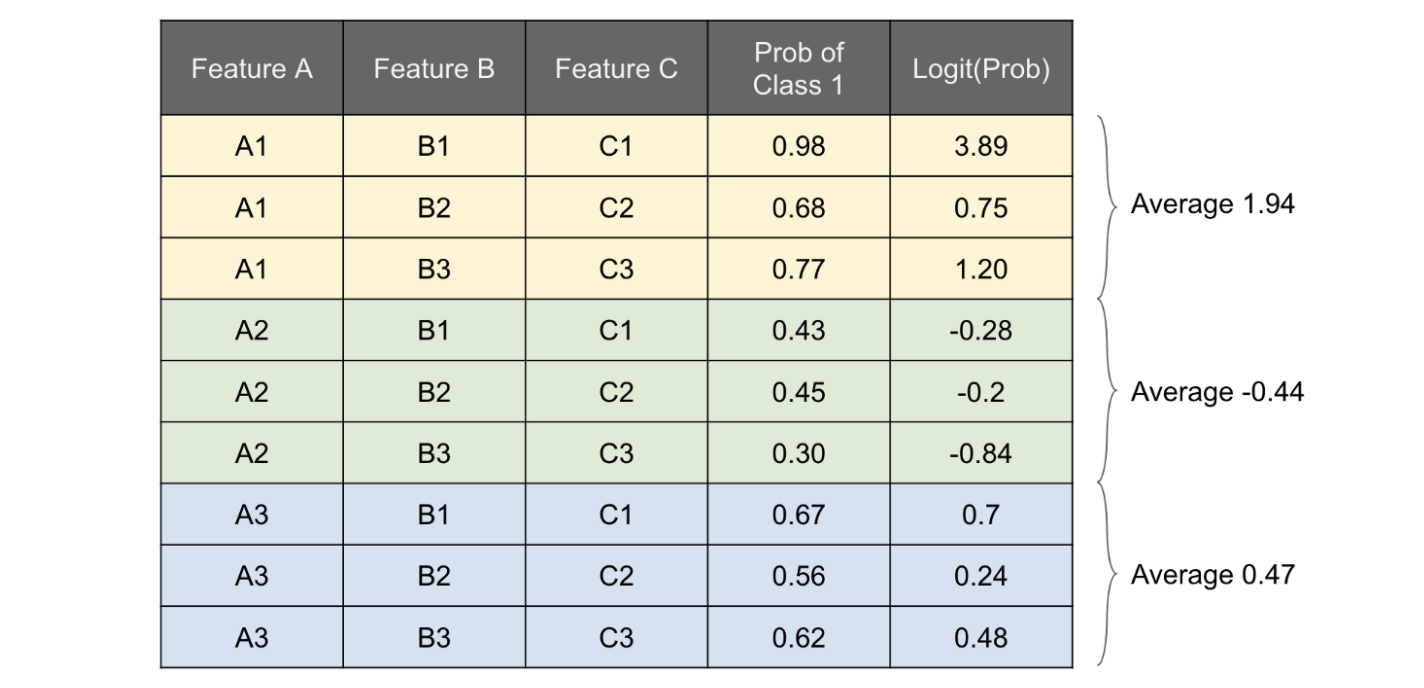
-
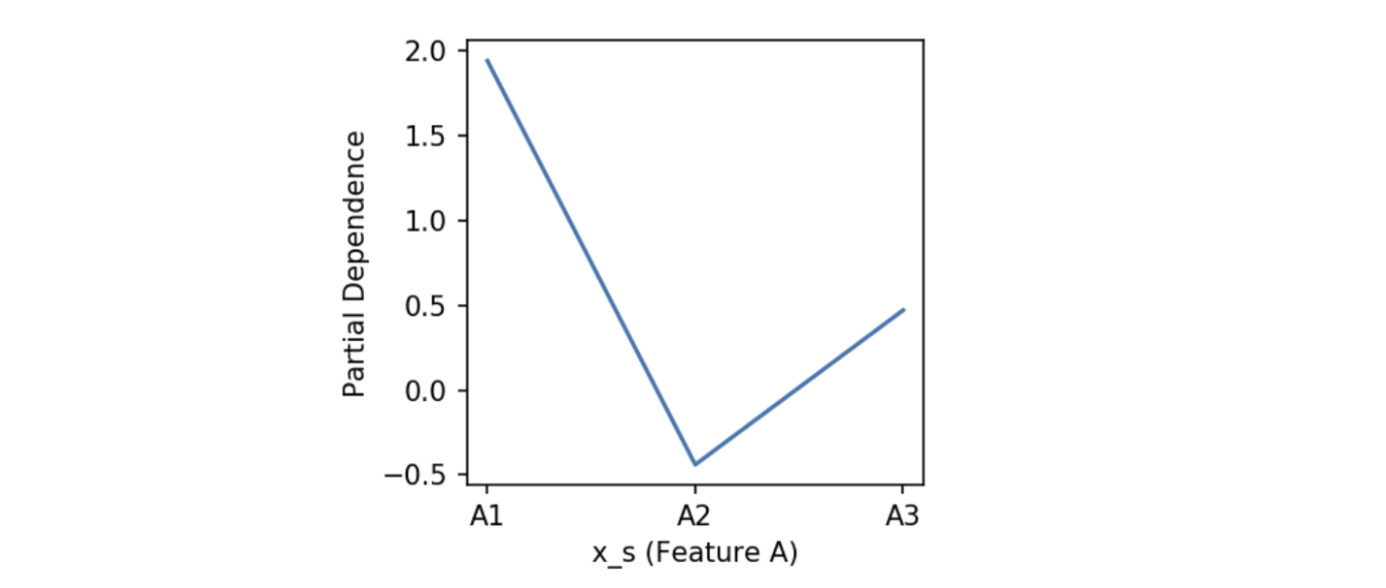
เอาค่า average พวกนั้นมา plot กราฟ จะได้กราฟ PDP ออกมา เป็นอันเสร็จสิ้น
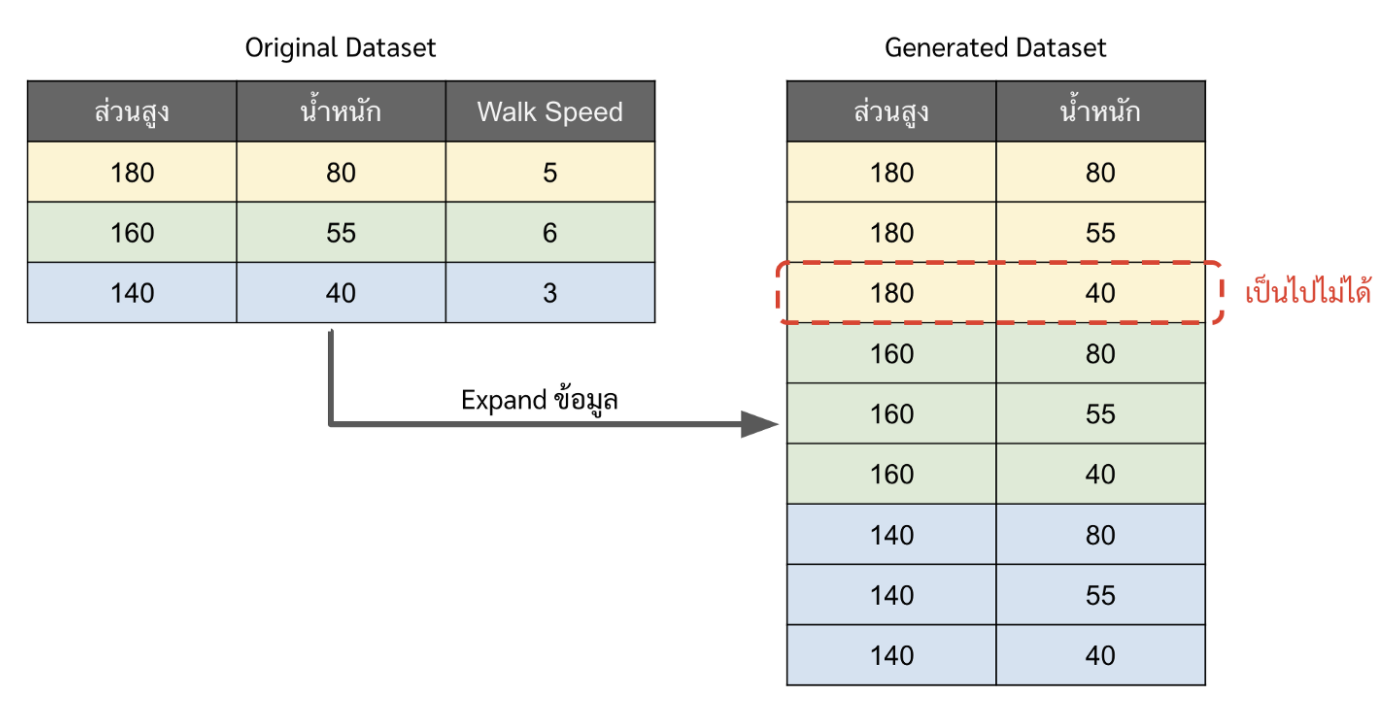
เมื่อมาถึงตรงนี้แล้ว หลาย ๆ คนอาจจะนึกออกแล้วว่าทำไมฟีเจอร์ถึงห้าม มี correlation ต่อกัน เพราะมันจะทำให้ในขั้นตอนที่ 2 หรือตอนที่เราเจนข้อมูลเพิ่มขึ้นมานั้น อาจจะมีข้อมูลที่เป็นไปไม่ได้ในโลกแห่งความเป็นจริงก็ได้ อย่างตัวอย่างใน [1] เค้ายกตัวอย่างมาดี เช่น มี 2 ฟีเจอร์คือส่วนสูงกับน้ำหนักแล้วให้ทำนายความเร็วในการเดิน ซึ่งส่วนสูงและน้ำหนักนั้นมี correlation กัน แต่ตอนเราเจนข้อมูลขึ้นมาเพิ่มมันอาจจะมีข้อมูลที่ ส่วนสูง 2 เมตร น้ำหนัก 40 ก็ได้ ซึ่งจริง ๆ แล้วมันคงเป็นไปไม่ได้ แต่พอเราเอาข้อมูลจุดนั้นไปคิดต่อ มันไม่ real ก็จะทำให้กราฟ PDP อาจจะไม่ real ไปด้วย
สุดท้ายนี้ บทความนี้เขียนตามความเข้าใจส่วนบุคคล ถ้ามีข้อผิดพลาดอันใด ขออภัยไว้ล่วงหน้า ส่วนในอนาคตถ้าขยันจะมาต่อวิธีอื่น ๆ ที่เราใช้ตีความโมเดลได้อีก ที่จริง PDP พล็อตนี่เป็นวิธีที่พื้นฐานที่สุดเลย บะบายจ้า
Reference
[1] https://christophm.github.io/interpretable-ml-book/pdp.html
[2] https://towardsdatascience.com/introducing-pdpbox-2aa820afd312
[3] https://www.rdocumentation.org/packages/randomForest/versions/4.6-12