บทความนี้มาจากเปเปอร์ mixup: Beyond Empirical Risk Minimization
!!! กรุณาอ่าน Q learning ก่อน
Introduction
ในบทความนี้จะ introduce ตัว double Q learning ที่แก้ปัญหา maximisation bias ของ Q-learning ซึ่งที่จริงก็เป็นวิธีที่ถูกนำเสนอในเปเปอร์ Double Q-learning (Hado V. Hasselt 2010) ซึ่งก็ถือว่าออกมานานแล้ว แต่ก็ถูกเอาไปประยุกต์ใช้กับวิธีใหม่ ๆ (รึเปล่าหว่า) ในหลายวิธีเช่น Rainbow Reinforcement learning (State-Of-The-Art ของ DQN) หรือ DDPG เพราะฉะนั้นรู้จักมันไว้ก็ไม่เสียหาย
ปัญหา Maximisation Bias
ถ้าย้อนกลับไปในบทความ Q-learning นั้น เราอัพเดทค่า $Q(s,a)$ ในตารางด้วยสมการด้านล่าง ซึ่งดูเหมือนจะดีแล้วแหละ แต่ว่ามันยังมีปัญหานึงซ่อนอยู่ซึ่งก็คือปัญหา maximization bias ซึ่งเกิดจากพจน์ $max_aQ(s,a)$ ในสมการด้านล่าง
\begin{equation} \label{eq:Q} \definecolor{energy}{RGB}{230,10,0} Q(s,a) \leftarrow Q(s,a) + \alpha (r + {\color{energy}Q(s,argmax(Q(s’,a)))} - Q(s,a)) \end{equation}
แล้ว maximization bias คืออะไรล่ะ ? เดี๋ยวผมเล่าเป็นนิทานให้ฟัง
TL;DR เกิดจากการที่เราพยายามหาค่า average จากค่า max จากการสุ่มอีกทีจะทำให้เราได้ค่า average ที่สูงกว่าค่าจริง ๆ อยู่แล้ว (แต่อ่านนิทานเถอะ ตั้งใจแต่งจริง ๆ pleaseee)
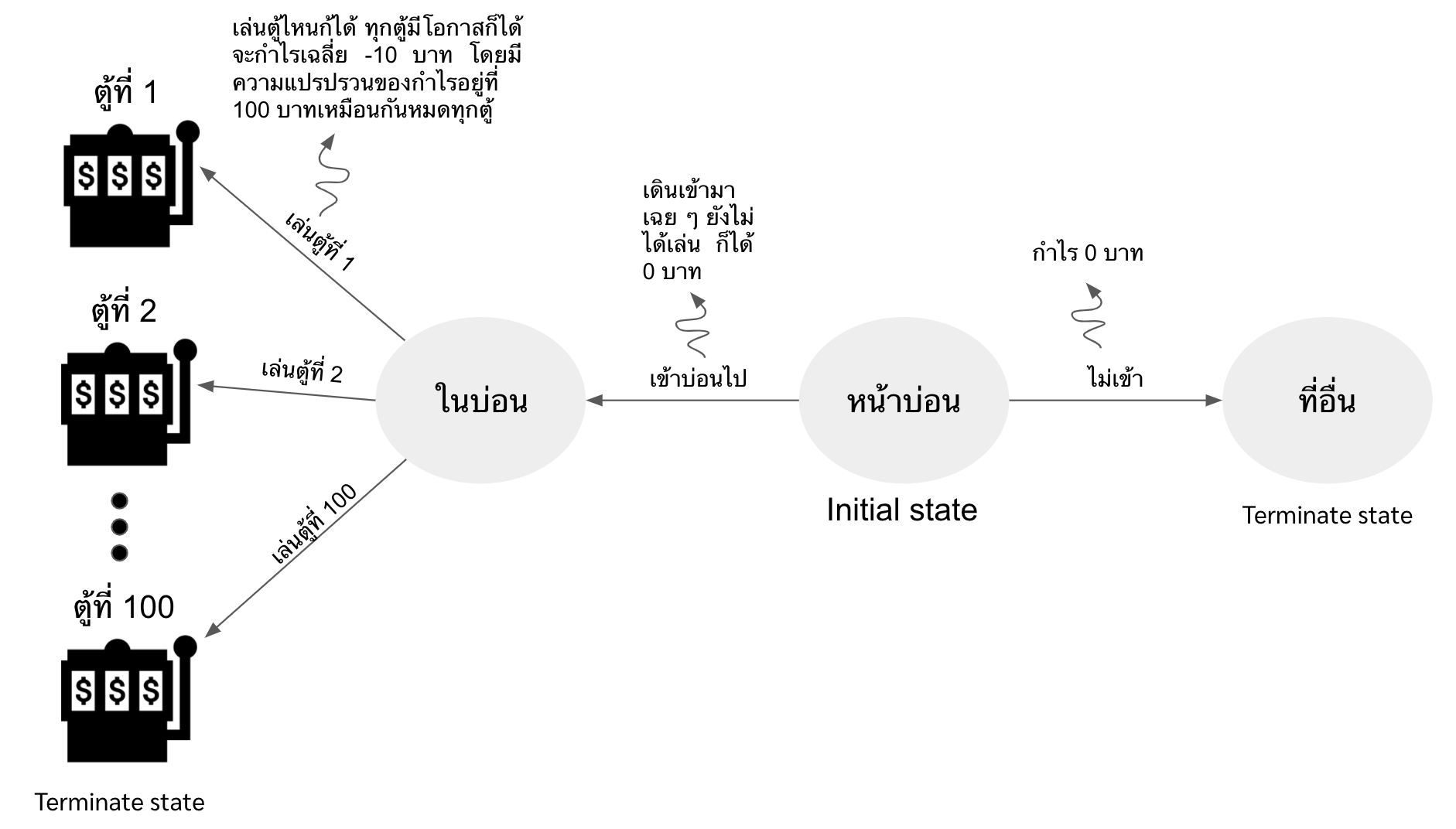
กาลครั้งหนึ่งนานมาแล้วว มีบ่อนอยู่บ่อนหนึ่งในนั้นเต็มไปด้วยตู้ปาจิงโกะเป็นร้อย ๆ ตู้ แต่ว่าด้วยความที่เจ้าของบ่อนขี้โกงหน่อย ๆ ก็เลยแอบตั้งให้ expected กำไรของทุกตู้เป็นการขาดทุนทั้งหมด ซึ่งก็คือประมาณ -10 บาท (ไม่ต้องห่วง ขาดทุนเหมือนกันทุกตู้ 55)
แปลว่าถ้าเล่นบ่อนนี้ไปจำนวนหลาย ๆ ครั้ง แล้วเอาที่ได้กับที่เสียมาเฉลี่ยกัน เราจะเสียเงินประมาณ 10 บาท
แต่ว่าเพื่อหลอกคนมาเล่นบ่อนเนี่ย เค้าก็ต้องทำให้มีทั้งคนที่ได้สตางค์และคนที่เสียสตางค์ เค้าก็เลยใส่ variance เข้าไปในทุกตู้ โดยให้ variance เป็น 100 บาท เพราะฉะนั้นแล้วก็จะมีคนที่โชคดีได้ตังกลับไปบ้าง
ถึงขั้นตอนนี้ ถ้าเราโมเดล environment นี้ จะออกมาได้ดังรูปด้านล่าง เริ่มที่ state “อยู่หน้าบ่อน” ถ้าเลือกที่จะไม่เล่น เราก็ไม่ได้ไม่เสียอะไร (reward=0) แต่ถ้าเราเลือกที่จะเล่น เราก็เดินเข้าไปในบ่อน ถึงตอนนี้เราก็ยังไม่ได้ไม่เสียอะไรอยู่ดี (reward=0) โดยที่ใน state นี้มีทางเลือกให้ทำคือ กดตู้ตั้งแต่ตู้ที่ 1-100 (มี 100 actions) โดยที่ทุก action จะมี reward เหมือนกันก็คือ mean = -10 และ variance = 100
ต่อมามีนายแบลงค์ (นามสมมติ) ผีพนันผู้ที่ไม่เคยเล่นพนันที่นี่เลย วันนึงเดินผ่านหน้าบ่อน เกิดนึกครึ้มใจอยากเสี่ยงโชคขึ้นมา เลยลองเข้าไปเล่นในบ่อนนั้น
ถ้าเราเขียน Q table ของแบลงค์จะได้ดังตารางด้านล่าง เริ่มที่ 0 ไปให้หมดก่อน ส่วน Q ของ state “ที่อื่น” ขอไม่แสดงเพราะเป็น terminal state ที่เป็น 0 ตลอดอยู่แล้ว
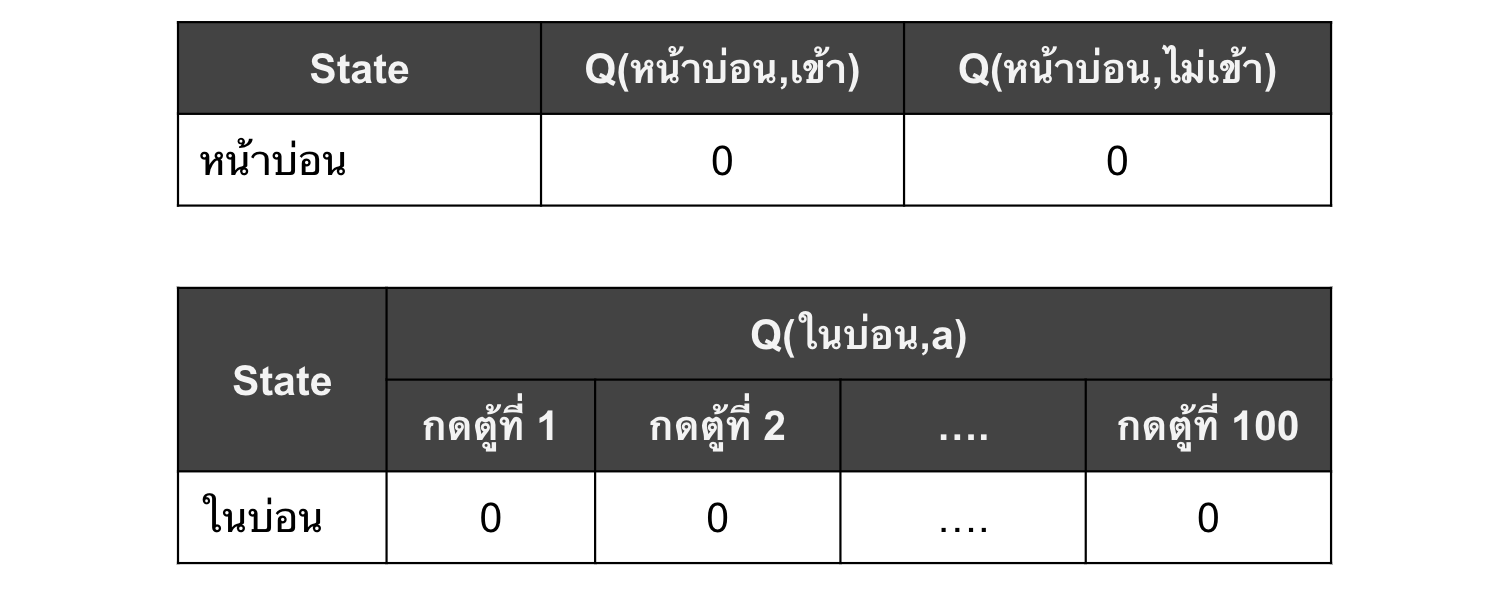
ปรากฎว่าเข้าไปครั้งแรก ด้วยความที่แบลงค์คันไม้คันมือเลยกดไปตู้แรกเลย และด้วยความที่โชคดีมาก ๆๆๆๆๆ (ๆ พันตัว) ได้เงินออกมา 100 บาทเลยทีเดียว “โอโห่!!! นี่เราเป็นเศรษฐีได้เลยนะเนี่ย (แบลงค์อุทานในใจ)”
เพราะฉะนั้น อย่ารอช้าเลย แบลงค์ผู้เคยเรียน Q-learning มาแล้ว จึงรีบจัดแจงนำประสบการณ์อันล้ำค่านี้ไปใส่ในตารางค่า Q ไว้ ซึ่งในอนาคตกำไรที่ใส่เข้าไปนี้จะถูกนำไป update ให้ Q(หน้าบ่อน, เข้าบ่อน)

แล้ววันนี้ก็จบไป แบลงค์กลับไปนอนกอดเงินอย่างมีความสุข
เปรียบได้กับการสิ้นสุด episode
หลังจากนั้น วันไหนว่าง ๆ ส่วนใหญ่แบลงค์ก็จะเข้าบ่อนแทนการไปที่อื่นเพราะนายแบลงค์คิดว่าบ่อนสร้างกำไรให้เค้าได้
ก็จะมีวันที่แบลงค์ไม่ไปเข้าบ่อนด้วย เปรียบเหมือน exploration แต่เราจะไม่พูดถึงวันที่นายแบลงค์ไม่ได้เข้าบ่อน เพราะว่า reward มันเป็น 0 อยู่แล้ว ตารางมันไม่เปลี่ยน
สมมติว่าหลังแบลงค์เข้าบ่อนไป 10 วัน ใน 10 วันนั้นก็จะกดตู้ที่ 1 ซะเป็นส่วนใหญ่ (เพราะเป็น optimal action มี Q ตั้ง 100 แหนะ) และก็ลองกดตู้อื่น ๆ บ้าง (exploration) ในการกดตู้ทั้งหมดนั้น ๆ ก็มีทั้งขาดทุนและกำไร และสมมติว่าผลของการกดตู้นั้น ทำให้ได้ค่า Q เป็นดังนี้

ซึ่งตอนที่แบลงค์คิดว่าจะเข้าบ่อนดีมั๊ย แบลงค์จะไม่สนใจตู้ที่เคยกดแล้วขาดทุนหรือได้กำไรน้อยกว่าเลย เพราะว่าแบลงค์เชื่อว่ามีตู้ที่กดแล้วได้กำไรมากที่สุดอยู่ (ตู้อื่นขาดทุน ช่างมัน ขอแค่ตู้เดียวให้กำไรก็พอ)
Q(หน้าบ่อน, เข้าบ่อน) ยังถูกอัพเดทด้วยค่า Q(ในบ่อน, กดตู้ที่ 1) อยู่ ซึ่งมันก็ทำให้แบลงค์ยังคงเข้าบ่อนอยู่เรื่อย ๆ เพราะค่า Q(ในบ่อน, กดตู้ที่ 1) มากกว่า 0 ซึ่งเป็น reward ของการไม่เข้าบ่อน แล้วค่านี้ก็ถูกโอนไปยัง Q(หน้าบ่อน, เข้าบ่อน)

ถ้าย้อนไปดูในสมการที่ \eqref{eq:Q} ตอนที่เรา update ค่า Q ของ state ปัจจุบันนั้น เรามีพจน์ $argmax(Q(s,a))$ ที่ทำให้เราสนใจแค่ค่า max ของ Q ใน state ถัดไปเท่านั้น
ซึ่งอันนี้ไม่ใช่ปัญหาเพราะมันก็ถูกในหลักการของ Q-learning แหละ เพราะว่า policy ใน Q learning นั้น เราไม่ได้สนใจ action อื่น ๆ ใน state นั้น เราสนใจแค่ action ที่ได้ Q มากที่สุดมา represent ค่าของ state นั้น ๆ ในการ update กลับไปยัง Q(s,a) ก่อนหน้า ยกตัวอย่างดังรูปด้านล่าง (เพื่อให้เห็นภาพชัด เราจะยกตัวอย่างซึ่งไม่เกี่ยวกับเรื่องที่กำลังเล่าอยู่)
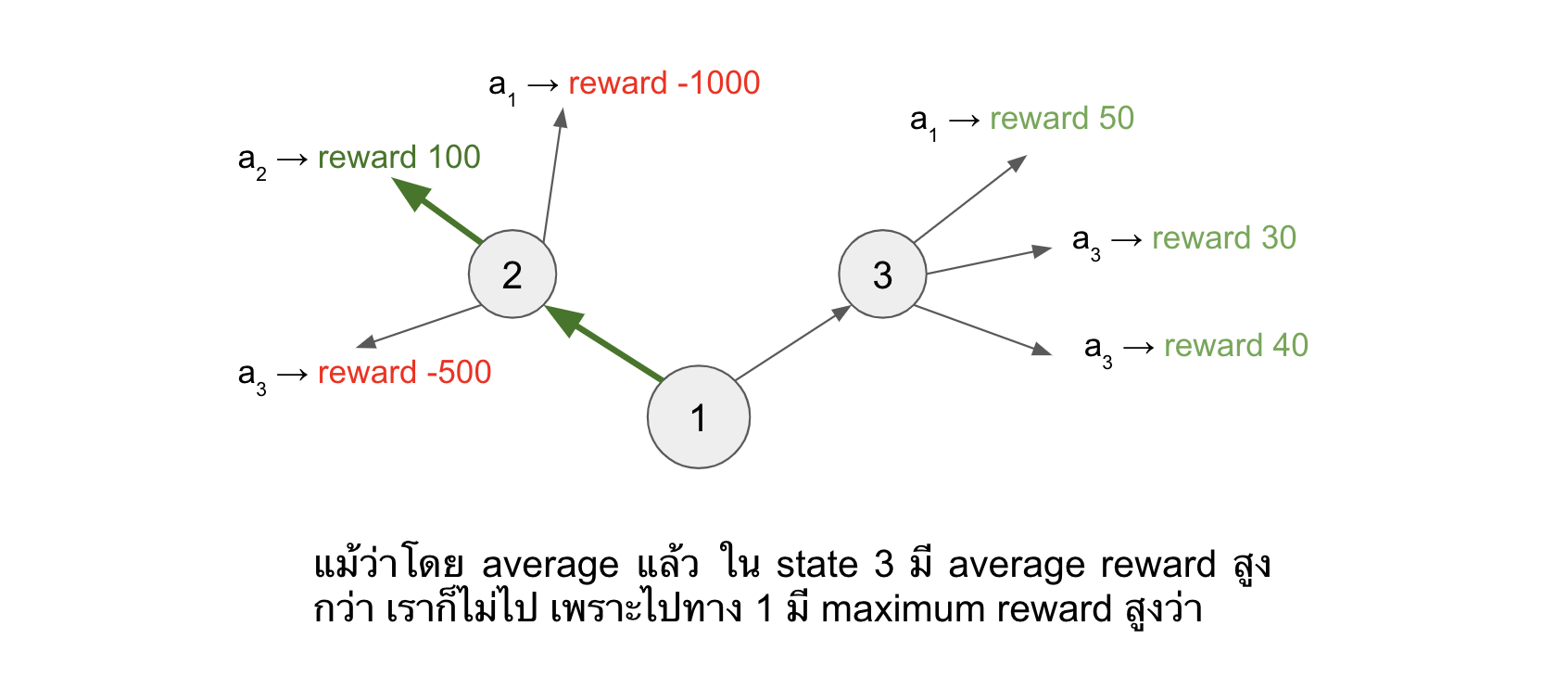
ผิดอย่างเดียวก็คือ การที่กดแล้วได้กำไรมาก่อนหน้านั้น แบลงค์แค่โชคดี แล้วดันคิดว่ามันเป็นค่ากำไรโดยเฉลี่ยจริง ๆ แล้วแบลงค์ก็เลยหลงผิดเข้าบ่อนเป็นประจำ
กลับมาในเรื่องที่กำลังเล่าอยู่ต่อ ถึงตอนนี้ค่า Q(ในบ่อน,กดตู้ที่ 1) ของแบลงค์ก็ยังสูงที่สุดและมากกว่า 0 อยู่ แบลงค์จึงยังคงเข้าบ่อนเรื่อย ๆ และกดตู้ที่ 1 เป็นส่วนใหญ่ กดไปเรื่อย ๆ กดไปหลาย ๆ ครั้ง ก็จะขาดทุนมากกว่ากำไรหน่อย ๆ (ตาม expected value) แบลงค์ก็พบว่าจริง ๆ แล้วที่กดได้กำไรเยอะ ๆ ในครั้งแรกนั้น มันฟลุ๊คคค!!! ซึ่งกว่าจะถึงตอนนั้น ค่า Q(ในบ่อน, กดตู้ที่1) มันก็จะลดลงมาเยอะแล้ว หรืออาจจะติดลบไปเลย (ลู่เข้าค่า expected value ของจริง)

แต่แบลงค์ก็ยังคงไม่หยุดแค่นั้น!! แบลงค์ย้อนไปดูในตาราง Q แล้วพบว่า “อ่าวเห้ยยยย!! ยังมีตู้อื่นที่กดแล้วกำไรอยู่นี่หว่าา”
อย่าลืมว่าก่อนหน้านี้แบลงค์ก็ลองกดตู้อื่น ๆ ด้วย ซึ่งด้วยความที่ตู้มันมีเยอะมากเนี่ย ทำให้ก็มีตู้ที่แบลงค์เคยกดแล้วกำไรเหมือนกัน (เช่น ตู้ที่ 3 และ 100)
เพราะฉะนั้นแล้ว ค่า Q(หน้าบ่อน, เข้าบ่อน) ก็จะได้รับอิทธิพลจากตู้อื่นที่ยังคงฟลุ๊คมีกำไรอยู่ดี
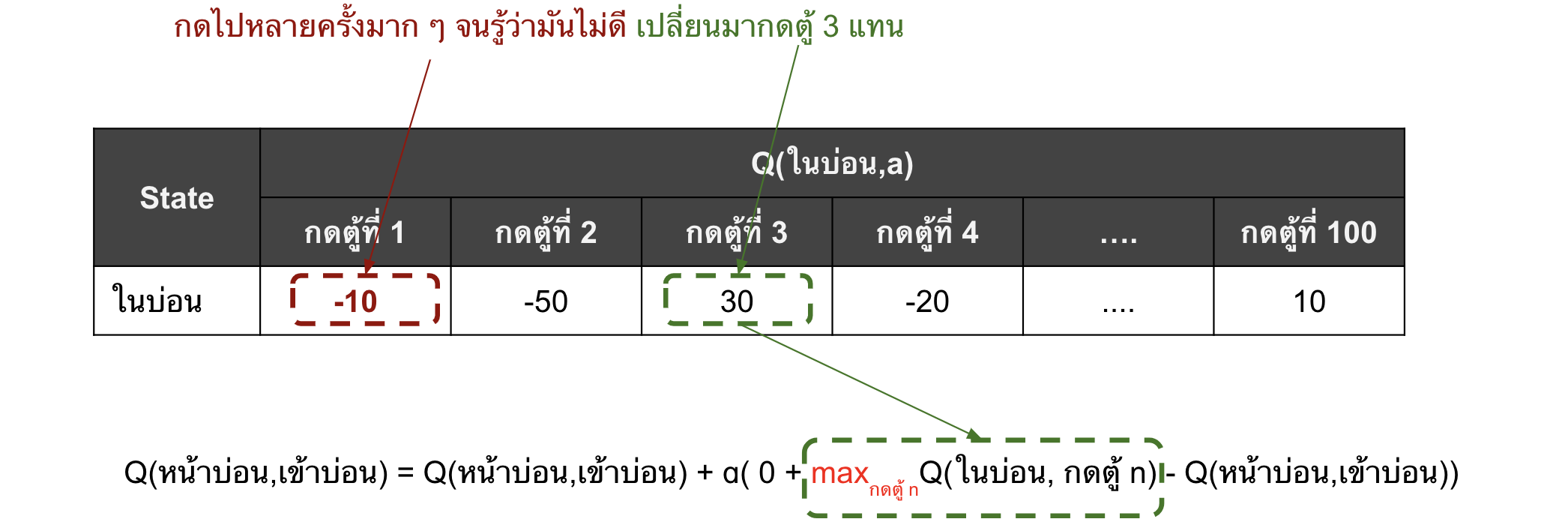
สิ่งที่เกิดขึ้นคือแบลงค์ก็จะยังไปบ่อนอยู่ดี แค่ว่าเปลี่ยนจากตู้ที่ 1 ไปกดตู้อื่นที่เคยกำไรแล้วก็กดไปเรื่อย ๆ จนพบว่าตู้นั้นจริง ๆ แล้วมันไม่มีกำไร แล้วก็วนไปตู้ใหม่ไปเรื่อย ๆ จนกว่าแบลงค์จะพบว่า การเข้าบ่อนนั้นไม่มีตู้ไหนเลยที่ทำให้ได้กำไร ถึงจะเลิกเข้าบ่อน
ซึ่งเสียเวลามาก แทนที่จะเอาเวลาไปทำอย่างอื่นซะตั้งแต่แรก แถมตังที่ตอนแรกกำไร สุดท้ายเอาไปหักลบกลบนี้กับการขาดทุนอีกหลายครั้ง กว่าจะรู้ว่าบ่อนไม่ได้ทำให้รวยก็หมด
ทั้งนี้ เรื่องทั้งหมดจะแทบไม่เกิดขึ้นเลย ถ้าหากว่า
แบลงค์มีเพื่อนคนนึงชื่อนัท (นามสมมติอีกเช่นกัน) ทั้งสองคนเป็นเพื่อนรักกัน ทั้งสองคนตกลงกันว่าจะช่วยกันเตือนเพื่อนถ้าเพื่อนกำลังหลงผิด
นัทเห็นแบลงค์เข้าบ่อนไป นัทเลยตามไปบ้างและกดตู้แรกเหมือนกัน ปรากฎว่านัทกลับไม่มีโชคเหมือนแบลงค์ นัทเสียสตางค์ไป 20 บาท (reward = -20)
วันถัดมาทั้งคู่มายืนอยู่หน้าบ่อนด้วยกัน แบลงค์บอกนัทว่า “นาย ๆ เราเข้าบ่อนกันเถอะ เมื่อวันนั้นเรากดตู้แรกได้ตั้ง 100 แหนะ เราแค่ต้องเข้าไปแล้วกดตู้แรกเท่านั้น” ทันใดนั้นเองนัทก็บอกว่า “อย่าเลยสหาย เมื่อวานชั้นขาดทุนจากการกดตู้แรก 20 บาทเชียวนะ”
หลักการคือ ขอแค่มีคนที่มีประสบการณ์ต่างกัน มาช่วยกันเตือน เราก็จะลดโอกาสในการ over optimistic กับ action ใด ๆ ได้
หลังจากนั้น นัทกับแบลงค์เลยเกิดข้อตกลงกันว่า เมื่อคนใดคนนึงคิดว่าจะทำอะไรจะให้อีกคนช่วยกันตรวจ ซึ่งก็เป็นดังนี้ เมื่อแบลงค์เป็นคนเลือกว่าจะทำอะไร นัทจะใช้ประสบการณ์ตัวเองในการบอกแบลงค์ให้ว่ามันดีหรือไม่ดี และในทางกลับกันเมื่อนัทเป็นคนเลือกว่าจะทำอะไร แบลงค์จะใช้ประสบการณ์ตัวเองในการบอกให้ว่ามันดีหรือไม่ดี
เพราะฉะนั้นแล้ว ก่อนที่แบลงค์จะเอาค่า Q ของ action ที่ตัวเองคิดว่าดีที่สุด ไป update ค่า Q ให้ state ก่อนหน้า แบลงค์จะมาถามนัทก่อนเสมอว่ามันดีขนาดไหน แล้วค่อยเอาคำตอบของนัทไป update ค่า Q ให้ state ก่อนหน้า
ถ้าจากประสบการณ์ทั้งสองคนบอกว่าดี ก็แปลว่าอาจจะดีจริง ๆ (โอกาสที่จะฟลุ๊คโชคดีทั้งสองคนมันยากกว่าฟลุ๊คแค่คนเดียว)
จบบริบูรณ์
Double Q-learning
ซึ่งแนวคิดนี้ ก่อให้เกิด idea ของ double Q-learning ซึ่งเป็น Q learning ที่มี Q table สองตาราง โดยที่ทั้งสองตารางนั้นจะถูกสร้างมาด้วย experience ที่แตกต่างกัน เพื่อให้เกิดการเตือนกันได้ (ถ้ารับรู้มาเหมือน ๆ กันหมด จะเตือนกันยังไง) โดยที่เปลี่ยนแปลงจาก Q-learning ดั้งเดิมดังนี้
- การเลือก action นั้น เราจะนำ $Q_1 + Q_2$ แล้วค่อยเลือก เพื่อเป็นการขอความเห็นของทั้ง 2 ฝ่าย
- ในตอนอัพเดทค่า Q นั้น เราจะสุ่มว่าจะอัพเดทค่า Q ในตารางไหน และใช้สมการด้านล่างแทน
\begin{equation}
\label{eq:doubleQ}
\definecolor{energy}{RGB}{230,10,0}
Q_1(s,a) \leftarrow Q_1(s,a) + \alpha (r + {\color{energy}Q_2(s,argmax(Q_1(s’,a)))} - Q_1(s,a))
\end{equation}
- จะเห็นได้ว่าเมื่อเราจะอัพเดท $Q_1$ นั้น
- เราใช้ $Q_1$ ในการเลือก optimal action ของ next state ($argmax_a Q_1(s’,a)$)
- แต่เราใช้ ค่า $Q$ ของ state และ optimal action (ที่ $Q_1$ เลือกมา) จากตาราง $Q_2$ เหมือนเป็นการให้ $Q_2$ ช่วยยืนยันอีกทีว่า action ที่ $Q_1$ เลือกมา ดีจริง ๆ รึเปล่า ถ้าไม่ดีก็ปรับซะเลย เพราะค่าที่ $Q_2$ ให้มามันจะน้อย มันก็จะไปอัพเดทค่า $Q_1(s,a)$ นี้ให้น้อยลงไปด้วย
- จะเห็นได้ว่าเมื่อเราจะอัพเดท $Q_1$ นั้น
 Ref: Reinforcement Learning: an Introduction (Andrew Barto and Richard S. Sutton)
Ref: Reinforcement Learning: an Introduction (Andrew Barto and Richard S. Sutton)
สำหรับโค้ดตามที่ link นี้ได้เลยจ้า คิดว่าไม่ซับซ้อนเท่าไหร่ เลยอาจจะยังไม่อธิบาย ไว้ถ้าว่าง ๆ จะมาเติมให้จ้า
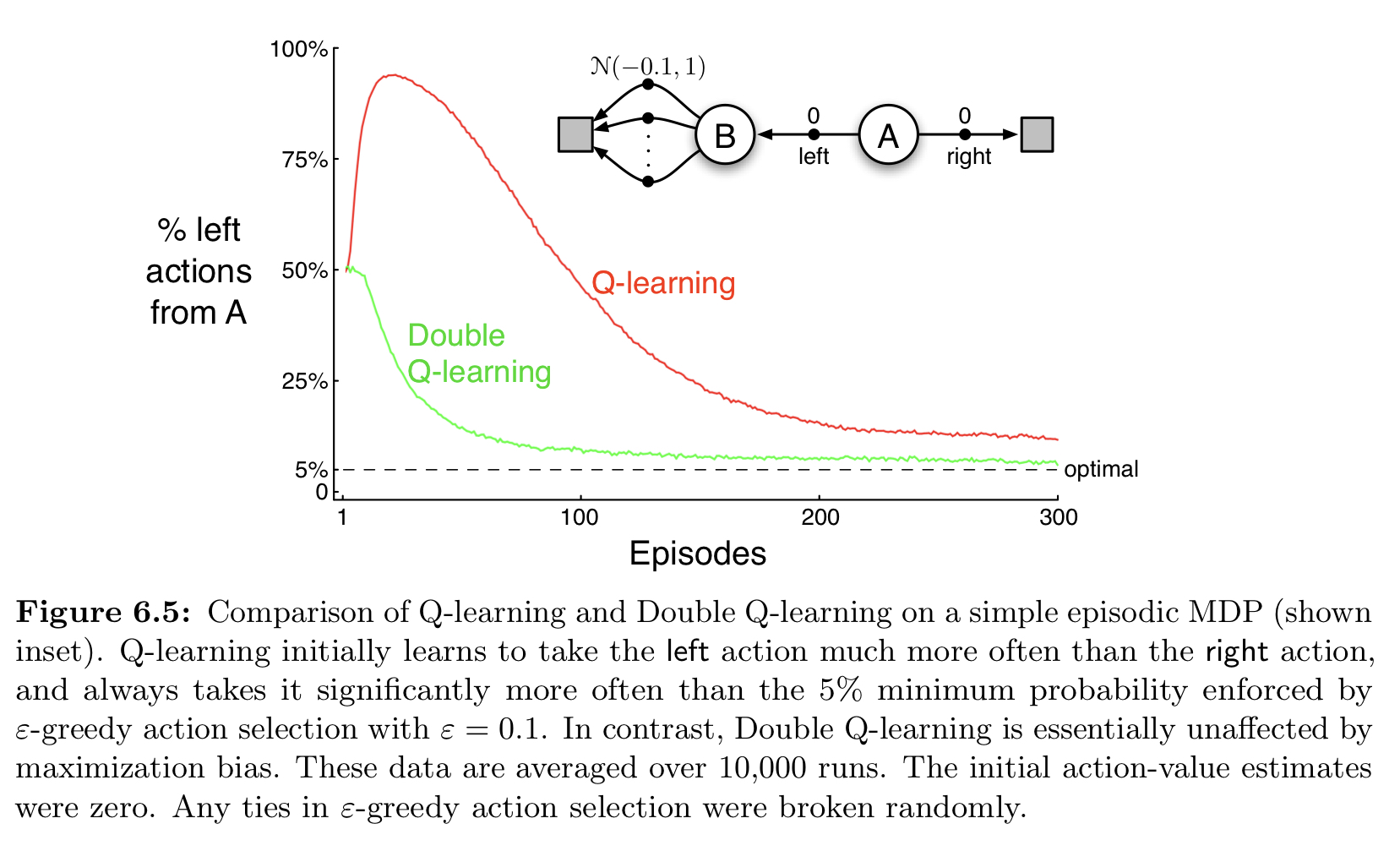
ซึ่งในหนังสือเนี่ย เค้าก็ทดลองด้วย environment ที่เราอธิบายไปเลยเด๊ะ ๆ แล้วเค้าก็พบว่าการที่เราใช้ Q-learning แบบธรรมดาเนี่ย ช่วงแรก ๆ มันจะเสียเวลาไปกับการเข้าบ่อนซะเยอะะะ (เห็นได้ว่า ratio การเลือก action left ของเส้นสีแดงนี่พุงขึ้นมาเชียว โดนความฟลุ๊คหลอกเข้าให้) ในขณะที่ double Q-learning นั้นเริ่มมาก็ไต่ลงเลย หรือก็คือ double Q-learning นั้นสามารถรู้ได้ก่อนว่าไม่เข้าบ่อนน่ะ ดีที่สุด
 Ref: Reinforcement Learning: an Introduction (Andrew Barto and Richard S. Sutton)
Ref: Reinforcement Learning: an Introduction (Andrew Barto and Richard S. Sutton)