-
หลาย ๆ คนอาจจะเคยพยายามใช้ LLM ในการ extract information บางอย่างออกมาจาก free text ซึ่งส่วนใหญ๋เราก็น่าจะต้องการให้ LLM มันตอบออกมาเป็น format ที่เป็นระเบียบเหมือนกันทุกครั้ง เช่น อยากให้ LLM ตอบออกมาเป็น JSON ที่มี structure ตามที่เรากำหนด เราจะได้เอาไปทำงานต่อได้ง่าย
-
วิธีแรก ๆ ที่ทุกคนพยายามทำอาจจะเป็นการพยายาม prompt ให้มันเก็ตเราว่าเราต้องการ output แบบนี้นะอะไรแบบนี้
-
ซึ่งเท่าที่ลองมันก็เวิร์คอยู่กับพวก LLM ที่ฉลาด ๆ หน่อย เช่น ChatGPT หรือ Claude Sonet ตามรูปด้านล่าง
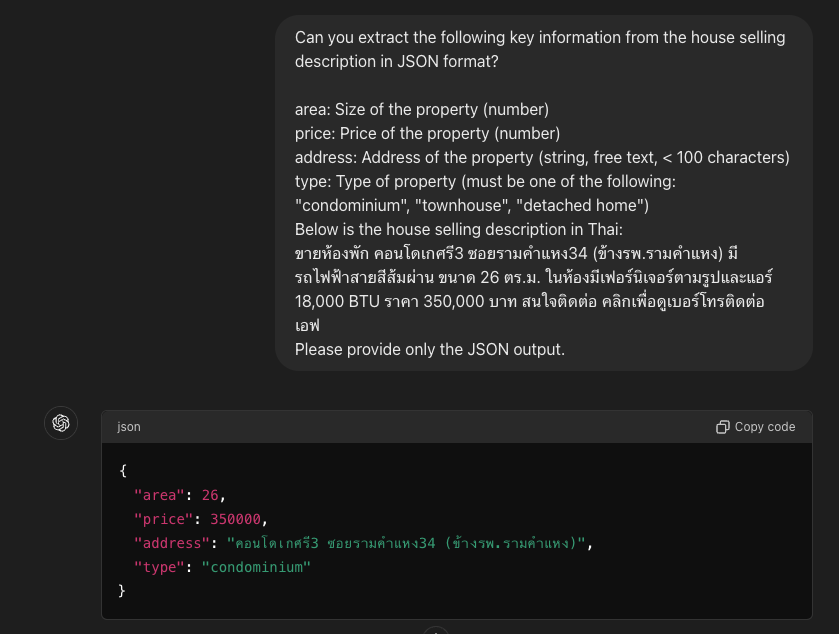
- แต่เผอิญว่าวันก่อนลองเอาพวก opensource model ที่ตัวไม่ใหญ่มาก ที่คนธรรมดาอย่างเราน่าจะพอเล่นกันได้แบบ llama3 8b มาลองใช้ดู ผ่าน llama.cpp เพราะว่าเผื่อจะได้ใช้ได้ฟรีบนเครื่องเราเองไรงี้ ปรากฏว่ามันมีครั้งที่ตอบตรง format และไม่ตรง format อยู่บ้าง หรือบางทีก็ให้ json ออกมาตรงแต่มีของแถมเต็มไปหมด (ที่จริงอาจจะเป็นที่ผม prompt ไม่เก่งด้วยป่าวหว่า TT)
- เลยลองค้น ๆ ดู ปรากฏว่า ที่จริงมันมีวิธีทำอยู่เหมือนกันแฮะ วิธีที่เราสามารถบังคับมันได้ว่า อยากได้ result ที่มี structure แบบที่กำหนดไว้เท่านั้น
- ซึ่งวิธีที่เจอเนี่่ย ต้องทำด้วยการใช้ llama.cpp ในการ inference พวก llm ซึ่งมันจะสามารถ parse argument ที่ชื่อว่า
grammarเข้าไปได้ - โดยที่ grammar นั้นมันจะเป็น text (ถ้าเซฟลงไฟล์มักจะอยู่ใน
.gbnf) ที่ระบุว่า format ของผลลัพธ์ที่เราต้องการมันต้องเป็นแบบไหน ซึ่งมันจะทำหน้าที่เป็นเหมือน constraint เวลา LLM generate output ว่า output ต้องมี format เป็นไปตามไฟล์ grammar เท่านั้นนะะ -
ด้านล่างคือตัวอย่าง grammar สำหรับ general json ซึ่งเป็นตัวอย่างที่เอามาจาก repo ของ llama.cpp นี่แหละ
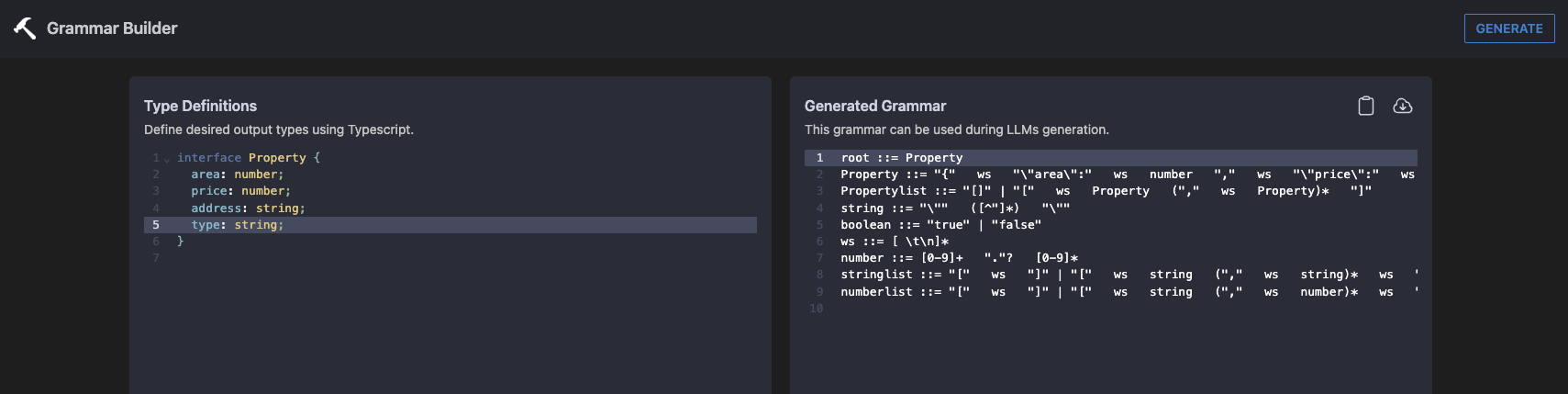
root ::= object value ::= object | array | string | number | ("true" | "false" | "null") ws object ::= "{" ws ( string ":" ws value ("," ws string ":" ws value)* )? "}" ws array ::= "[" ws ( value ("," ws value)* )? "]" ws string ::= "\"" ( [^"\\\x7F\x00-\x1F] | "\\" (["\\bfnrt] | "u" [0-9a-fA-F]{4}) # escapes )* "\"" ws number ::= ("-"? ([0-9] | [1-9] [0-9]{0,15})) ("." [0-9]+)? ([eE] [-+]? [0-9] [1-9]{0,15})? ws # Optional space: by convention, applied in this grammar after literal chars when allowed ws ::= | " " | "\n" [ \t]{0,20} - จะเห็นได้ว่าอ่านยากเหมือนกันแฮะ แล้วเราจะเขียน grammar ของเราได้ยังไงหว่า แต่ว่าเรามีตัวช่วยก็คือเว็บ https://grammar.intrinsiclabs.ai/
-
โดยใช้แบบตัวอย่างในภาพด้านล่าง
-
จากนั้นก๊อป grammar มาเลยก็ได้ แล้วใช้ code ด้านล่างในการลอง inference ดูจ้า ใช้ lib นี้เด้อ
from llama_cpp import Llama, LlamaGrammar llm = Llama(model_path="../llama.cpp/models/llama3-8b/ggml-model-f16.gguf") prompt = ''' Can you extract the following key information from the house selling description in JSON format? - area: Size of the property (number) - price: Price of the property (number) - address: Address of the property (string, free text, < 100 characters) - type: Type of property (must be one of the following: "condominium", "townhouse", "detached home") Below is the house selling description in Thai: --- ขายห้องพัก คอนโดเกศรี3 ซอยรามคำแหง34 (ข้างรพ.รามคำแหง) มีรถไฟฟ้าสายสีส้มผ่าน ขนาด 26 ตร.ม. ในห้องมีเฟอร์นิเจอร์ตามรูปและแอร์ 18,000 BTU ราคา 350,000 บาท สนใจติดต่อ คลิกเพื่อดูเบอร์โทรติดต่อ เอฟ --- Please provide only the JSON output. ''' grammar = r''' root ::= Property Property ::= "{" ws "\"area\":" ws number "," ws "\"price\":" ws number "," ws "\"type\":" ws string "," ws "\"address\":" ws string "}" Propertylist ::= "[]" | "[" ws Property ("," ws Property)* "]" string ::= "\"" ([^"]*) "\"" boolean ::= "true" | "false" ws ::= [ \t\n]* number ::= [0-9]+ "."? [0-9]* stringlist ::= "[" ws "]" | "[" ws string ("," ws string)* ws "]" numberlist ::= "[" ws "]" | "[" ws string ("," ws number)* ws "]" ''' grammar = LlamaGrammar.from_string(grammar=grammar, verbose=False) response = llm( prompt, grammar=grammar, # Add the grammar constraint with the LlamaGrammar object max_tokens=-1 ) print(result['response'][0]['text']) ### Output ### {"area":26,"price":35000,"address":"ขายห้องพัก คอนโดเกศรี3 ซอยรามคำแหง34 (ข้างรพ.รามคำแหง)","type":"condominium"} - ซึ่งจากที่ลองถามมันย้ำ ๆ อยู่ประมาณ 20-30 ครั้ง มันก็ให้ output ที่เราสามารถไปใช้ json.loads ได้ทุกครั้งเลย เย้ (แต่เข้าใจว่าจริง ๆ แล้วมันไม่น่าจะ 100% ที่จะได้ผลลัพธ์ตรงตาม format ที่ต้องการล้วน ๆ อันนี้อาจจะฟลุ๊ค)
- โดยที่ก็เพิ่งมารู้ตอนหลังว่าถ้าใช้ lib llama-cpp-python อยู่แล้ว เราสามารถกำหนด format json แบบง่าย ๆ ได้เลย โดยที่ไม่ได้ต้องไปแปลงในเว็บที่บอกก่อนหน้า ดังตัวอย่างด้านล่าง
from llama_cpp import Llama, LlamaGrammar llm = Llama(model_path="../llama.cpp/models/llama3-8b/ggml-model-f16.gguf") response = llm.create_chat_completion( messages=[ { "role": "system", "content": "You are a helpful assistant that extract the information and outputs in JSON.", }, {"role": "user", "content": ''' Can you extract the following key information from the house selling description in JSON format? - area: Size of the property (number) - price: Price of the property (number) - address: Address of the property (string, free text, < 100 characters) - type: Type of property (must be one of the following: "condominium", "townhouse", "detached home") Below is the house selling description in Thai: --- ขายห้องพัก คอนโดเกศรี3 ซอยรามคำแหง34 (ข้างรพ.รามคำแหง) มีรถไฟฟ้าสายสีส้มผ่าน ขนาด 26 ตร.ม. ในห้องมีเฟอร์นิเจอร์ตามรูปและแอร์ 18,000 BTU ราคา 350,000 บาท สนใจติดต่อ คลิกเพื่อดูเบอร์โทรติดต่อ เอฟ --- Please provide only the JSON output. ''' }, ], response_format={ "type": "json_object", "schema": { "type": "object", "properties": { "area": {"type": "number"}, "price": {"type": "number"}, "address": {"type": "string"}, "type": {"type": "string"}, }, "required": ["area","price","address","type"], }, }, temperature=0.7 ) print(response['choices'][0]['message']['content']) ### Output ### '{"area":26,"price":35000,"address":"คอนโดเกศรี3 ซอยรามคำแหง34 (ข้างรพ.รามคำแหง)","type":"condominium"}' - แต่่ๆๆๆๆๆๆๆ รู้สึกว่ามันช้ากว่าเดิมมาก ซึ่งถ้าดูจาก output ของ llama.cpp ที่ให้มาตอน inference ถ้าตอนที่เราถามมันแบบไม่ใส่ grammar ให้มัน มันตอบไวฉับ ๆ เลย (ประมาณ 1-2 วิตอบละ) แต่พอใส่ grammar ไปกว่ามันจะตอบน่าจะประมาณ 8-10 วิได้ TT