จาก A/B Testing ไปสู่ Uplift modelling
- เวลาเราจะออกแคมเปญอะไรหรือต้องการจะแก้ไขบางจุดในสินค้าหรือการบริการเรา (ในบทความนี้จะเรียกการทำพวกนี้ว่า treatment) แต่เราไม่มั่นใจว่าถ้าทำไปมันจะดีขนาดไหน (effect เป็นยังไง) เราอาจจะเริ่มด้วยการทำทดลองแบบ A/B testing
- ซึ่งการทำ A/B testing นั้น จะเป็นการแบ่งกลุ่มผู้ใช้งานออกเป็นสองกลุ่มแบบสุ่ม แล้วก็ให้กลุ่มนึงได้รับ treatment (ในบทความนี้จะเรียกว่า treatment group) และอีกกลุ่มไม่ได้รับ (เรียกว่า control group) เช่น
- กลุ่มนึงอาจจะได้รับการอัพเดท UI เป็นแบบใหม่ อีกกลุ่มอาจจะใช้ UI แบบเดิมไปก่อน แล้วก็มาดูกันว่ากลุ่มไหนที่มีจำนวนครั้งที่เข้ามาใช้งานโดยรวมมากกว่า
- หรือถ้าเป็น e-commerce ก็อาจจะเป็นกลุ่มไหนที่มีจำนวนครั้งการซื้อโดยรวมมากกว่า แล้วที่บอกว่ามากกว่านั้นมัน significant รึเปล่า
- จะเห็นว่าในตัวอย่างข้างบนนั้นเราเน้นคำว่า “โดยรวม” เนื่องจากการทำ AB testing นั้น ทำให้เรารู้ได้ว่าผลลัพธ์แบบมวลรวมหรือองค์รวมของประชากร user เราเนี่ย ตอบสนองกับ treatment ที่เราทำยังไง เช่น โดยเฉลี่ยแล้วลูกค้าที่ได้รับ treatment (ซึ่งอาจจะเป็นการรปรับ UI แบบใหม่ หรือการให้ promotion) จะซื้อสินค้าเรามากกว่ากลุ่มที่ไม่ได้รับ
- ซึ่งข้อจำกัดของ A/B testing ก็จะอยู่ที่คำว่า “โดยรวม” นี่แหละ ตัวอย่างเช่น สมมติว่า AB testing ให้ผลออกมาว่า “โดยรวมจาก user หลาย ๆ คนแล้ว treatment ไม่มี effect อะไร” จริง ๆ แล้วมันอาจจะเป็นได้สองแบบ ก็คือ
- user ทุกคนไม่แคร์อะไรกะ treatment นี้ เช่น เปลี่ยน UI หรือไม่เปลี่ยนก็ใช้เว็บเท่าเดิมอยู่ดี
- user บางคนชอบ และบางคนเกลียด treatment นี้ เช่น คนที่ชอบก็ใช้เยอะขึ้น (+1) ส่วนคนที่เกลียดก็ใช้น้อยลง (-1) พอเอามาเฉลี่ยกันมันเลยดูเท่าเดิม ((+1-1)/2) = 0
- ซึ่งถ้าเป็นภาษาทางการหน่อยจะกล่าวได้ว่า A/B testing สามารถบอก average treatment effect (ATE) ได้ แต่ว่าไม่สามารถบ่งบอก conditional average treatment effect (CATE) ได้
- ขยายความ ATE กับ CATE ซักหน่อย
-
ตัว ATE ถ้าเขียนเป็นสมการทางคณิตศาสตร์จะได้แบบนี้
\begin{equation} \label{eq:ate} ATE = {\color{blue}\mathbb{E}}[{\color{green}Y^1} - {\color{red}Y^0}] \end{equation}
- มันคือค่าเฉลี่ยของความแตกต่างระหว่าง outcome ของคนที่ได้รับ treatment และคนที่ไม่ได้รับ treatment
-
ตัว CATE ถ้าเขียนเป็นสมการทางคณิตศาสตร์จะได้แบบนี้
\begin{equation} \label{eq:cate} CATE = {\color{blue}\mathbb{E}}[{\color{green}Y^1} - {\color{red}Y^0}|\color{brown}{X=x}] \end{equation}
- มันคือค่าเฉลี่ยของความแตกต่างระหว่าง outcome ของคนที่ได้รับ treatment และคนที่ไม่ได้รับ treatment ของคนที่ตรงตาม condition ที่กำหนดไว้ เช่น เป็นผู้ชาย, อายุ 20-30 ปี, มีรายได้มากกว่า 2 หมื่นบาท, บ้านอยู่กรุงเทพ etc.
- หรือถ้าพูดอีกอย่างก็คือตัว CATE มันจะ personalized มากกว่า ATE นั่นเอง เราสามารถรู้ได้ว่าลูกค้าคนนี้ชอบ treatment นี้ ลูกค้าคนนั้นไม่ชอบ treatment นี้ เพื่อเลือกส่ง treatment เป็นรายคนได้ เช่น ลูกค้าคนนึงอาจจะชอบให้โทรไปแนะนำโปรมือถือบ่อย ๆ อีกคนอาจจะไม่ชอบ เราก็จะได้เลือกโทรแค่คนที่จะชอบเท่านั้น
-
- โดยที่ในบทความนี้จะกล่าวถึงการพยายามประมาณค่า CATE ของ user หรือลูกค้าแต่ละคนด้วยการใช้ machine learning ซึ่งเป็นวิธีที่เรียกกันว่า Uplift Modelling ซึ่งจะเป็นวิธีการที่พยายามจะทำนาย outcome ของ user หรือลูกค้าแต่ละคนในกรณีที่ได้รับและไม่ได้รับ treatment
-
ซึ่งด้วย uplift model นี้จะทำให้เราสามารถแบ่งกลุ่มของลูกค้าหรือผู้รับบริการของเราออกเป็น 4 กลุ่ม ได้แก่
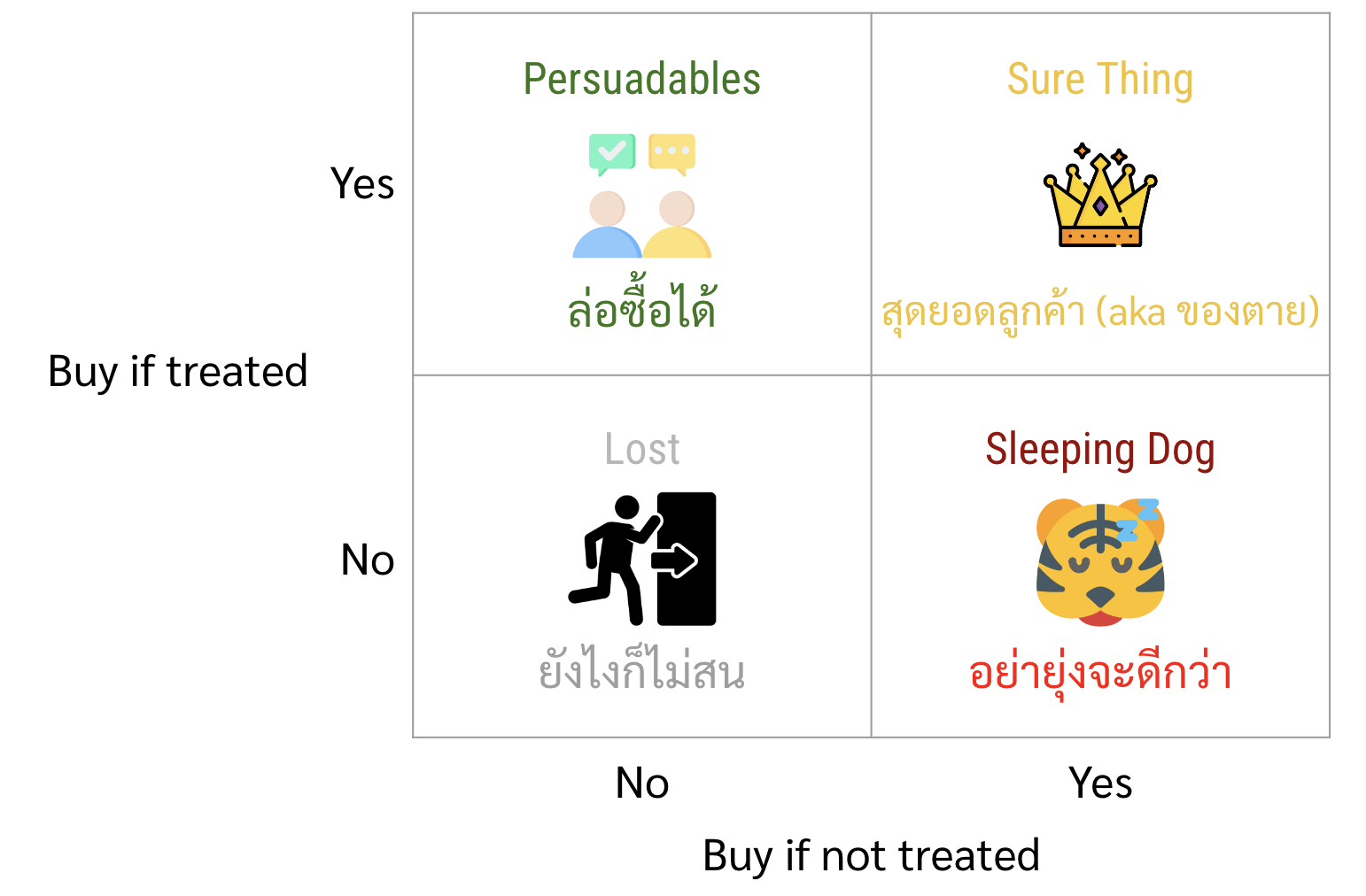
- Persuadable: กลุ่มที่ถ้าอยู่เฉย ๆ ไม่ซื้อ แต่ถ้าเราให้ treatment ไปจะซื้อ → กลุ่มนี้เป็นกลุ่มที่ควรให้ treatment หรือ promotion ที่สุด
- Sure things: กลุ่มที่ไม่ว่าจะให้หรือไม่ให้ treatment ก็ซื้ออยู่แล้ว
- Sleeping dogs: กลุ่มที่จะซื้ออยู่แล้ว แต่ถ้าเราให้ treatment ไปแล้วจะไม่ซื้อ
- Lost causes: ไม่ซื้ออยู่แล้วไม่ว่าจะให้ treatment รึเปล่า → กลุ่มนี้ไม่ต้องให้ promotion ก็ได้
แล้วข้อมูลแบบไหนถึงจะเอามาทำ uplift model ได้
การเก็บข้อมูลเพื่อมาทำ uplift modelling ให้แม่นยำที่สุดนั้นจะต้องคำนึงถึงคุณสมบัติต่าง ๆ ดังด้านล่าง
- Exchangeability
- กลุ่มคนที่ได้รับ treatment และกลุ่มคนที่ไม่ได้รับต้องลักษณะเหมือน ๆ กัน หรือมาจาก population เดียวกัน
- Positivity
- ลูกค้าทุกคนใน population ที่เราสนใจมีสิทธิได้รับ treatment เท่าเทียมกัน จะไม่มีกลุ่มไหนเลยที่ไม่มีโอกาสรับ treatment เลย หรือไม่มีกลุ่มไหนเลยที่มีโอกาสได้รับ treatment ตลอด ยกเว้นกลุ่มที่เราไม่ได้สนใจก็เอาออกไปได้ เช่น
- เราบอกว่า เราจะเทส promotion นี้กับลูกค้าผู้หญิง (population คือลูกค้าผู้หญิงทั้งหมด)
- ผู้หญิงอาจจะแบ่งเป็นหลายกลุ่มอีก เช่น แบ่งตามการเป็นลูกค้าประจำ แบ่งตามช่วงอายุ etc. ในทุก ๆ กลุ่มนั้นจะต้องมีทั้งคนที่ได้รับ และไม่ได้รับ treatment
- ลูกค้าทุกคนใน population ที่เราสนใจมีสิทธิได้รับ treatment เท่าเทียมกัน จะไม่มีกลุ่มไหนเลยที่ไม่มีโอกาสรับ treatment เลย หรือไม่มีกลุ่มไหนเลยที่มีโอกาสได้รับ treatment ตลอด ยกเว้นกลุ่มที่เราไม่ได้สนใจก็เอาออกไปได้ เช่น
- Consistency
- มองเป็นจักรวาลคู่ขนานเหมือน marvel ก็ได้ ว่าถ้าในจักรวาลแรกและจักรวาลที่สองลูกค้าคนเดิมได้รับ treatment เดียวกัน เค้าควรจะตอบรับกับ treatment นั้นเหมือนเดิม
- ซึ่งแอบเทสยากอยู่นะคิดว่า
- No Interference
- ไม่ควรจะมีอุปสรรคหรือปัจจัยอื่นที่ส่งผลกระทบต่อ outcome เช่น
- จริง ๆ ลูกค้าคนนึงที่ได้รับ treatment ไปอยากซื้อสินค้าเรานะ แต่ของหมด ซื้อไม่ได้
- ได้รับการอัพเดท UI แล้วอยากเข้ามาเล่นแอปนะ แต่แอปล่ม เข้าไม่ได้
- ไม่ควรจะมีอุปสรรคหรือปัจจัยอื่นที่ส่งผลกระทบต่อ outcome เช่น
ประเภท Uplift Model
S-Learner
-
อันนี้ง่ายสุดเลย ก็คือใช้ ml model ตัวไหนก็ได้ เช่น random forest, logistic regression, xgboost ให้ทำนาย outcome จากฟีเจอร์ $X$ และ treatment $T$ (ก็คือเราใส่ฟีเจอร์ว่าคน ๆ นั้นได้รับ treatment เช่น promotion รึเปล่า โดยค่าของฟีเจอร์นี้อาจจะเป็น 1 หรือ 0 แทนการได้รับหรือไม่ได้รับไปเป็นฟีเจอร์ในโมเดลด้วยเลย)
\begin{equation} \label{eq:slearner} \mu(x,t) = {\color{blue}\mathbb{E}}[{\color{green}Y}|\color{brown}{X=x}, \color{purple}{T=t}] \end{equation}
-
ตอนเอาไปใช้กับลูกค้าคนใหม่ที่มีข้อมูลอื่น ๆ ของเค้า เช่น เพศ อายุ เราก็จะ inference โมเดลเดิมสองครั้ง โดย ครั้งแรกเราจะให้ฟีเจอร์ treatment เป็น 1 และอีกครั้งเป็น 0 จากนั้นเอาค่าการ inference สองครั้งมาลบกันก็จะได้ CATE ของลูกค้าคนนั้น หรือค่าที่บ่งบอกว่าลูกค้าคนนั้นจะซื้อของเยอะขึ้นประมาณเท่าไหร่ถ้าได้รับ promotion
\begin{equation} \label{eq:slearner_predict} {\color{brown}\tau(x)} = {\color{green}\mu(x,1)} - {\color{red}\mu(x,0)} \end{equation}
- ตัวอย่างเช่น สมมติว่าถ้าค่ามันติดลบ แสดงว่าลูกค้าคนนั้นเป็น sleeping dog (เพราะว่าถ้าไม่ได้ treatment อาจจะซื้อเยอะกว่าได้ treatment ซะอีก)
-
ซึ่งถ้าแสดงเป็นรูปก็จะได้แบบด้านล่าง
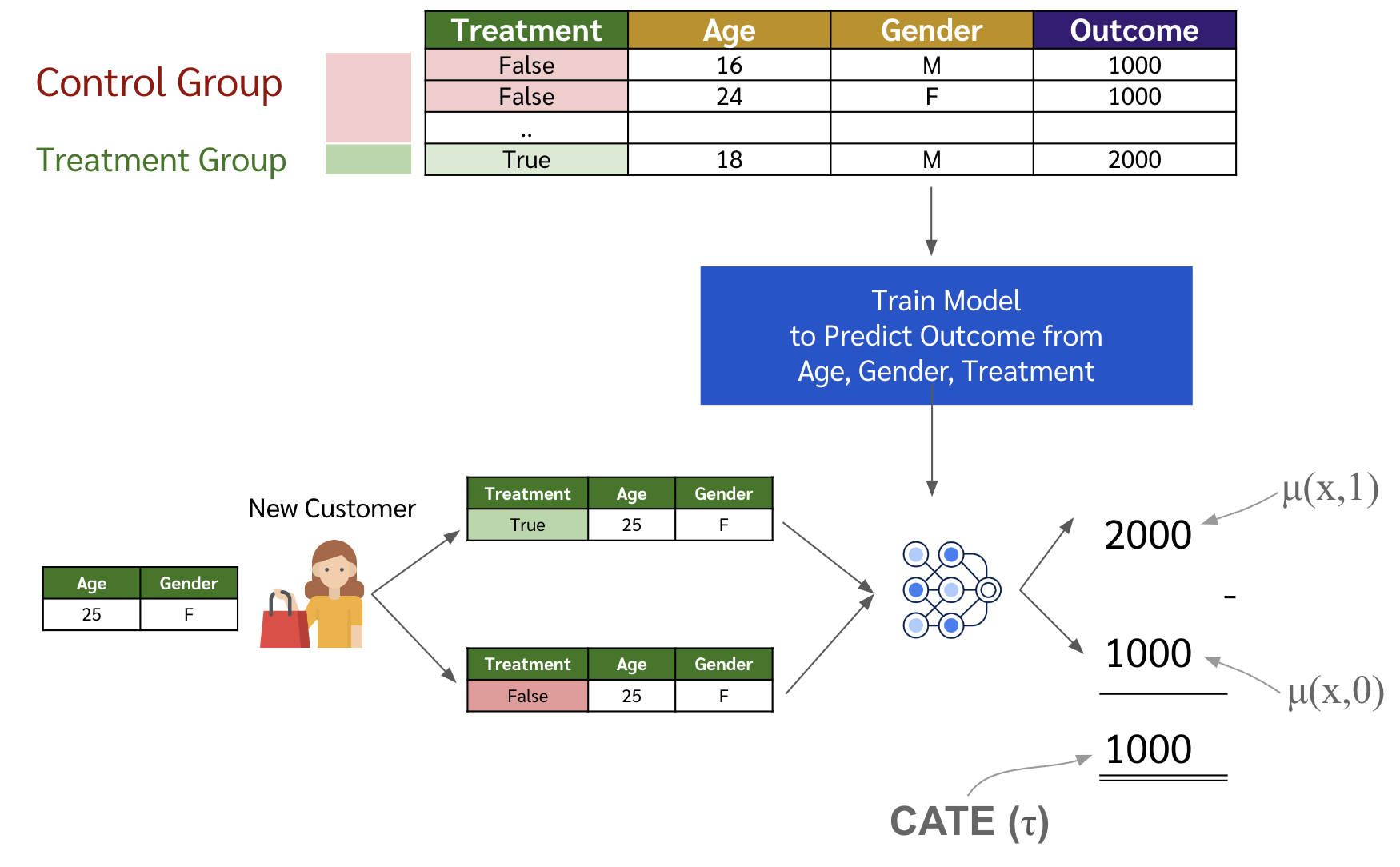
- ทีนี้ข้อเสียมันก็จะอยู่ที่ว่า โดยส่วนใหญ่แล้วตัว effect ของ treatment มันอาจจะไม่ได้เยอะมากขนาดนั้น พอเราทำโมเดลแบบนี้มันก็อาจจะมองข้าม treatment feature ไปโดยปริยาย เช่น ถ้าเป็น random forest ก็อาจจะไม่ได้หยิบฟีเจอร์ว่าได้รับ treatment รึเปล่ามาเป็น node เลยก็ได้
Two Learner (T-Learner)
- เค้าก็เลยเสนอการแก้ปัญหาด้วยการใช้ T-Learner โดยที่ใน T-Learner เนี่ย เราจะเอาการได้รับ treatment ออกจากฟีเจอร์ไปเลย
- แล้วเราจะแบ่งข้อมูลออกเป็นสองกลุ่มได้แก่ กลุ่มที่ได้รับ treatment และกลุ่มที่ไม่ได้รับ
- จากนั้นก็ train โมเดลที่ predict outcome โดยใช้ข้อมูลจากแต่ละกลุ่ม โดยที่
-
โมเดลแรกใช้ข้อมูลคนที่ได้รับ treatment เท่านั้น
\begin{equation} \label{eq:tlearner-1} \mu_{\color{green}1}(x) = \mathbb{E}[{\color{green}Y^1}|X=x] \end{equation}
-
โมเดลที่สองใช้ข้อมูลคนที่ไม่ได้รับ treatment เท่านั้น
\begin{equation} \label{eq:tlearner-0} \mu_{\color{red}0}(x) = \mathbb{E}[{\color{red}Y^0}|X=x] \end{equation}
-
-
จากนั้นพอเราจะเอาโมเดลไปใช้กับลูกค้าคนใหม่ เราก็เอาลูกค้าคนนั้นไปผ่าน 2 โมเดล แล้วเอาผลลัพธ์จากโมเดลแรกลบผลลัพธ์จากโมเดลที่ 2 เราก็จะได้ CATE ของลูกค้าคนนั้น
\begin{equation} \label{eq:tlearner_predict} \tau(x) = \mu_{\color{green}1}(x) - \mu_{\color{red}0}(x) \end{equation}
-
หรือถ้าแสดงเป็นรูปก็แบบนี้จ้า
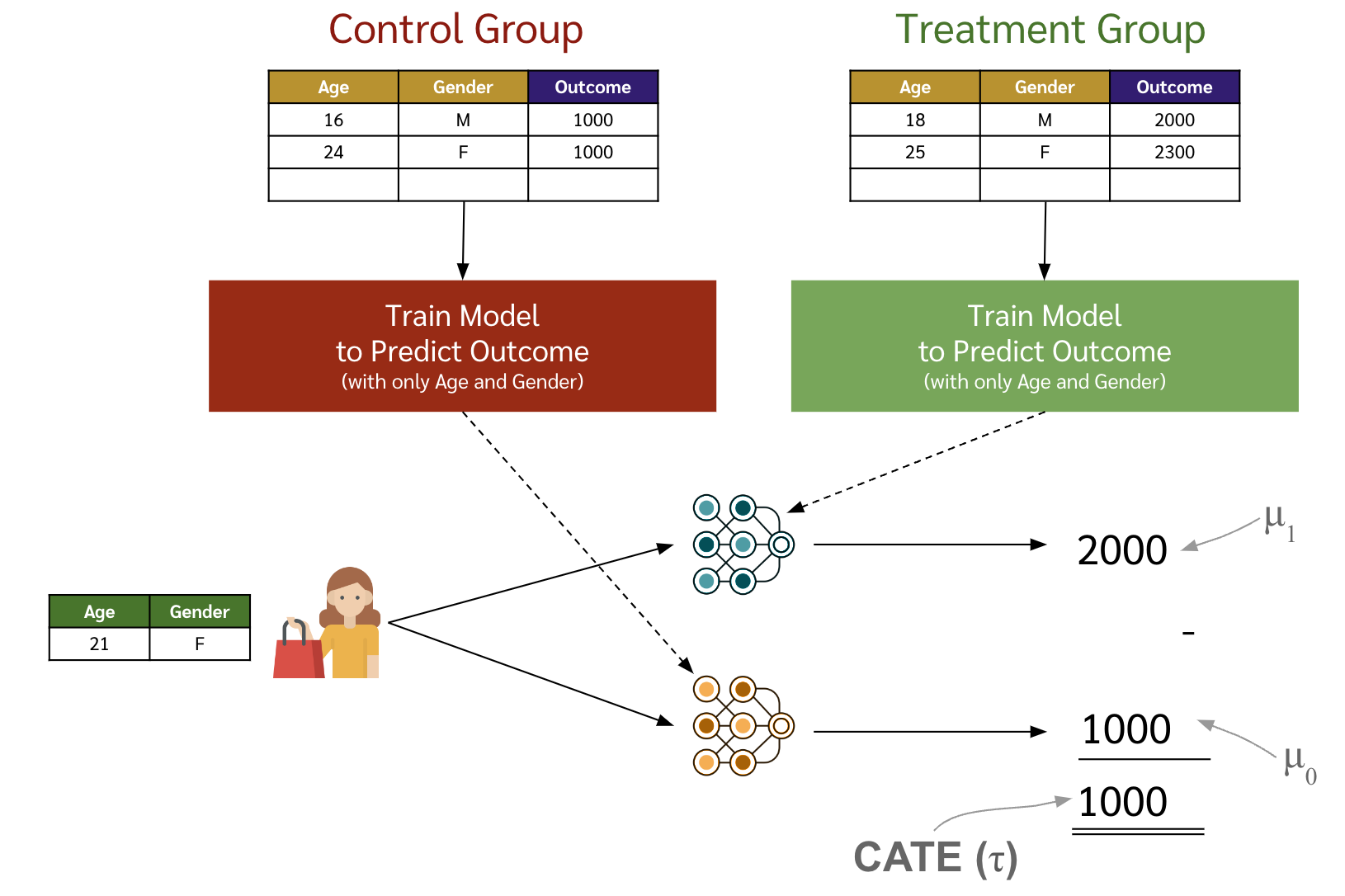
- ซึ่งการทำ T-Learner นี้ ทั้งโมเดลสองตัวไม่จำเป็นจะต้องเป็นโมเดลเดียวกัน เน้น ๆ เลือก ๆ ตามความเหมาะสมได้ เช่น เราอาจจะใช้โมเดลที่มีความ complex สูงหน่อย เช่น xgboost กับกลุ่มที่ไม่ได้รับ treatment ซึ่งมีจำนวนประชากรเยอะกว่า แล้วก็อาจจะใช้ model ที่มีความ complex ต่ำหน่อยกับประชากรที่ได้รับ treatment ซึ่งมีจำนวนประชากรต่ำกว่าเนื่องจากต้องป้องกันการเกิด overfitting
- ทีนี้ปัญหามันจะเกิด ถ้าฝั่งที่มีจำนวนประชากรน้อยกว่ามันน้อยมากกกกกกกกแล้วเราเลยต้องทำ regularization เพื่อป้องกัน overfitting ไปเยอะ มันอาจจะทำให้วัดผลตัว effect เพี้ยนได้
-
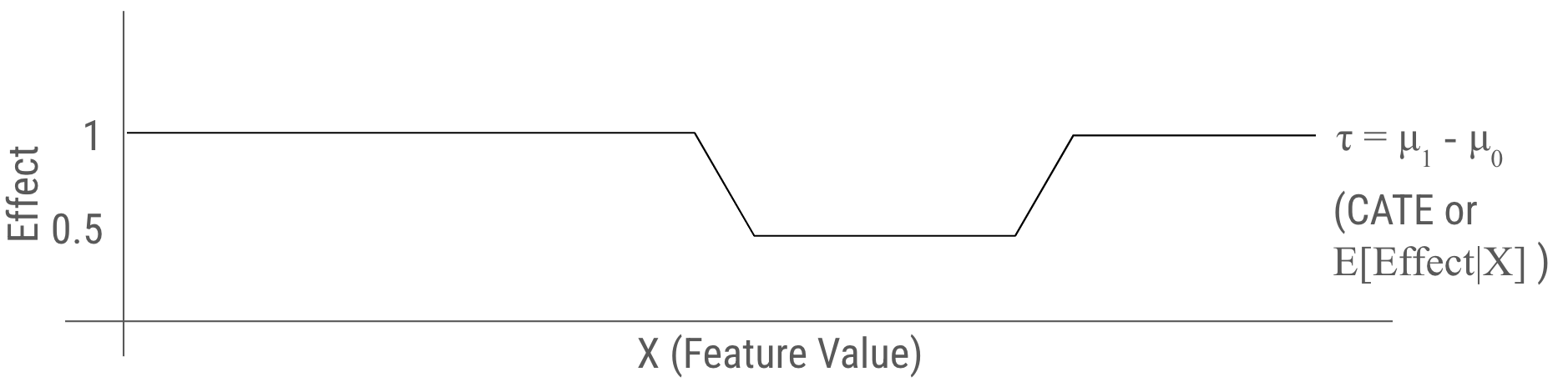
ตัวอย่างด้านล่างจากเปเปอร์ link
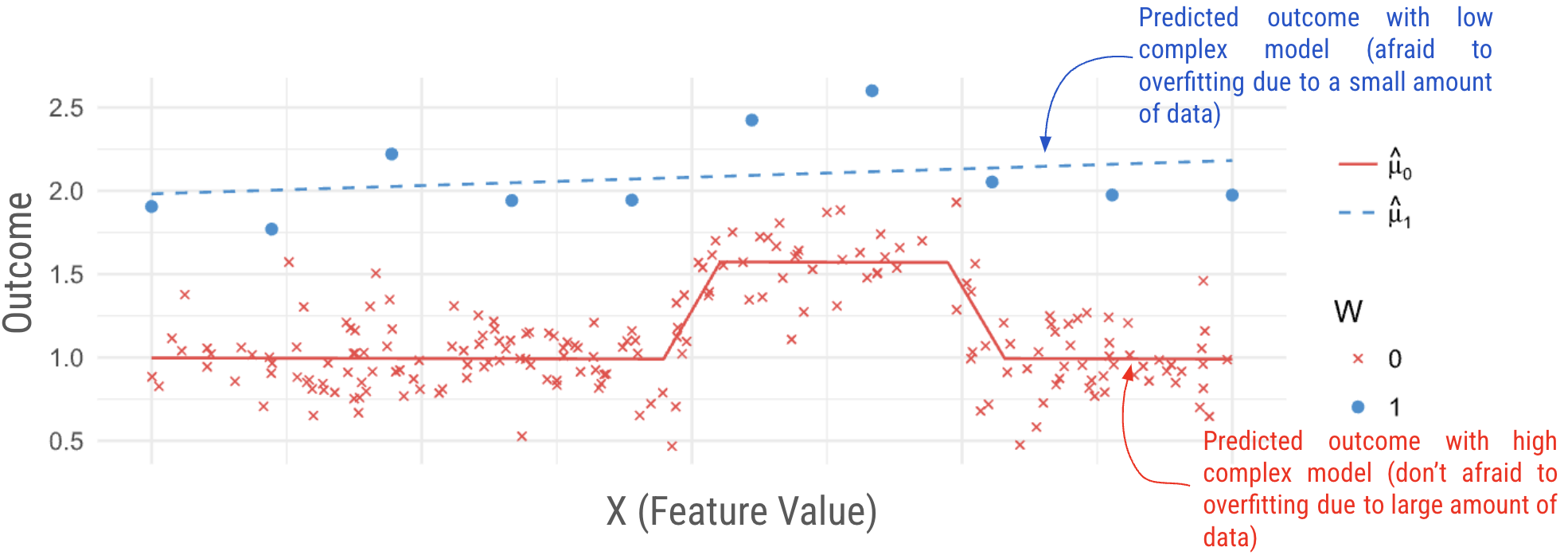
- แกน x ให้มองเป็นฟีเจอร์อะไรซักอย่าง ส่วนแกน y คือค่า outcome โดยที่กลุ่มที่เป็น control group นั้นเป็นจุดสีฟ้า และกลุ่มที่เป็น treatment group เป็นจุดสีแดง
- ใช้ตัวอย่างข้อมูล syntethic มาโดยที่
- treatment group มีแค่ 10 จุดเท่านั้น ในขณะที่ control group มีจำนวนมากกกกกก
- โดยฟีเจอร์หรือค่าในแกน x ก็มีผลต่อ outcome เหมือนกันโดยที่จะมีช่วงของค่าช่วงนึงที่ outcome กระโดดขึ้นไป
- ด้วยความที่เป็นข้อมูลที่ gen มาเอง เราเลยรู้ว่าจริง ๆ แล้ว effect ของ treatment ของทุกคนเนี่ยคือ +1
-
จากคำอธิบายข้อมูลข้างบน แปลว่า effect หรือผลลัพธ์ที่โมเดลบอกมามันควรจะเป็นเส้นแนวนอนที่ความสูง 1

- แต่ว่าด้วยความที่กลุ่ม treatment group นั้นเรามีจำนวนน้อยยมาก แล้วเราก็กลัวจะ overfit model เราก็อาจจะใช้โมเดลที่มีความ complex น้อยลง เช่น linear regression หรืออาจจะเติม regularization ไปเยอะ ๆ ทำให้โมเดลที่ได้อาจจับ trend ส่วน
มีช่วงของค่าช่วงนึงที่ outcome กระโดดขึ้นไปไม่ได้ มันเลย predict เป็นเส้นตรง ๆ แทน (เส้นสีฟ้า) -
ทำให้ถ้าเราเอา $\mu_{\color{green}1}(x) - \mu_{\color{red}0}(x)$ เพื่อหา CATE ตามวิธีของ T-learner มันจะได้กราฟหน้าตาแบบด้านล่างแทน ซึ่งผิด
X-Learner
- ซึ่งในเปเปอร์นี้ เค้าเลยเสนอวิธีที่ชื่อว่า X learner ที่จะแก้ปัญหา T learner โดยการเอาความรู้ที่เรียนรู้หรือ insight ที่เรียนรู้จากแต่ละกลุ่มมาสลับให้กันและกัน
- โดยมีขั้นตอนดังนี้
-
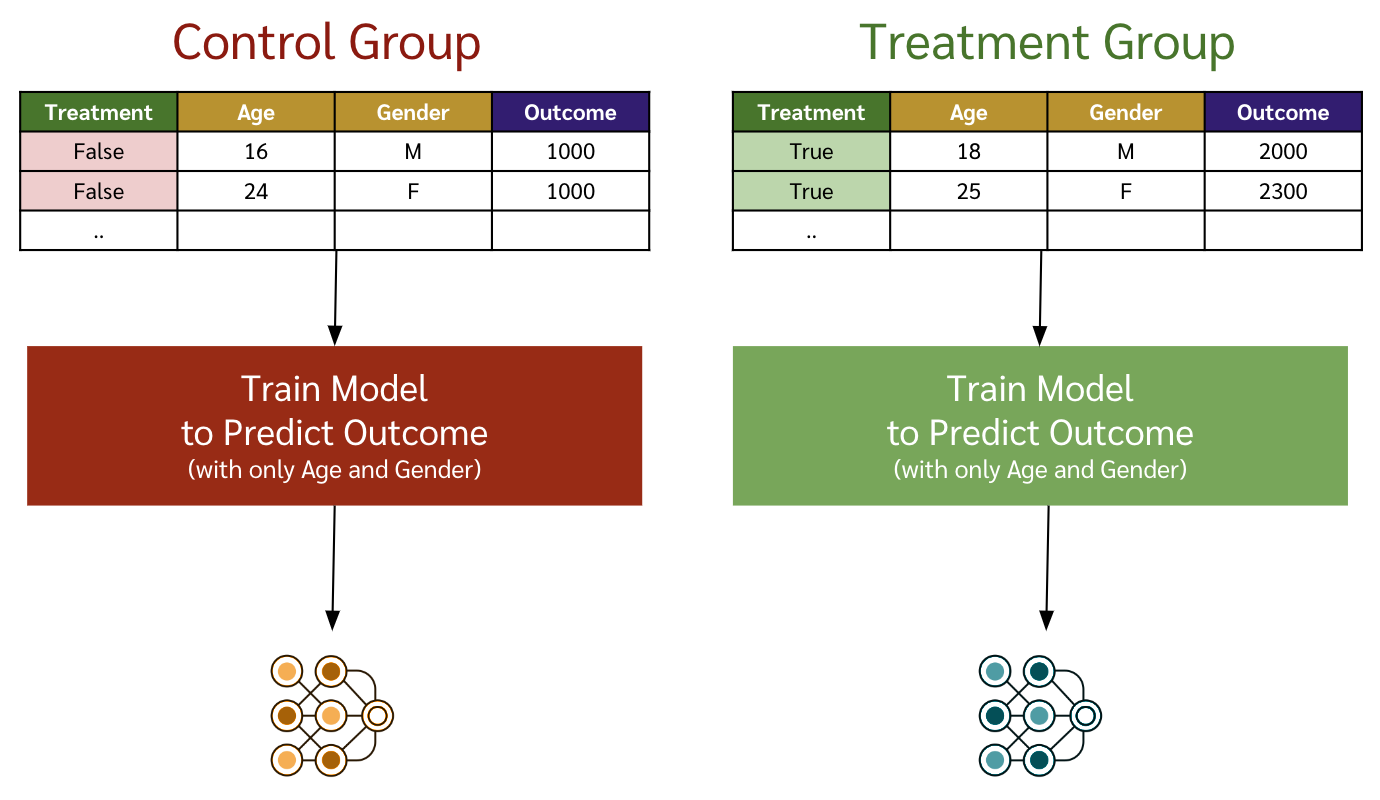
เหมือน T Learner เลย คือสร้าง model ที่ predict outcome แยกของกลุ่ม control และ treatment
\begin{equation} \label{eq:xlearner-1-1} \mu_{\color{green}1}(x) = \mathbb{E}[{\color{green}Y^1}|X=x] \end{equation}
\begin{equation} \label{eq:xlearner-1-0} \mu_{\color{red}0}(x) = \mathbb{E}[{\color{red}Y^0}|X=x] \end{equation}
-
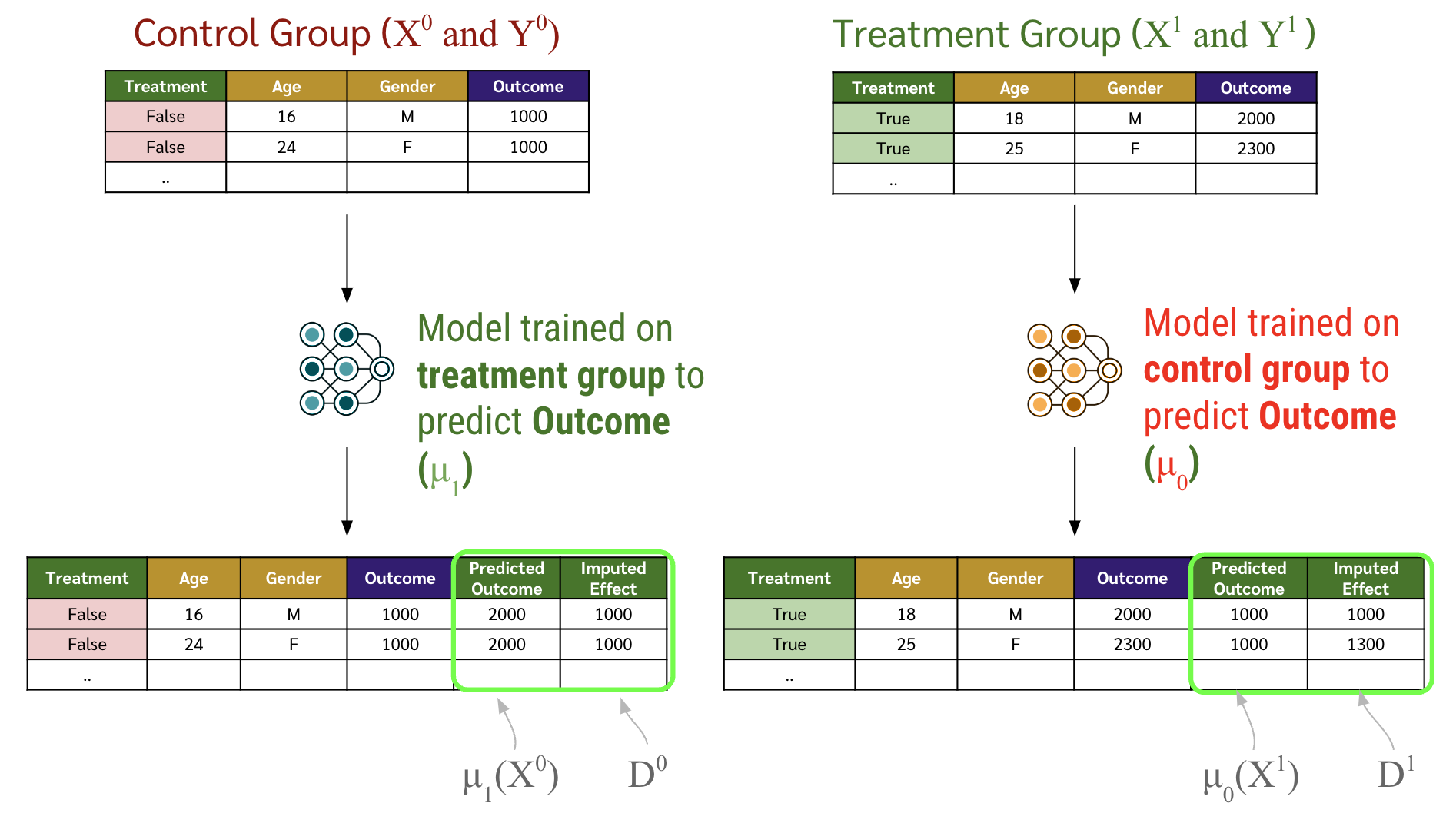
ใช้โมเดลของกลุ่ม control ไปทำนาย outcome ของแต่ละ row ใน treatment group และใช้โมเดลของกลุ่ม treatment ไปทำนาย outcome ของแต่ละ row ใน control group จากนั้นคำนวณ Imputed Effect ให้แต่ละกลุ่ม โดยการใช้สมการข้างล่าง
\begin{equation} \label{eq:xlearner-2-1} \tilde{D}_i^1 = Y_i^1 - \hat{\mu}_0(X_i^1) \end{equation}
\begin{equation} \label{eq:xlearner-2-0} \tilde{D}_i^0 = \hat{\mu}_1(X_i^0) - Y_i^0 \end{equation}
-
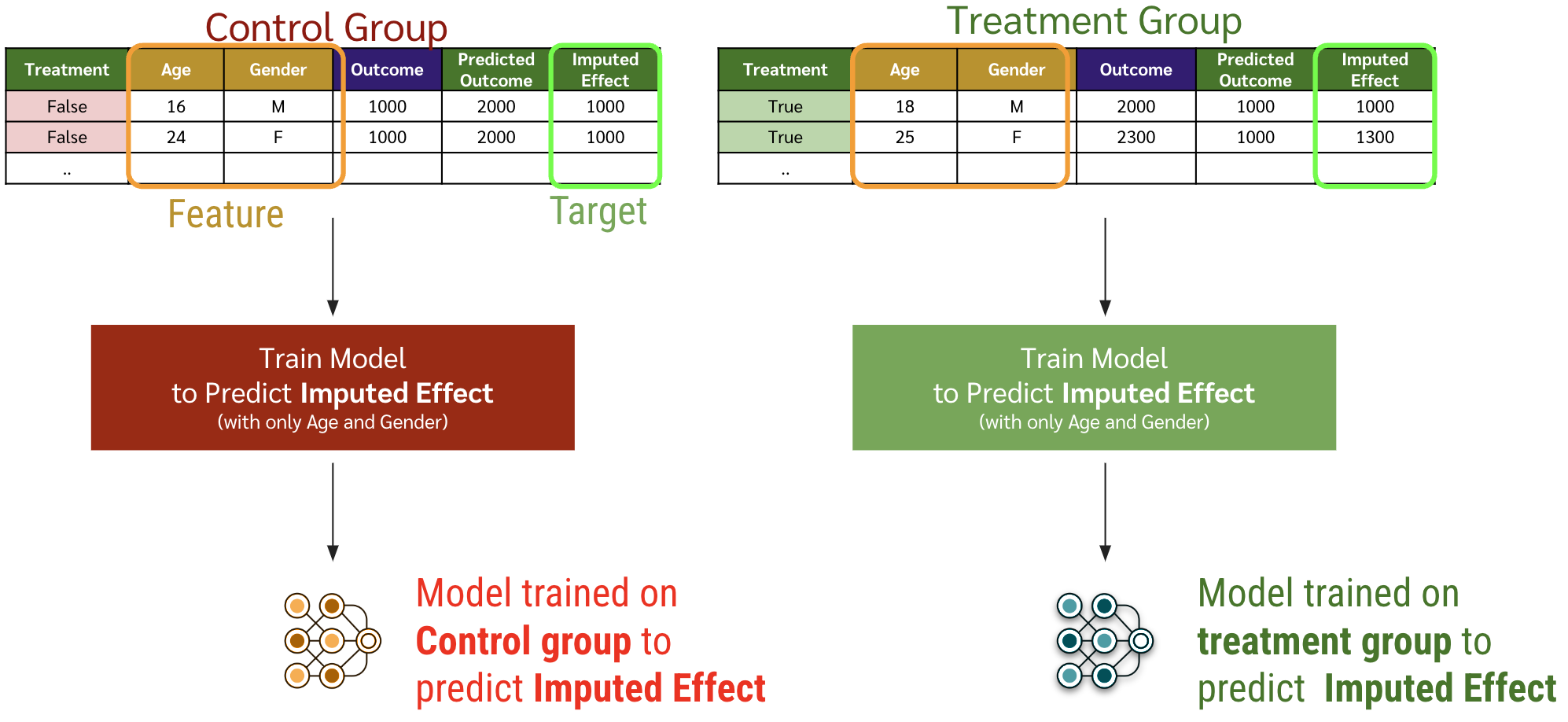
Train อีก 2 โมเดลสำหรับแต่ละกลุ่มให้ทำนายค่า imputed effect ที่หาไว้ในข้อก่อนหน้า
\begin{equation} \label{eq:xlearner-3-1} \tau_1(x) = \mathbb{E}\left[ \tilde{D}^1 \mid X^1 = x \right] \end{equation}
\begin{equation} \label{eq:xlearner-3-0} \tau_0(x) = \mathbb{E}\left[ \tilde{D}^0 \mid X^0 = x \right] \end{equation}
-
สร้างอีก 1 โมเดล สำหรับทำนายโอกาสที่ลูกค้าหรือแต่ละ row จะได้รับ treatment ด้วยการเอา control group และ treatment group มารวมเป็น dataset เดียวกัน แล้วทำ classification model ฝึกให้มันจำแนกลูกค้าไป control group และ treatment group ให้
\begin{equation} \label{eq:xlearner-4-0} g(x) = \mathbb{E}\left[ T \mid X = x \right] \end{equation}
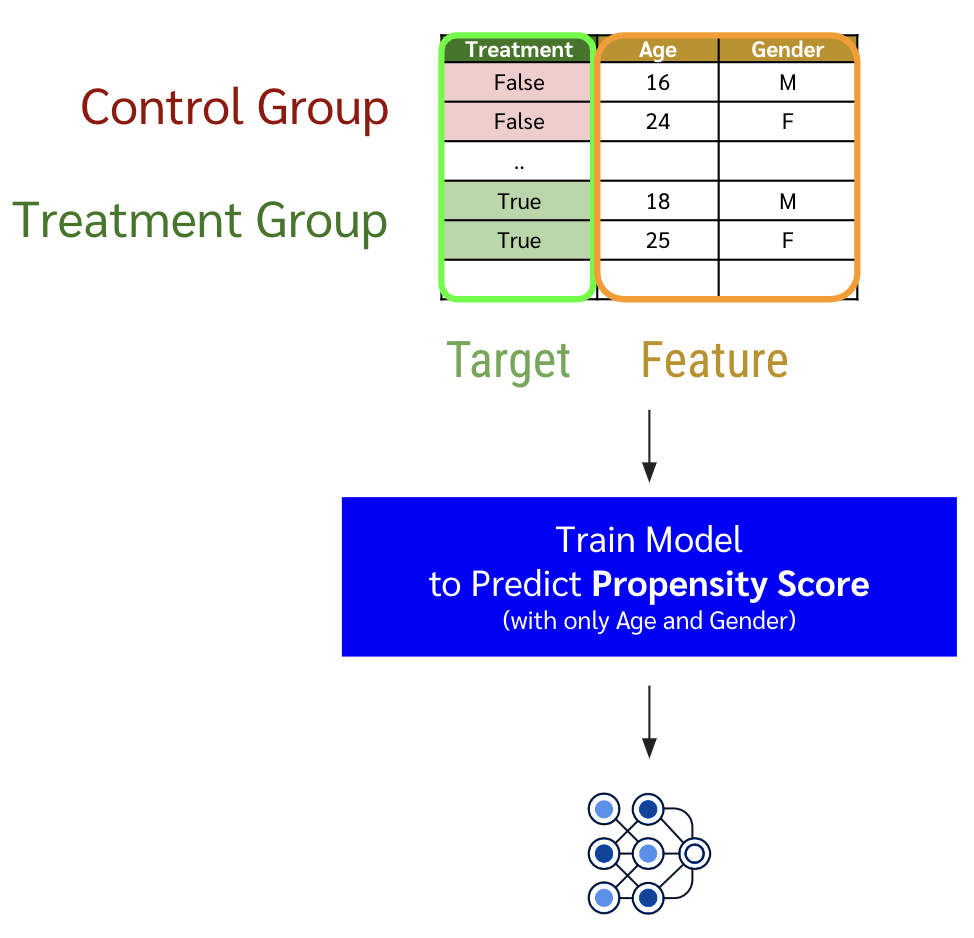
-
ตอนเราใช้โมเดลก็ เอาข้อมูลลูกค้ามาผ่านโมเดลที่สร้างในข้อที่ 3 เพื่อให้ได้ effect ออกมา จากนั้นเอาค่า effect นั้นไป weighted average ด้วยผลลัพธ์จากโมเดลในข้อ 4 ก็จะได้ CATE แล้วจ้า
\begin{equation} \label{eq:xlearner-5} \hat{\tau}(x) = g(x) \hat{\tau}_0(x) + (1 - g(x)) \hat{\tau}_1(x), \end{equation}
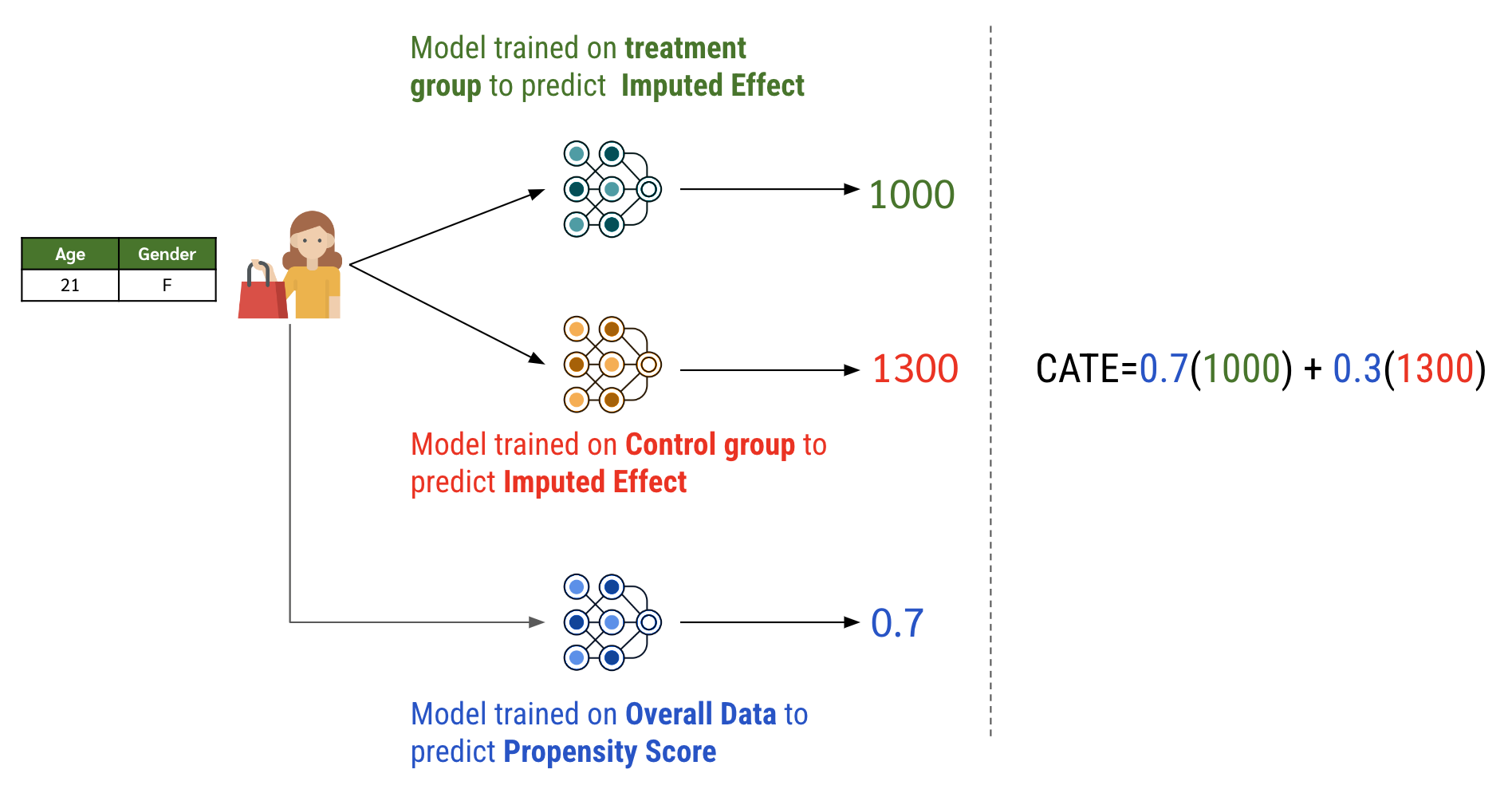
-