ในบทความนี้จะเล่าเปเปอร์ที่ชื่อว่า HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
โดยวิธีที่เปเปอร์นี้เสนอก็จะแบ่งเป็น 2 ขั้นตอนหลัก ๆ เหมือนการทำ RAG ทั่วไป คือการเอาข้อมูลในรูปแบบ raw text หรือพวกเอกสารต่าง ๆ มาจัดระเบียบหรือทำ indexing และการค้นหรือเรียกใช้งานข้อมูล
Offline Indexing
- ในเปเปอร์นี้เค้าจะโมเดลข้อมูล external knowledge ให้เป็น schemaless knowledge graph (KG)
เข้าใจ (ไม่รู้ถูกหรือผิด) ว่า schemaless knowledge graph คือ knowledge graph ที่ node เป็น noun หรือ noun phase ส่วน edge หรือ link ระหว่าง node เป็น verb อะไรก็ได้ เช่น ใน, ก่อตั้ง, อยู่ที่, เกิดที่, กิน etc นะ
- เริ่มจากเค้าจะดึง passage (หรือ chunk of text น่ะแหละ) ออกมาจาก document แล้วค่อย ๆ เอาไป extract เป็น node และ edge แล้วเติมใน knowledge graph
-
ตัวอย่าง passage
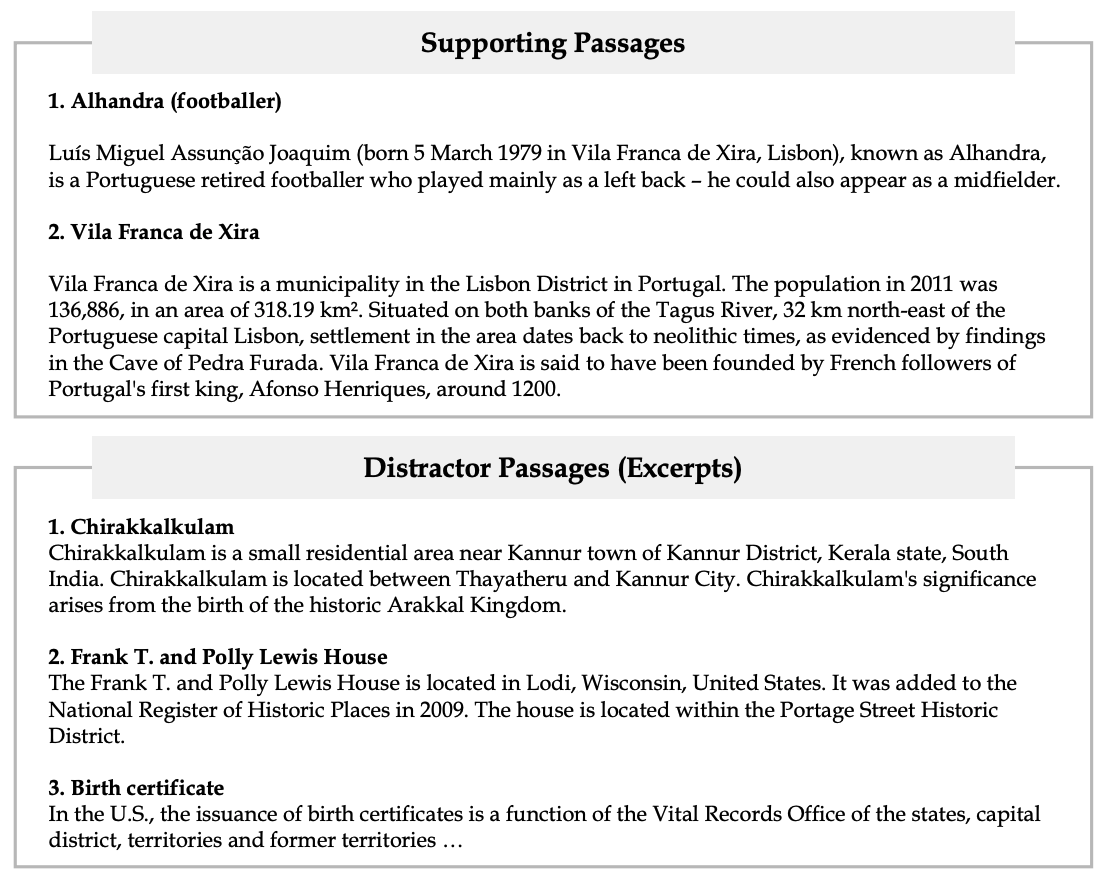
- โดยที่เค้าจะส่ง passage ไปให้ LLM (GPT 3.5) แล้วใช้ 1-shot prompt ให้มัน extract
-
name entity หรือคำถามต่าง ๆ ด้วย prompt ด้านล่าง

-
แล้วเอา name entity มาเป็น context ใน prompt ให้ LLM extract สิ่งที่เรียกว่า triple หรือ (node, link, node)

-
- จากนั้นเค้า augment graph ด้วยการสร้าง node ที่เป็น synonym ขึ้นมาไว้เพิ่มเติม โดยการใช้ retrieval model (ในเปเปอร์ใช้ ColBERTv2)
-
ตัวผลลัพธ์ของขั้นตอนข้างบนก็จะได้กราฟหน้าตาคล้าย ๆ ข้างล่าง
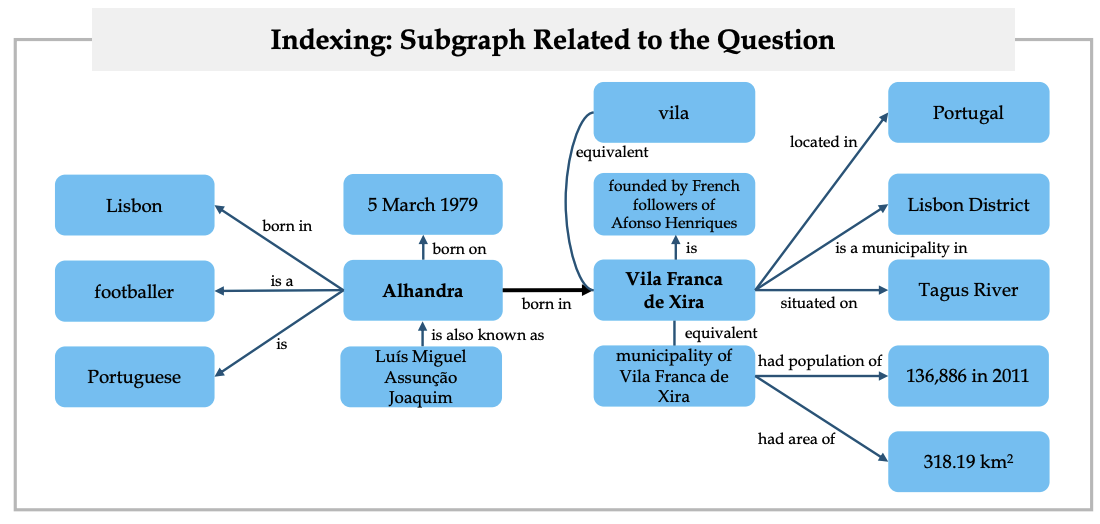
- นอกจากนี้ก็สร้าง matrix (เรียกว่า matrix $P$) ที่มี
- จำนวน row = จำนวน noun phase ทั้งหมด
- จำนวน column = จำนวน passage
ซึ่งใช้เก็บข้อมูลว่าแต่ละ noun phase ปรากฏ passage ไหนบ้าง จำนวนกี่ครั้ง
Online Retrieval
- เอาคำถามมา extract noun phase ออกมา ด้วย 1-shot prompt เช่นเดียวกัน
-
รูปแบบ prompt ที่ใช้

-
- แต่ละ noun phase
- เอาไป encode ด้วย retrieval model
- หา node ที่คล้ายกับ noun phase ที่ปรากฏในคำถามที่สุดออกมา (มี cosine similarity เยอะสุด)
- เราจะเรียก node พวกนี้ว่า query node แล้วกันนะ
- ตัวอย่างคำถามและผลลัพธ์จากสองขั้นตอนข้างบน

- จากนั้นใช้ Personal Pagerank Algorithm (PPR) ซึ่งคงไม่ได้อธิบายแบบละเอียดใน blog นี้
- แต่ถ้าถ้ามองภาพง่าย ๆ ไว้ก่อนก็ให้คิดว่า
- เราทำ random walk บนกราฟน่ะแหละ (หรือก็คือเดินสุ่มหลาย ๆ ครั้ง)
- โดยที่การ random walk แต่ละครั้ง ก็จะเริ่มต้นใน random node จาก query node ที่หาในข้อก่อนหน้า
ซึ่งเค้าเสนอวิธีที่ชื่อว่า node specificity โดยการปรับ probability ที่จะเริ่มจากแต่ละ node ตามจำนวน passage ที่เราเอามาสร้างกราฟที่ node นั้นปรากฏอยู่ โดยที่ถ้า node นั้นโผล่มาในหลายเอกสารมาก ๆ เราจะปรับให้ prob ที่จะเริ่มที่ node นั้นมันน้อยลง เพราะว่าแปลว่าคำนั้นอาจจะเป็นคำทั่ว ๆ ไป ถ้าไปเริ่มหาจากจุดนั้นอาจจะเจอ context ที่เราสนใจจริง ๆ ยาก หรือกลับกันถ้า node นั้นปรากฏอยู่ในเอกสารจำนวนน้อยมาก ๆ เราก็ควรจะให้ความสนใจ node นั้นเยอะ ๆ เนื่องจากอาจจะเป็นคำเฉพาะที่ไม่ค่อยโผล่ที่ไหน ถ้าเรารู้ว่ามันอยู่ตรงไหนก็ควรหาแถว ๆ นั้นมากกว่า
- จากนั้นก็เดินสุ่ม ๆ ไปตาม edge ไป node นู่นนี่ไปเรื่อย ๆ
- โดยก่อนที่จะก้าวออกไปแต่ละครั้ง มันจะมี probability ว่าให้หยุดตรงนี้กันเถอะ แล้วกลับไปเริ่มใหม่
- เค้าตั้งไว้ที่ 0.5 ซึ่งจริง ๆ คิดว่าอันนี้เราสามารถปรับไปตามโจทย์ของเราได้ เช่น ถ้า knowledge ที่เราให้ llm ตอบคำถามมันค่อนข้างกว้าง แล้วอาจจะมีหลาย passage ที่กระจัดกระจายค่านี้อาจจะต้องเยอะขึ้นเพื่ออนุญาตให้ random walk ไปได้ไกลกว่าเดิม
- จากนั้นก็นับจำนวนครั้งที่เหยียบบนแต่ละ node เลย แล้วก็ถ้าตรงไหนที่เราไปเหยียบบ่อยก็ให้คะแนนหรือ prob เยอะ ตรงไหนที่เหยียบไม่ค่อยบ่อยก็ให้คะแนนหรือ prob น้อย ๆ
- ซึ่งตัว PPR นี้มันจะกระจาย probability จากจุดเริ่มต้นแต่ละจุดออกไปยัง node อื่น ๆ ซึ่งถ้าเราคิดเร็ว ๆ ว่า node ไหนที่จะถูกเหยียบบ่อยรองจากพวก query node ที่เป็นจุดเริ่มต้นแล้ว ก็จะเป็น node ที่อยู่ตรงกลางระหว่าง query node ทั้งหลายนั่นเอง (เพราะมีโอกาสถูกเหยียบจากการเริ่มต้นหลายจุดเนอะ)
-
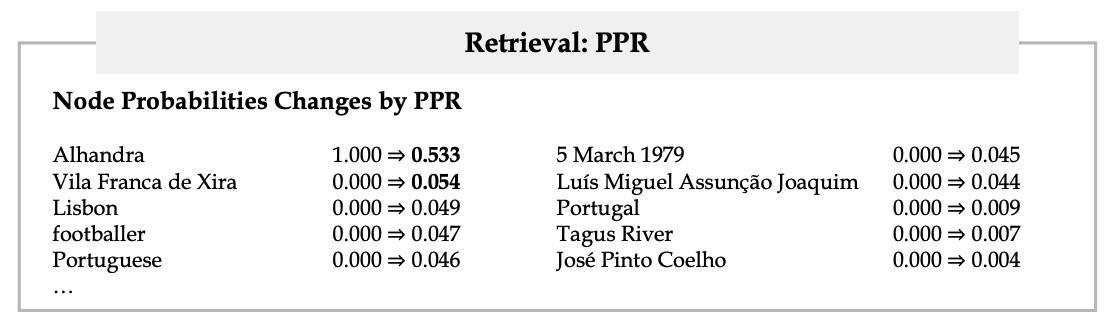
ตัวอย่าง probability ของแต่ละ node ที่เป็น result ของ PPR
- แต่ถ้าถ้ามองภาพง่าย ๆ ไว้ก่อนก็ให้คิดว่า
- เราจะได้ probability ของแต่ละ node ที่เป็นผลลัพธ์ของ PPR ซึ่งเราอาจจะเก็บไว้ในรูปแบบของ matrix ที่มีขนาด row เดียว และมีคอลัมน์เท่ากับจำนวน node หรือ nound phrase ทั้งหมด
- ให้เราเอา probability matrix มาคูณกับ matrix $P$ ที่เราสร้างไว้ตอนทำ offline indexing ก็จะได้ matrix ที่มีไซส์เป็น 1 row x <จำนวน passage> columns ซึ่งก็คือ score ของแต่ละ passage น่ะแหละ
- ที่จริงถ้าเราลองดูดี ๆ มันก็คือการทำ weighted average น่ะแหละว่า passage ไหนมี keyword ที่ต้องการโผล่มาเยอะที่สุด โดยการ weight จาก probability ของแต่ละ keyword ที่ได้จาก PPR น่ะแหละ (keyword ที่สำคัญก็ weight เยอะหน่อยอะไรงี้)
- หรือที่จริงเราสามารถเขียนเป็นสมการง่าย ๆ แบบข้างล่างได้
score ของ passage = (prob ของ Node_a x จำนวนครั้งที่ปรากฏใน passage นั้น ๆ) + (prob ของ Node_b x จำนวนครั้งที่ปรากฏใน passage นั้น ๆ) ...
- แล้วเราก็หยิบ passsage ที่มี score สูง ๆ ส่งไปเป็น context ให้ LLM ได้เลยจ้า