- วันนี้จะเขียนถึงบทความสั้น ๆ (เขียนคืนวันธรรมดาอ่ะนะ เขียนยาวไม่ได้) อธิบาย algorithm ที่ชื่อว่า isolation forest ซึ่งเป็น algorithm ประเภท one Class classification ที่ใช้ในการจับ outlier หรือ anomaly data (จุดที่ข้อมูลไม่ค่อยเหมือนชาวบ้าน)ใน dataset ของเราแบบไม่ต้องมี label มาก่อน
- ขั้นตอนการทำงานง่ายมาก
- random split data ตามจำนวน tree
- ในแต่ละ tree เราจะพยายามแบ่ง data ให้ละเอียดขึ้นเรื่อย ๆ จนสามารถแบ่ง data ให้เหลือจุดเดียวหรือ row เดียวน่ะแหละ
- ซึ่งการแบ่งของมันก็คือใช้วิธี random หยิบ feature และ random ค่าใน feature นั้นแล้วก็ตัดข้อมูลไปเรื่อย ๆ เลย
- ทีนี้ลองจินตนาการว่า
- ถ้าข้อมูลชิ้นนึงมันไม่เหมือนชาวบ้านเค้าแบบอยู่ห่าง ๆ เลย random feature กับ random ค่าไม่กี่ครั้งก็น่าจะหยิบข้อมูลชิ้นนั้นออกมาได้แล้ว
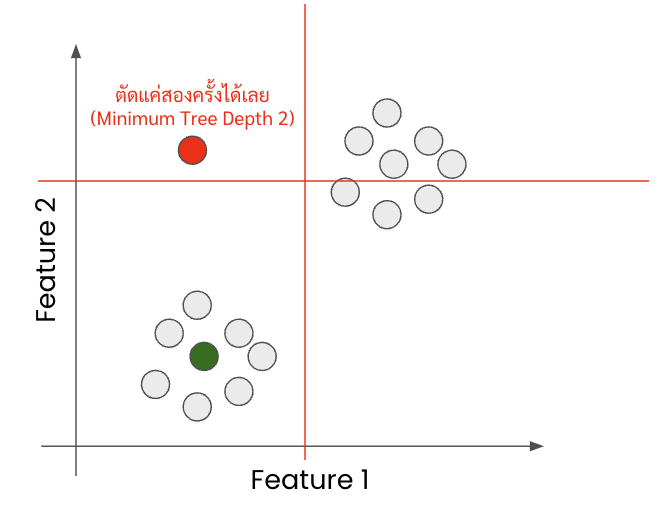
- แต่กลับกันถ้าข้อมูลกลุ่มนึงอยู่กระจุกกันเลย แบบถ้าเอา plot scatter นี่คือติด ๆ กันเลย กว่าจะ random feature กับ random ค่าที่จะตัดพวกมันออกมาเป็นกลุ่มเดี่ยว ๆ ให้หมดนี่จะยากมากหรือต้องใช้หลายรอบมาก ๆ
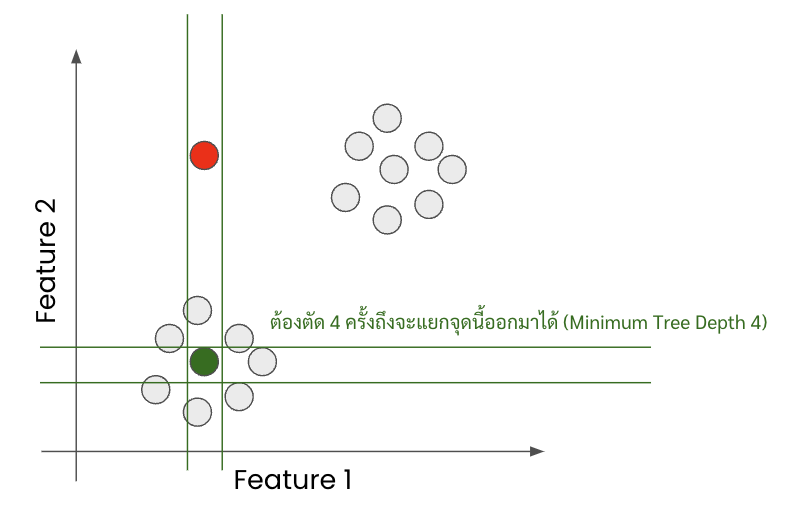
- นั่นแหละคือวิธีการจับ anomaly ของมัน ก็คือดูจากความลึกเฉลี่ยของ tree ทั้งหมดในการจับข้อมูลชุดนั้นแยกออกมา
- ถ้าความลึกมันน้อย (มันตื้นหรือใช้จำนวนครั้งในการตัดข้อมูลน้อย) ก็จะมีโอกาสเป็น anomaly สูง
- ถ้าความลึกมันเยอะ (ใช้จำนวนครั้งในการตัดข้อมูลมาก) ก็จะมีโอกาสเป็น anomaly ต่ำ
- ถ้าอยากลองใช้ทำงานก็ใช้ของ scikit-learn IsolationForest ได้เลย
- ง่าย ๆ แค่นี้เลยจ้า