ในบทความนี้จะเล่าเปเปอร์ที่ชื่อว่า RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL โดยจะเล่าเรียงเป็น Problem ว่าเปเปอร์นี้มองเห็นและต้องการแก้ปัญหาอะไร แล้วก็ Solution ว่าเค้าเสนอวิธีแก้ยังไง
TLDR;
- การทำ RAG โดยทั่วไปอาจจะทำให้ไม่ได้รับ context ที่เพียงพอสำหรับตอบคำถามที่ถามถึงภาพรวมของ knowledge
- เปเปอร์นี้เสนอว่า
- ให้ตัดเนื้อหาเป็นส่วน ๆ แล้วเอาเนื้อหาที่เกี่ยวข้องกันมาจัดกลุ่มด้วยกัน แล้วค่อย ๆ สรุปทีละ level ขึ้นมาเป็น tree เช่น node บนสุดอาจจะเป็นสรุปว่าข้อมูลทั้งหมดเกี่ยวกับอะไร แล้ว node ชั้นล่าง ๆ อาจจะเป็นเนื้อหาที่มีรายละเอียดมากขึ้น
- ตอนเอาไปใช้เค้าก็เสนอมาสองวิธี
- หา path ที่ไล่จาก root node ลงไป leaf node ที่เกี่ยวข้องกับคำถามมากที่สุด แล้วส่งเนื้อหาทั้ง path นั้นไปเป็น context
- flatten tree ออกมาเลย แล้วก็ทำ rag ธรรมดา คือหาว่า node ไหนบ้างที่เกี่ยวกับคำถามแล้วก็เลือก node พวกนั้นไปเป็น context
Problem
- การตัดเนื้อหาทั้งหมดเป็นส่วนสั้น ๆ แล้วส่งให้ LLM แบบที่ RAG พื้นฐานทำ อาจจะทำให้ LLM ไม่ได้รับ context ที่เพียงพอในการตอบคำถามบางคำถามโดยเฉพาะคำถามที่เกี่ยวข้องกับภาพรวมของเนื้อหาทั้งหมด เช่น
- สมมติเนื้อหาที่เราต้องการให้ LLM ตอบคำถามคือเรื่องซินเดอเรล่า แล้วเราตัดเรื่องเล่าซินเดอเรล่าออกเป็นต่อน ๆ เช่น มีแม่เลี้ยงใจร้าย, มีนางฟ้ามาเสกรถม้าให้, ทำรองเท้าแก้วตกไว้ที่วัง , ฯลฯ
- แล้วเราถาม LLM ว่า “ซินเดอเรล่า happy ending ได้ยังไง ?”
- คำตอบที่เราคาดหวังก็อาจจะเป็นในภาพรวม เช่น ชินเดอะเรล่ามีจิตงดงาม, หรืออาจจะเป็นการเล่าเรื่องย่อ บลาๆ
- แต่ว่าถ้าเราใช้ RAG แบบธรรมดาแล้วส่ง context ไปโดด ๆ แบบ เพราะมีนางฟ้า หรืออะไรงี้ คำตอบจาก LLM มันก็อาจจะมึน ๆ หน่อย
-
ซึ่งเปเปอร์นี้เลยเสนอวิธีการแก้ปัญหาที่ว่ามา หรือก็คืออยากทำให้ LLM ตอบคำถามประเภทองค์รวมได้ดีขึ้น โดยตัวอย่างด้านล่างจะเป็นการเปรียบเทียบระหว่างวิธี Raptor กับ DPR ในคำถามว่า “ซินเดอเรล่า happy ending ได้ยังไง ?” ที่เค้าทดสอบและโชว์ไว้ในเปเปอร์
- Context ที่ได้จาก Raptor (วิธีในเปเปอร์นี้) และ DPR

- คำตอบที่ได้จาก GPT-4
- เมื่อได้รับ context ที่ได้จาก Raptor
Cinderella finds a happy ending when the Prince searches for the owner of the lost glass slipper and discovers it belongs to Cinderella. They eventually marry, transforming Cinderella’s life for the better
- เมื่อได้รับ context ที่ได้จาก DPR
Based on the given context, it is not possible to determine how Cinderella finds a happy ending, as the text lacks information about the story’s conclusion.
Proposed Solution
ในส่วนของ method ที่เค้าเสนอมา เดี๋ยวจะแบ่งเป็นสองส่วนก็คือ
- Tree Construction → จัดระเบียบเนื้อหาทั้งหมดสร้างเป็น tree (มองว่าคือการทำ indexing ก็น่าจะได้)
- Retrieval → จาก tree จะดึง context ต่าง ๆ ออกมายังไงดี
Tree Construction
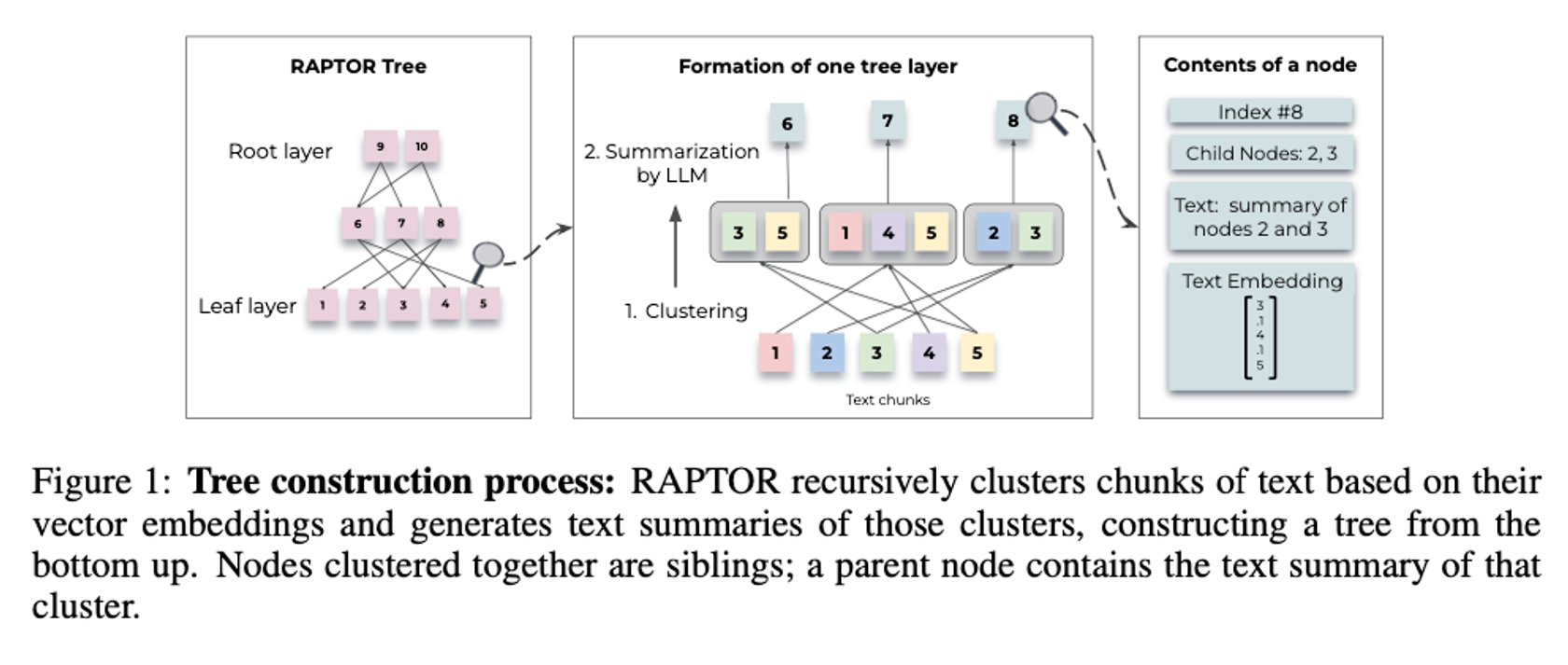
- ในขั้นตอนนี้จะเป็นการนำเอกสารหรือพวก external knowledge มาสร้างเป็น tree
- โดยที่ tree ชั้นบนสุดก็จะเป็นการสรุปทั้งบทความ และชั้นล่างๆลงมาก็จะเป็นการสรุปที่มีรายละเอียดเพิ่มขึ้นเรื่อย ๆ
- โดยที่ขั้นตอนการสร้าง tree เราจะเริ่มจากชั้นล่างสุดก่อนซึ่งก็คือ raw data โดยมีขั้นตอนมีดังนี้
- แบ่ง text ทั้งหมดเป็นชิ้นเล็ก ๆ โดยแต่ละชิ้นอาจจะมีความยาวซัก 100 tokens โดยที่ถ้าหากตัดที่ 100 tokens แล้วมันไปตัดกลางประโยคพอดี ก็ขยับบวกลบได้นิดหน่อย
- ทำ embedding กับ text แต่ละอัน
- ทำ clustering กับ embedding vector ของพวก text ที่ตัดมา จัดให้เป็นกลุ่ม ๆ โดยเค้าเลือกใช้ soft-clustering (GMM clustering) ซึ่งอนุญาตให้ text 1 อันอยุ่ในหลายกลุ่่มได้ เพราะบางทีเนื้อหาบางส่วนอาจจะเกี่ยวข้องในหลาย topic อะไรแบบนี้
-
ส่ง text ทั้งหมด ของแต่ละกลุ่มไปให้ llm สรุปให้ ด้านล่างคือ prompt ที่เค้าใช้ในการบอกให้ GPT-4 สรุปให้
Write a summary of the following, including as many key details as possible: {context} - เราก็จะสร้าง tree ขึ้นมา 2 levels โดยที่มี parent node เป็นข้อความที่สรุปมาจาก text แต่ละกลุ่ม และ child node คือสมาชิกหรือ text ที่ถูกจัดอยู่ในแต่ละกลุ่ม
- แล้วเราก็ทำ clustering ที่ parent node ต่อ แล้วเอาไปให้ llm สรุปต่อแล้วก็สร้าง layer ข้างบนต่อไปเรื่อยๆ (วนทำข้อ 1-5 ไปเรื่อย ๆ ) จนไม่สามารถแบ่งได้อีกแล้ว
Retrieval
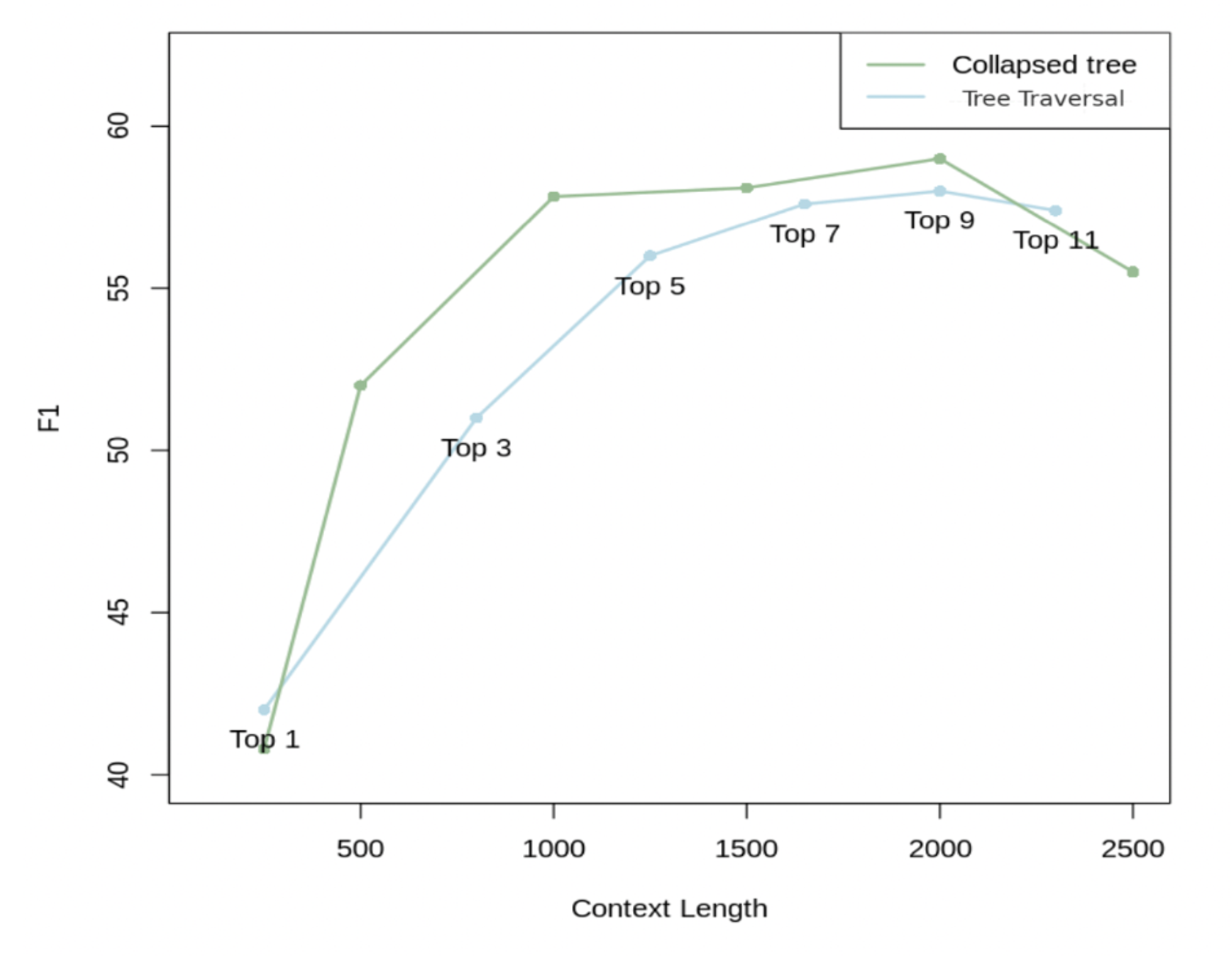
ในเปเปอร์นี้เค้าเสนอวิธีการดึง context ออกมาจาก tree สองวิธีด้วยกัน ได้แก่ Tree Traversal และ Collapsed Tree
Tree Traversal
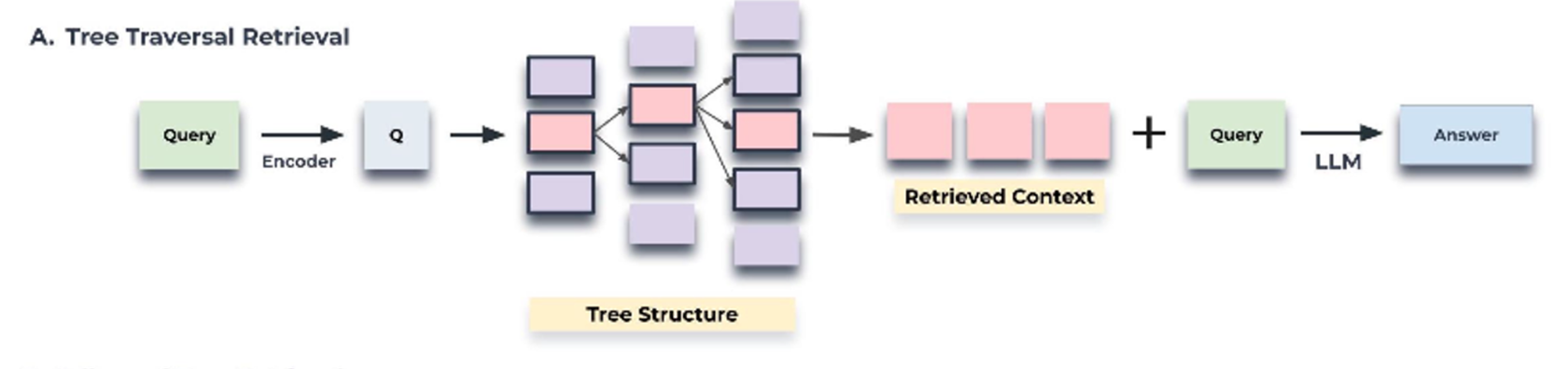
- เริ่มจากเอาคำถามมาทำ embed แล้วก็หาว่าในแต่ละ layer คำถามนั้นใกล้เคียงกับ node ไหนที่สุด ก็จะเลือก node นั้นและเอาคำถามไปเทียบกับลูก ๆ ของ node นั้นต่อไปเรื่อย ๆ จนไปถึง leaf node
- สุดท้ายเราจะได้ path จาก root node ถึง leaf node ที่เกี่ยวข้องกับคำถามที่สุด แล้วก็ส่ง context ใน path นั้นทั้งหมดไปให้ LLM เพื่อใช้ในการตอบคำถาม
Collapsed Tree

- Flatten tree ออกมาเลย ไม่สนว่าเป็น layer ไหนบ้าง เอามาวางเรียงกัน แล้วเทียบความเกี่ยวข้องกับคำถามรายตัว (cosine similiarity) แล้วก็เลือก top-K nodes ไปส่งให้ LLM เป็น context ในการตอบคำถาม
-
ซึ่งเค้าบอกว่าจริง ๆ แล้ววิธี collapsed tree ดีกว่า tree traversal ด้วยซ้ำ ดังแสดงดังรูปด้านล่าง เพราะว่าเค้าบอกว่ามัน flexible กว่า แล้วก็อนุญาตให้มันเลือก context ที่ละเอียดในระดับที่เหมาะสมกับการตอบคำถามได้ดีกว่า