ในบทความนี้จะมาเล่า paper ที่ชื่อว่า “TRAQ: Trustworthy Retrieval Augmented Question Answering via Conformal Prediction” ตามที่เข้าใจ ซึ่งอาจจะขาดบ้าง ถูกบ้าง ผิดบ้าง ต้องกราบขออภัย
TLDR;
- conformal prediction คือกระบวนการในการ inference หรือทำนายออกมาเป็น set โดยที่เราสามารถกำหนดค่า error ได้ ว่าโอกาสทีจะไม่มีค่าจริงใน set นั้นเป็นกี่ %
- ใน paper นี้เลยเสนอวิธีใช้ conformal prediction ทั้งตอนทำ RAG และตอน gen คำตอบจาก LLM เพื่อให้เราสามารถสร้าง chatbot ที่มั่นใจได้ว่าคำตอบมันจะถูกต้อง > xx% (ซึ่ง xx% นี้เรากำหนดเองได้ด้วยแหละ)
- อย่างไรก็ตามการใช้ conformal prediction นั้นจำเป็นจะต้องมี calibration set เช่น ชุดของคำถาม และตัวอย่าง passage ที่เกี่ยวข้องที่สุดของแต่ละคำถาม ซึ่งแน่นอนว่าต้องมาจากการ label โดยคนหรืออาจจะไปใช้ llm gen มา ซึ่งก็อาจจะต้องเตรียมไว้ซัก 1,000 คำถามคำตอบ อะไรแบบนี้
- ความเห็นผมเอง
- ที่จริงตัวผมเองคิดว่าไอเดียกับการใช้ conformal prediction ทำ RAG ก็น่าสนใจอยู่
- แต่การใช้กับตอน gen คำตอบจาก LLM คิดว่ามันอาจจะจะเปลืองไปหน่อย
- รวมถึงการทำวิธีต่าง ๆ ในเปเปอร์นี้อาจจะต้องพึ่งการ label ประมาณ 1000 คำถาม/คำตอบ ซึ่งอาจจะเหนื่อยไปรึเปล่านะ
The TRAQ Framework
ควรอ่าน conformal prediction ก่อนว่าคืออะไรใน link นี้ หรือจะไปค้น google อ่านที่อื่นก็ได้จ้า
Overview ของวิธีใน paper นี้แสดงในรูปด้านล่าง
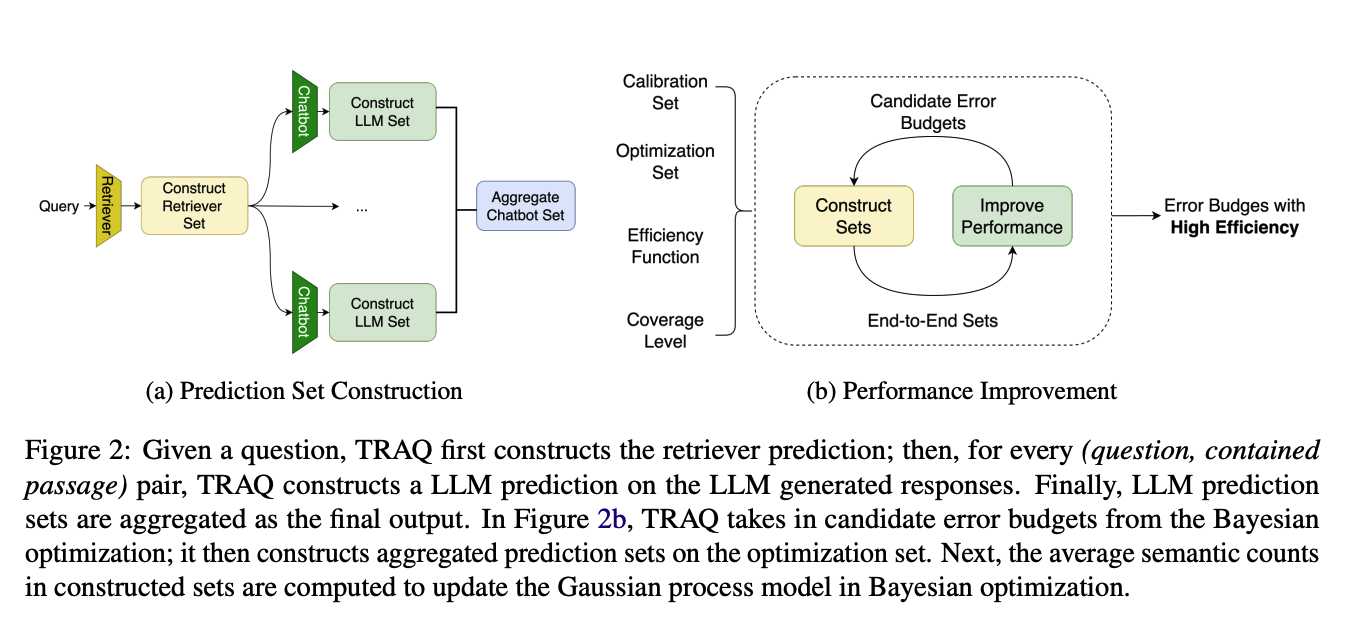
- Prediction Set Construction: รูปด้านซ้ายเป็นขั้นตอนแรกเค้าเสนอการทำ conformal prediction สองส่วนด้วยกัน ได้แก่ ตอนทำ RAG และตอน gen คำตอบจาก LLM ซึ่งทั้งสองส่วนนี้จะทำ conformal prediction แยกกัน
- Performance Improvement: รูปด้านขวาคือเราจะ set error ของ conformal prediction ทั้งสองฝั่งยังไงให้ได้ error ของคำตอบ LLM โดยรวมใกล้เคียงกับ error ที่ user ตั้งไว้มากที่สุด และมีจำนวน prediction หรือขนาดของ set ที่ต่ำที่สุด
Prediction Set Construction
RAG
Calibration Process
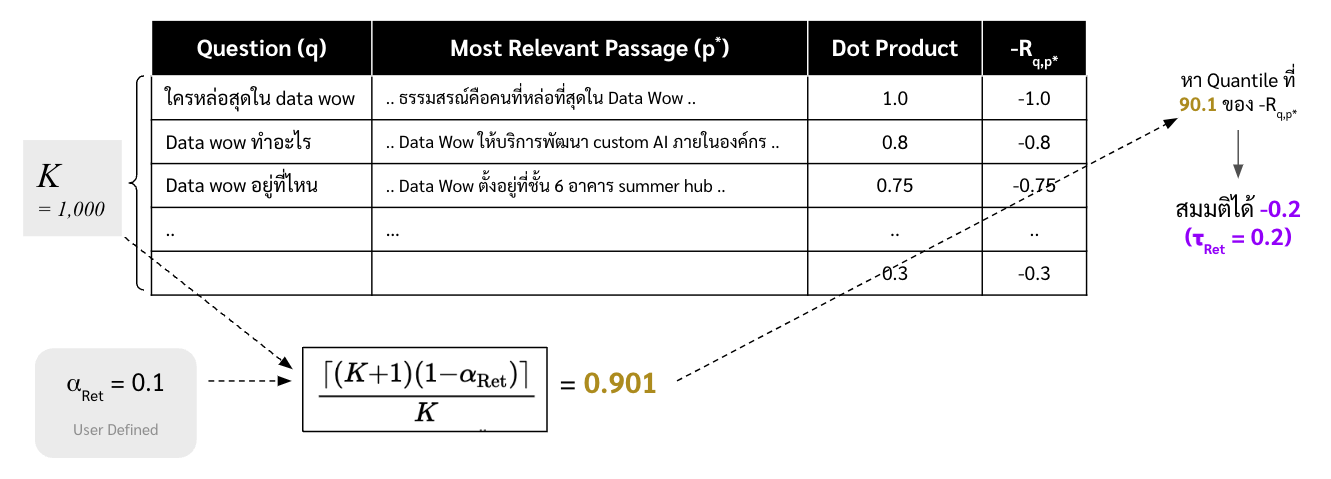
- ต้องมี dataset ก่อน ซึ่งเป็นคู่ระหว่างคำถาม ($q$) และ passage หรือส่วนของข้อมูลที่เกี่ยวข้องกับคำถามนั้นที่สุด ($p^*$) ซักประมาณ 500-1000 คู่ แล้วเอาไปทำ embed ไว้ซะให้เรียบร้อย
-
คำนวณ Nonconformality Measures ด้วยการใช้ negative inner product ระหว่าง embedding ของคำถามและ embedding ของข้อมูลที่เตรียมไว้ในข้อที่ 1 ซึ่งจะแทนด้วยตัวแปร $-R_{q,p^*}$
inner product โดยปกติจะบอกความเหมือนกัน ยิ่งผลลัพธ์มีค่าเยอะแปลว่ายิ่งเหมือนกัน ซึ่งในเปเปอร์นี้เค้าเลยเติมลบไปข้างหน้าเพื่อให้เป็นค่า nonconformity measure ซึ่งเป็นค่าที่บ่งบอกความไม่เหมือนกันแทน
-
หาค่า $\tau_{\text{Ret}}$ ซึ่งเป็น quantile ที่ $\frac{\left\lceil (K+1)(1-\alpha_{\text{Ret}}) \right\rceil}{K}$ ของ Nonconformality Measures โดยที่ $K$ คือจำนวนข้อมูลในชุดข้อมูลในข้อที่ 1 และ $\alpha_{\text{Ret}}$ คือ error ที่เราต้องการหรือความน่าจะเป็นที่ใน set ที่เป็นผลลัพธ์ของ conformal prediction จะไม่มีส่วนของข้อมูลที่เกี่ยวข้องกับคำถามที่สุดอยู่
เช่น ถ้าเราตั้ง $\alpha_{\text{Ret}}$ ไว้ซัก 0.1 หรือ 10% ก็แปลว่าถ้าหากเราใช้ค่า $\tau_{\text{Ret}}$ ในการทำ conformal prediction ในขั้นตอนต่อไป 100 ครั้ง จะมีประมาณ 10 ครั้งที่ผลลัพธ์ของ conformal prediction ไม่มีข้อมูลที่เกี่ยวข้องกับคำถามที่สุดอยู่
Prediction Process
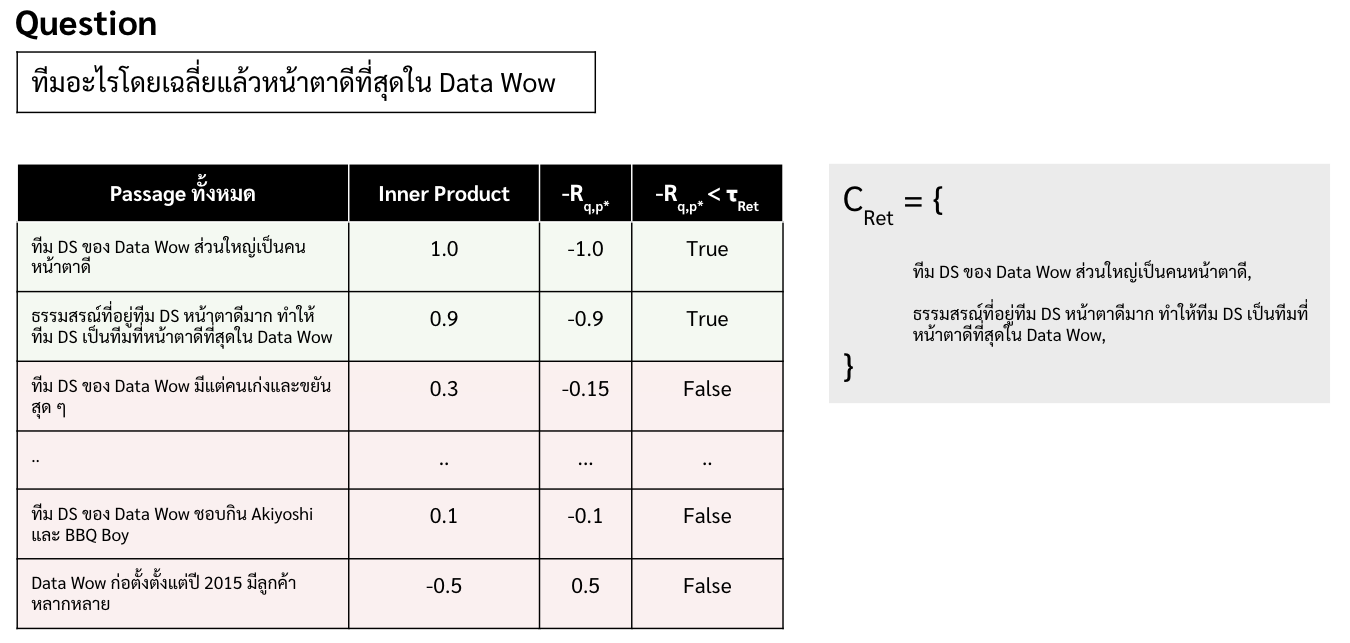
สร้าง conformal set หรือว่า set ของ passage ของแต่ละคำถาม ($C_{\text{Ret}}$) โดยการคำนวณค่า $-R(p,q)$ ระหว่างคำถาม ($p$) และ passage หรือชุดข้อมูลต่าง ๆ ($p$) และเลือกเฉพาะชุดข้อมูลหรือ passage ที่มีค่า $-R(p,q)$ น้อยกว่า $\tau_{\text{Ret}}$ เท่านั้น หรือสามารถเขียนขั้นตอนนี้ในรูปแบบสมการด้านล่าง
\begin{equation} \label{overview} C_{\text{Ret}}(q) = \{ p | -R_{q,p} \leq \tau_{\text{Ret}} \} \end{equation}
LLM
Calibration Process
-
เหมือนเดิมเลยก็คือ เราต้องเตรียมชุดของคำถามและคำตอบที่ต้องการเอาไว้ซัก 500 - 1000 คู่
- คำนวณค่า nonconformality measure ของคำตอบจาก LLM จากคำถามเทียบกับผลเฉลยหรือคำตอบที่ดีที่สุดที่เตรียมไว้ในข้อ 1.
- ซึ่งเปเปอร์นี้มองการ inference LLM เป็นเหมือนปัญหา classification ซึ่งในการทำ conformal prediction กับ classification นั้น เราจะคำนวณค่า Nonconformality Measures ด้วยการนำ 1 - probability ของคำตอบที่ถูกต้องจากโมเดล แต่ปัญหาคือทำยังไงถึงจะรู้ probability หรือค่า confidence ของแต่ละคำตอบจาก LLM
- ในเปเปอร์นี้เสนอว่าให้
- จากแต่ละคู่ของ (คำถาม, ข้อมูลที่เกี่ยวข้องที่ได้จากการทำ conformal ตอน RAG ) -> ให้ใช้ LLM gen คำตอบ ซัก 30 ครั้ง
- เอาคำตอบทั้งหมดมา cluster ด้วย Rouge-score (หรือจะไปใช้ embedding แล้วทำ clustering ก็ได้)
- ดูว่า cluster ไหนคือคำตอบที่ถูกที่สุด (ซึ่งอาจจะเอามาจากผลเฉลย ว่าคำตอบที่แท้จริงนั้นใกล้กับ cluster ไหนที่สุดหรือมี Rouge score > 0.7 อะไรแบบนี้)
- คำนวณค่า confidence ของคำตอบที่ถูกต้องจากอัตราส่วนของสมาชิกใน cluster นั้นต่อจำนวนคำตอบทั้งหมด
- เราก็จะสามารถคำนวณค่า nonconformality measure ได้ด้วยการนำ 1 - confidence
- จากนั้นก็หา quantile ที่ $\frac{\left\lceil (K+1)(1-\alpha_{\text{LLM}}) \right\rceil}{K}$ ของค่า nonconformality measure ที่หาไว้ในข้อ 2. โดย $K$ คือขนาดของชุดข้อมูลที่เตรียมไว้ในข้อที่ 1 และ $\alpha_{\text{LLM}}$
Prediction Process
ที่จริงเหมือนเค้าเขียนไว้ไม่ค่อยละเอียดเท่าไหร่ (หรืออ่านไม่ละเอียดเองก็ไม่รู้) แต่เดา ๆ ว่าตอนเอาไปใช้ก็อาจจะต้องคำนวณ nonconformality measure แบบในขั้นตอนที่ 2. ของ calibration process (ซึ่งเปลืองโคตรแน่นอน 555) แล้วพอเราได้ nonconformality measure ของแต่ละคำตอบมาแล้ว เราก็จะเอาแต่คำตอบที่มีค่า nonconformality measure น้อยกว่า quantile ที่เราหาไว้ในข้อที่ 3. ของ calibration process แหละมั้ง
Performance Improvement
ส่วนนี้ในเปเปอร์เค้าใช้ Bayesian optimization (ซึ่งเหมือนเค้าใช้ scikit-optimize) ในการหาว่าควรจะตั้ง error ของ RAG ($\alpha_{\text{Ret}}$) และ LLM เท่าไหร่ดี ($\alpha_{\text{LLM}}$) เพื่อจะให้ตัว error โดยรวมได้ตามที่เราอยากได้และมีขนาดของ prediction set หรือคำตอบจาก LLM เล็กที่สุด
Reference
- TRAQ: Trustworthy Retrieval Augmented Question Answering via Conformal Prediction (link)
- https://github.com/shuoli90/TRAQ/blob/main/run/traq/traq_chatgpt.py