Conformal Prediction คืออะไร ?
 ภาพจาก paper UNCERTAINTY SETS FOR IMAGE CLASSIFIERS USING CONFORMAL PREDICTION (link)
ภาพจาก paper UNCERTAINTY SETS FOR IMAGE CLASSIFIERS USING CONFORMAL PREDICTION (link)
- ตัว conformal prediction นั้น เป็นวิธีที่ใช้ในขั้นตอน inference หรือตอนเอาโมเดลมาทำนายค่าต่าง ๆ ซึ่งจะสามารถทำนายเป็น set ออกมา โดยที่ใน set นั้นจะมี class หรือค่าที่เป็นจริงอยู่มากกว่า probability ที่เรากำหนดเองได้
-
ใช้กรณีแบบที่เราบอกว่าเรายอมรับได้ถ้าหากทำนายออกมาเป็น set ที่อาจจะมีขนาดใหญ่บ้างเล็กบ้าง แทนที่จะเป็นค่า ๆ เดียว แต่ขอให้ใน set นั้นมีความน่าจะเป็นที่จะมีค่าจริงอยู่มากกว่า xx% (ซึ่งค่า xx% นี่เรากำหนดเองได้)
-
หรือถ้าเขียนเป็นสมการ conformal prediction คือการที่เราพยายามจะการันตีว่า
\begin{equation} \label{eq:V} 1 - \alpha \leq \mathbb{P}(Y_{\text{test}} \in \mathcal{C}(X_{\text{test}})) \end{equation}
โดยที่
- $\mathcal{C}(X_{\text{test}})$ คือ set ของ prediction หรือถ้าเป็นรูปข้างบนก็คือ {fox squirrel}, {fox squirel, gray fox, bucket, rain berrel}, etc.
- $\alpha$ คือ error rate หรือความน่าจะเป็นที่ $\mathcal{C}(X_{\text{test}})$ จะไม่มีค่าจริงอยู่ในนั้น
ตัวอย่าง Use Case recommendation
Backgound
- มีช๊อยของสินค้าที่จะ recommend ให้ลูกค้าแต่ละรายอยู่ 20 อัน
- เราทำโมเดล classification มาตัวนึงเพื่อทำนายว่าลูกค้าน่าจะเลือกอันไหนจาก 20 อัน
- มีเป้าหมายว่าลูกค้า 99% จะต้องได้เห็นสิ่งที่เค้าสนใจจากสิ่งที่เรา recommend ไป
Solution
ถ้าทำแบบไม่ใช้ conformal prediction
- เราอาจจะหยิบสินค้าที่ได้ prob มากที่สุดของลูกค้าแต่ละคนไป recommend ให้ลูกค้าคนนั้น ซึ่งก็ไม่น่าได้ถึง 99% ถ้าโมเดลเราไม่ได้แม่นแบบเวอร์วังขนาดนั้น
- สมมติถ้าเรามีทุนเยอะหน่อย หรือค่า recommend ไปหาลูกค้ามันไม่ได้แพงอะไร ก็อาจจะมีไอเดียประมาณ top-N โดยเราอาจจะพยายามหาค่า N ที่ทำให้ได้ตามเป้าหมาย 99% ซึ่งอาจจะได้มาซักค่านึง เช่น 5 แล้วก็ recommend สินค้าที่มี prob สูงสุด 5 ลำดับแรกที่โมเดลทำนายสำหรับลูกค้าแต่ละคน
- หรืออาจจะใช้วิธีหาค่า prob เอาว่าควรจะตัดสินค้าที่มีค่า prob เยอะกว่าเท่าไหร่ดีเพื่อ recommend ให้ลูกค้าแต่ละคนที่ทำให้ได้ตามเป้าหมาย 99% -> ท้าดามมม! นี่แหละ conformal prediction จะช่วยคุณหาค่า threshold ของ prob ที่เหมาะสมเองงงงงง ฮู้เร้
ถ้าเราทำด้วย conformal prediction
- เราจะสามารถตั้งได้ว่าขอให้อย่างน้อย 99% ของลูกค้าทั้งหมด เจอสิ่งที่เค้าสนใจจาก set ที่เรา recommend ไปให้ ซึ่งจะมั่นใจได้ด้วยว่าจะเป็นสัดส่วน 99% จริง ๆ (เดี๋ยวจะแสดงให้ดูว่ามันได้ใกล้เคียงมากกกกกกก ๆ จริง ๆ)
- ลูกค้าอาจจะทายง่าย หรือโมเดลมั่นใจมากว่า เค้าสนใจอันนี้แน่ ก็อาจจะได้รับการ recommend แค่อันเดียว
- ลูกค้าที่อาจจะทายยากหน่อย หรือโมเดลลังเลสินค้าที่เค้าน่าจะสนใจอยู่ประมาณ 3-4 อันก็จะได้รับการ recommend ทั้ง 3-4 อันนั้น โดยที่จะมีความน่าจะเป็น 99% ที่จะมีของที่ลูกค้าสนใจอยู่ใน 3-4 อันนั้น
คุณสมบัติที่น่าสนใจของ Conformal Prediction
- Statistically Rigorous: มันเป็นวิธีที่ถูก proof มาแล้วว่าจะให้ความน่าจะเป็นตามที่เรากำหนดไว้จริง ๆ
- Model-Agnostic: ใช้กับโมเดลไหนก็ได้ จะเป็น classification หรือ regression ก็ได้ แต่ในบทความนี้จะยกตัวอย่าง classification ให้ดูเพราะง่ายดี 55
- Distribution-Free: ไม่ต้องสนเลยย ว่าตัว target variable ของเรามันมี distribution แบบไหน ทำได้หมด
- Adaptive: size ของ set ที่เป็นผลลัพธ์มันจะแตกต่างกันไปตามความยากง่ายของ sample เช่น ถ้า sample นั้นมันทำนายย๊ากยาก ก็อาจจะได้ set ที่ใหญ่หน่อยหรือกว้างหน่อย (อารมณ์ประมาณว่าไม่รู้ชอบอันไหน recommend ให้หมดเลยละกัน) แต่ถ้า sample ไหนทายง๊ายง่าย ก็อาจจะมีผลลัพธ์เป็น set ที่เล็กหน่อย หรืออาจจะมีอันเดียวเลยอะไรแบบนี้ (อันนี้แน่นอนอยู่แล้ววว เอาไปอันเดียวน่ะแหละ)
การทำ Conformal Prediction เบื้องต้น
Requirement
- ข้อมูลต้องแบ่งเป็นสามส่วน ได้แก่ training set, validation set, testing set โดยที่ข้อมูลทั้งหมด ต้องเป็น iid และต้องสลับสับเปลี่ยนกันได้ (exchangability) หรือก็คือต้องเหมือน ๆ กันน่ะแหละ
- validation set ต้องใหญ่นิดนึง ประมาณ 500-1000
Step-by-Step
ในบทความนี้จะยกตัวอย่างเป็นโจทย์ classification ง่าย ๆ แบบ news classification แล้วกันนะครับ โดยเดี๋ยวเราจะทำไปทีละขั้นตอนดังแสดงในภาพด้านล่าง
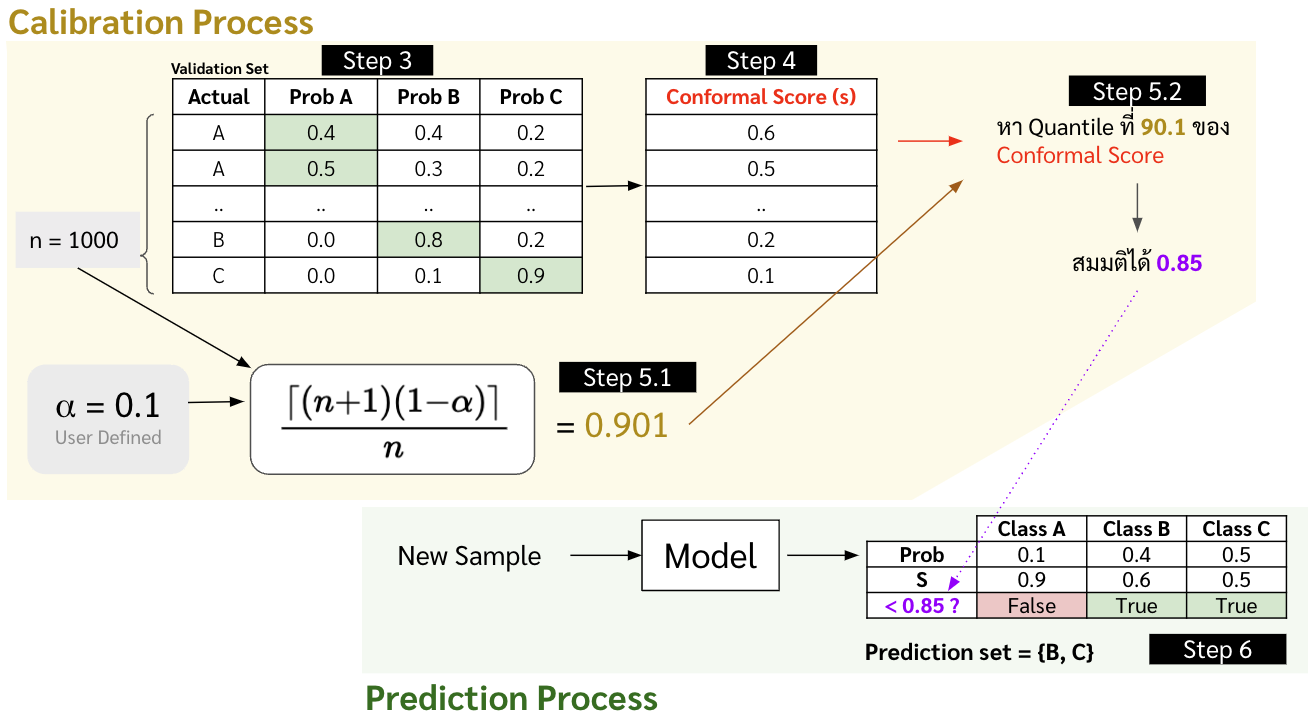
-
load training dataset แล้ว train model กับ training set ไปก่อน
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB categories = ['alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space'] newsgroups_train = fetch_20newsgroups(subset='train', categories=categories) vectorizer = TfidfVectorizer() vectors = vectorizer.fit_transform(newsgroups_train.data) clf = MultinomialNB(alpha=.01) clf.fit(vectors, newsgroups_train.target) - load unseen dataset (dataset ที่โมเดลไม่เคยเห็น) แล้วแบ่งข้อมูลออกมาส่วนนึงเป็น validation set
VALIDATION_SIZE = 800 # Get Unseen Data newsgroups_unseen = fetch_20newsgroups(subset='test', categories=categories) # TF-IDF vectors_unseen = vectorizer.transform(newsgroups_unseen.data) # Create validation set vectors_validation = vectors_unseen[:VALIDATION_SIZE] target_validation = newsgroups_unseen['target'][:VALIDATION_SIZE] ''' target_validation [1, 3, 1 ,2 , ...] ''' - เอาโมเดลที่เทรนในข้อที่ 1 มาทำนาย probability ของแต่ละ class ของข้อมูลใน validation set
# Predict on Validation set probs = clf.predict_proba(vectors_validation) '''probs array([ [2.40876175e-06, 7.23547703e-07, 9.99991701e-01, 5.16698113e-06], ..., [6.21330945e-06, 9.99917854e-01, 7.12575466e-05, 4.67474432e-06]]) ''' - คำนวณค่า conformal score (หรือ $s$) ซึ่งจะเป็นค่าที่บอกว่าค่าที่เราทำนายมันห่างจากความเป็นจริงเท่าไหร่ ซึ่งถ้าเป็นโจทย์ประเภท classification ที่ทำนาย probability ออกมา เราก็จะใช้เป็น 1 - probability ของ class ที่ถูกได้เลย ซึ่งถ้าเราจะปรับใช้กับโจทย์อื่น ๆ เราต้อง define เอาว่าตัว score นี้จะคำนวณยังไง เช่น ถ้าหากเป็น regression ก็อาจจะเอา |y_true - y_predict| อะไรแบบนี้ก็ได้
conformal_scores = 1 - probs[list(range(VALIDATION_SIZE)), target_validation] - จากนั้นเราจะหาค่า $\hat{q}$ ซึ่งเป็นค่า quantile ที่ $\frac{\left\lceil (n+1)(1-\alpha) \right\rceil}{n} $ ของ conformal score ใน validation set โดยที่
- $\alpha$ คือ error rate มีค่าระหว่าง 0 ถึง 1 (ความน่าจะเป็นที่ใน set ที่ทำนายออกมาจะไม่มีค่าจริง) ซึ่งเราจะตั้งค่าเป็น 1%
- $n$ คือจำนวนข้อมูลใน validation set นั่นเอง
ALPHA = 0.01 # ต้องการให้ set ที่เป็นผลลัพธ์ของการทำนายมีโอกาสที่จะไม่มีค่าจริงอยู่ในนั้นแค่ 1% # Calculate quantile level qth = np.ceil((VALIDATION_SIZE+1)*(1-ALPHA))/VALIDATION_SIZE # Get value of the quantile qhat = np.quantile(conformal_scores, qth, method='higher')
-
พอเราได้ $\hat{q}$ มาแล้ว เราสามารถนำไปสร้าง set of prediction บน testing set หรือ $\mathcal{C}(X_{\text{test}})$ ได้โดยการ
\begin{equation} \label{eq:xxx} \mathcal{C}(X_{\text{test}}) = \{ y : s(X_{\text{test}}, y) \leq \hat{q} \} \end{equation}
ซึ่งก็คือ code ด้านล่าง
# Create Testing set vectors_test = vectors_unseen[VALIDATION_SIZE:] target_test = newsgroups_unseen['target'][VALIDATION_SIZE:] # Predict (probability of each class) probs = clf.predict_proba(vectors_test) # Get Prediction Set s = (1-probs) pred = s < qhat ''' pred array([ [False, False, True, False], [False, True, True, True], ..., [False, True, False, False]]) ''' prediction_set = [list(np.where(row)[0]) for row in pred] ''' prediction_set หรือ C(X_test) [[2], [1,2,3], ..., [1]] ''' - มาลองหา empirical error rate
# Test (Calculate empirical Error) num_set_contain_actual = 0 set_size_list = np.array([]) for actual, pred_set in zip(target_test, prediction_set): if actual in pred_set: num_set_contain_actual += 1 set_size_list += [] print('Empirical Error: ', 1 - num_set_contain_actual/len(target_test)) ''' Empirical Error: 0.007233273056057921 '''ซึ่งจะเห็นได้ว่าในบรรดาผลการทำนายบน testing set นั้นมีแค่ประมาณ 0.7% เท่านั้นที่ไม่มีค่าจริงอยู่ ซึ่งสอดคล้องกับค่า $\alpha$ ที่เราตั้งไว้ที่ 0.01 หรือ 1% ในข้อ 5
What’s Next
ที่จริง conformal prediction ยังมีท่าอื่น ๆ นี่น่าสนใจมากมาย เช่น
- ใช้ conformal กะ regression ยังไงงงง
- จะทำยังไงให้เรา make sure ว่าคุณสมบัติ guarantee prob ไม่ได้เทไปอยู่ที่ class ใด class หนึ่ง เช่น เราตั้ง error rate ไว้ที่ 10% แต่ class A เนี่ยแบก ๆ ไปเลยได้ error 0% แต่ class B มี error 20% แล้วมันเลยได้เฉลี่ยเป็น 10% ตามที่เราตั้งไว้
- การใช้ conformal prediction ในการทำ anomaly detection
- etc
จากบทความนี้ผมคาดหวังว่าอย่างน้อยผู้อ่านน่าจะได้เห็นภาพว่า conformal prediction มันคืออะไรรร ใช้คร่าว ๆ ประมาณไหน ถ้าสนใจเพิ่มเติมและขยันก็อ่านได้ที่ reference ด้านล่าง ผมขอตัวไปอ่านอย่างอื่นต่อ จะได้มีอย่างอื่นมาเขียนให้อ่านกันต่อ (หรือถ้าขยันจะกลับมาเขียนบทความนี้เพิ่มให้ แหะ ๆ)