First Draft
บทความนี้อธิบายวิธีจากเปเปอร์ FaceNet: A Unified Embedding for Face Recognition and Clustering
ภาพรวมของ FaceNet
ใน facenet นั้น เค้านำเสนอวิธีการในการใช้ neural network เพื่อแปลงภาพหน้าคนไปเป็น vector นึงที่ represent ภาพนั้นได้ (เราเรียก vector นี้่ว่า encoding vector หรือ embedding vector)
คำว่า represent ภาพนั้นได้คือ ถ้าเราใส่ภาพเดิม ๆ หรือคล้าย ๆ เดิมเข้าไป neural network ก็ควรจะให้ vector ที่มีค่าใกล้เตียงกัน แต่ถ้าใส่ภาพที่เป็นคนละหน้าเลยเข้าไป neural network ก็ควรจะให้ vector ที่มีค่าแตกต่างกันมาก ๆ ออกมา
ซึ่งที่จริงแล้ว ก่อนหน้านี้ก็มีการใช้ neural network ในการหา representation vector จากรูปอยู่แล้ว เช่น DeepFace ซึ่งใช้วิธีในการเทรน neural network ให้สามารถ classify ได้ว่ารูปนี้เป็นรูปของใคร แล้วค่อยดึงเอาผลจาก layer ท้าย ๆ (แต่ไม่ท้ายสุด) ออกมาเป็นใช้ representation vector
 Ref:DeepFace: Closing the Gap to Human-Level Performance in Face Verification
Ref:DeepFace: Closing the Gap to Human-Level Performance in Face Verification
อย่างไรก็ตามวิธีพวกนั้น ตอนเราเทรน neural network ตัว objective หรือ loss function ที่ใช้ในการเทรนมันจะไม่ค่่อยตรงประเด็น แล้วก็ไม่ได้การันตี property ที่ว่าเราต้องการให้ใส่หน้าคนเดิมได้ vector คล้าย ๆ เดิม หรือใส่หน้าคนละคนได้ vector ที่แตกต่างกัน เพราะตัว loss function นั้นเป็น cross entropy loss ซึ่งมุ่งไปที่การ classify เพื่อความแม่นยำ ไม่ได้มุ่งเน้นที่จะสร้าง property ดังกล่าวซักเท่าไหร่
ในเปเปอร์นี้เค้าก็เลยนำเสนอวิธีในการเทรน neural network ด้วย objective แบบตรงตามที่เราต้องการเลย ก็คือเราจะใช้ neural network ที่ให้ output ออกมาเป็น encoding vector เลย (ไม่ต้องไปดึงค่า layer ท้าย ๆ มาอีกต่อไป) โดยเราจะเทรน neural network ให้มันขยับ vector ของรูปหน้าจากคนเดียวกันให้มาใกล้กัน และขยับ vector ของรูปหน้าคนจากละคนให้ออกไปไกล ๆ กันด้วย loss function ที่ชื่อว่า triplet loss
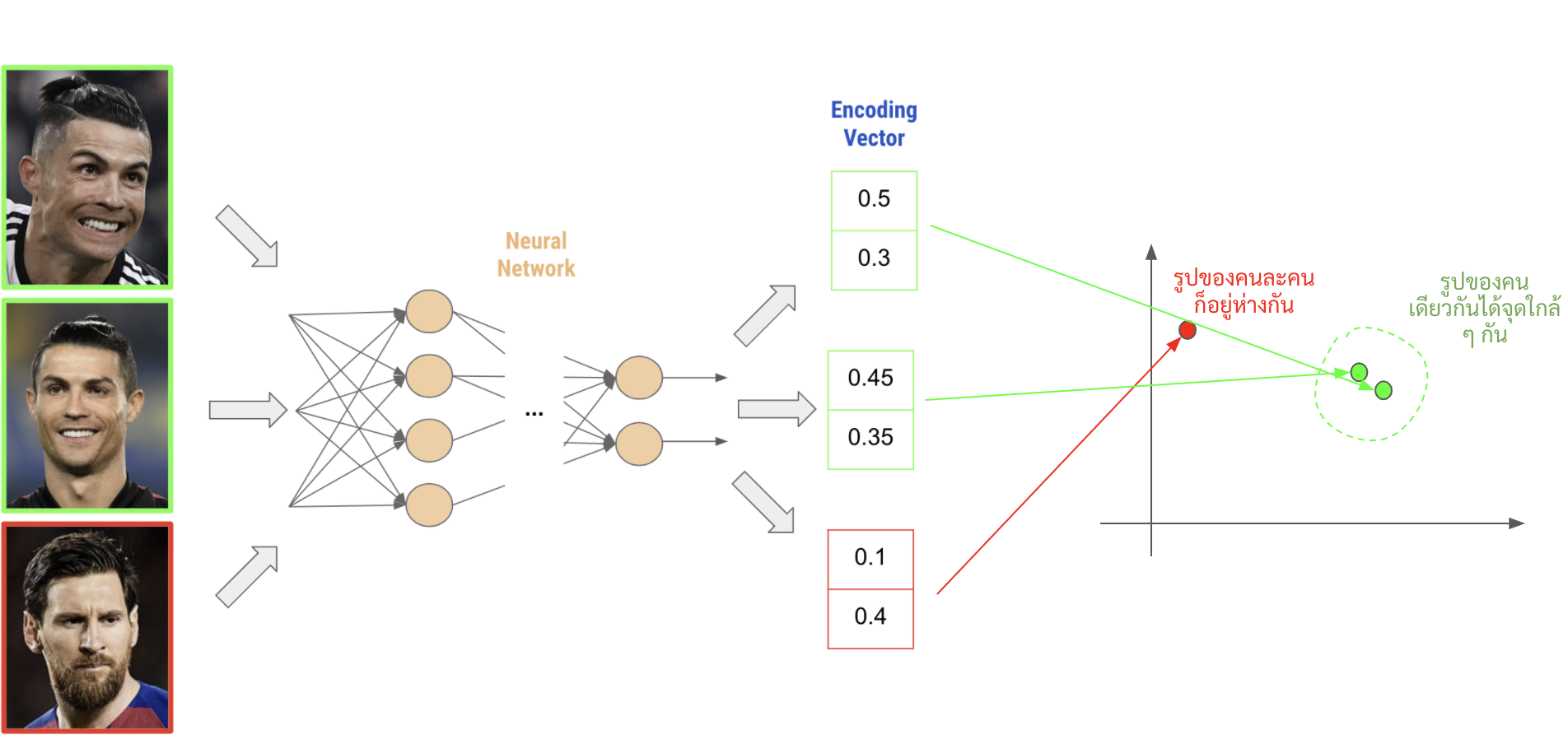
ซึ่งการที่เราหา encoding vector ของหน้าคนแต่ละหน้าออกมาได้นั้น เราก็สามารถนำ encoding vector นั้นไปใช้ทำอะไรได้หลายอย่าง เช่น การนำไปทำ Face recognition ด้วยการนำรูปหน้าคน ๆ นั้นมาเทียบกับ encoding vector ของรูปหน้าคน ๆ นั้นที่เรามีอยู่ก่อนหน้า, การทำ clustering หาว่าใน dataset เรา มีหน้าคนอยู่กี่คนอะไรก็ว่าไป
Triplet Loss
การคำนวณ Triplet loss นั้นจะมี step ดังนี้
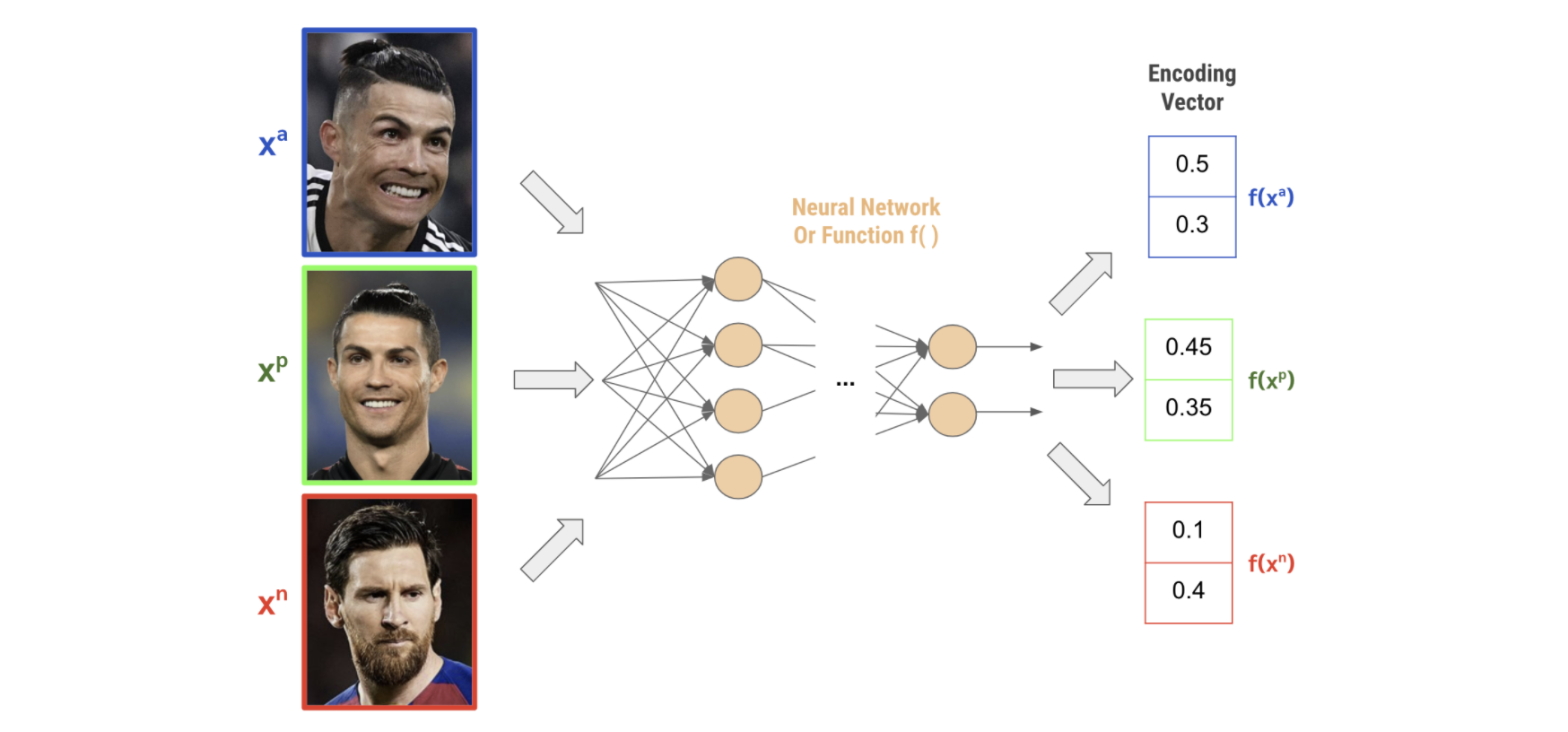
- เลือกรูปหน้าคนมาหนึ่งรูป เราจะเรียกรูปนี้ว่า anchor image ซึ่งเราจะแทนรูปนี้ด้วยตัวแปร $x^a$
- เลือกรูปอีกรูปของคนเดียวกันกับ anchor image ซึ่งเราจะเรียกรูปนี้ว่า positive image และจะแทนรูปนี้ด้วยตัวแปร $x^p$
-
เลือกรูปของคนละคนกับ anchor image มาหนึ่งรูป ซึ่งเราจะเรียกรูปนี้ว่า negative image และจะแทนรูปนี้ด้วยตัวแปร $x^n$

-
นำทั้ง 3 รูปไปผ่าน neural network (เราจะแทน neural network เป็น function $f$) เพื่อให้ได้ encoding vector ของแต่ละรูปออกมา
- หา euclidean distance ระหว่าง
-
encoding vector ของ anchor image กับ positive image เราจะแทน distance นี้ว่า $d(a,p)$
\begin{equation} \label{eq:dap} d(a,p) = ||f(x^a) - f(x^p)||^2_2 = \sqrt{(0.5-0.45)^2 + (0.3-0.35)^2} \end{equation}
-
encoding vector ของ anchor image กับ negative image เราจะแทน distance นี้ว่า $d(a,n)$ \begin{equation} \label{eq:dan} d(a,n) = ||f(x^a) - f(x^n)||^2_2 = \sqrt{(0.5-0.1)^2 + (0.3-0.4)^2} \end{equation}
-
-
จากนั้นเราก็คำนวณ triplet loss ด้วยสมการด้านล่าง
\begin{equation} \label{eq:triplet_loss} L(a,p,n) = max(d(a,p) - d(a,n) + \alpha,0) \end{equation}
สมการที่ \eqref{eq:triplet_loss} นั้นทำไมถึงมีหน้าตาแบบนี้? และค่า $\alpha$ คืออะไร? เดี๋ยวเราจะมาดูกัน
เริ่มจากสิ่งที่เราต้องการกันที่เราพูดกันไว้เมื่อตอนแรกกันก่อน สิ่งที่เราต้องการให้ neural network ทำคือให้มันทำนาย encoding vector ของแต่ละหน้าออกมา โดยที่ถ้าเป็นหน้าของคนเดียวกันก็ควรจะทำนาย encoding vector ที่มีค่าใกล้ ๆ กัน แต่ถ้าเป็หน้าของคนละคนกัน ก็ควรทำนาย encoding vector ที่มีค่าห่าง ๆ กันหน่อย
ซึ่งก็พูดได้อีกอย่างว่าเราต้องการให้ค่า distance ระหว่าง encoding vector ของสองรูปของคนเดียวกันนั้นมีค่าน้อยกว่า distance ระหว่าง encoding vector ที่มาจากรูปคนละคนกัน
\begin{equation} \label{eq:opjective} d(a,p) < d(a,n) \end{equation}
ซึ่งก็แปลว่าค่า $d(a,p) - d(a,n)$ นั้น ยิ่งน้อยก็ยิ่งดีสินะ งั้นเราก็เขียน loss function เป็นแบบสมการด้านล่างไปเลยสิ หรือก็คือเราจะ minimize ค่า $d(a,p) - d(a,n)$ ให้น้อยที่สุดเท่าที่จะเป็นไปได้
\begin{equation} \label{eq:opjective-3} L(a,p,n) = d(a,p) - d(a,n) \end{equation}
ซึ่งดูเผิน ๆ มันก็ดีแล้วแหละ แต่ว่าถ้าเราใช้ loss นี้เนี่ย neural network มันจะโกงเราได้ด้วยการทำตัวเป็น function ที่ไม่ว่าจะใส่รูปอะไรเข้าไปก็จะได้ embedding vector เดียวกันออกมา ซึ่งถ้าเป็นแบบนี้ $d(a,p)$ และ $d(a,n)$ ก็จะเป็น 0 ทั้งคู่ และเมื่อเอามาลบกันก็จะได้ 0 ก็เท่ากับว่ามันสามารถบรรลุผลสำเร็จในการ minimize loss นี้ได้แล้ว
เราก็เลยต้องแก้ปัญหาด้วยการบวก loss มันด้วยตัวแปร $\alpha$ หรือค่า margin ที่จะบอกว่าอย่างน้อย ๆ แล้ว embedding vector ของ positive ควรจะเหมือนกับของ anchor มากกว่าที่ embedding vector ของ negative เหมือนกับของ anchor เท่าไหร่
\begin{equation} \label{eq:opjective-4} L(a,p,n) = d(a,p) - d(a,n) + \alpha \end{equation}
ซึ่งจริง ๆ แล้วก็คือ เราต้องการให้ $d(a,n) - d(a,p) \geq \alpha$ นั่นเอง
ตัวอย่างการใช้ triplet loss
ในบทความนี้จะแสดงการเทรน neural network ด้วย triplet loss แบบง่าย ๆ ให้ดู เพื่อแสดงให้เห็นว่า triplet loss นั้นสามารถทำงานได้จริง ๆ และโค้ดโดยคร่าวนั้นจะเป็นอย่างไร ซึ่งข้อมูลที่ใช้นั้นจะขอใช้เป็นแค่ triplet เดียว (3 ภาพ) แทน dataset ใหญ่ ๆ แล้วกัน จะได้เทรนเร็ว ๆ แล้วก็ใช้ embedding vector ที่มีขนาดแค่ 2 ก็น่าจะพอ ซึ่งจะง่ายต่อการ visualize ให้ดูกัน
ใน Facenet จริง ๆ นั้นใช้พวก GoogleLeNet, Inception model โดยที่มีขนาด output หรือ embedding vector เป็น 128
-
ก่อนอื่นก็ขอเลือก triplet ออกมาอันนึงก่อน (3 ภาพ) ดังแสดงในรูปด้านล่าง
import cv2 anchor = cv2.imread('ronaldo-2.jpeg') positive = cv2.imread('ronaldo.jpg') negative = cv2.imread('messi.jpg') f, axes = plt.subplots(1,3, facecolor='white', figsize=(15,5)) axes[0].set_title('Anchor') axes[0].imshow(cv2.cvtColor(anchor, cv2.COLOR_BGR2RGB)) axes[1].set_title('Positive') axes[1].imshow(cv2.cvtColor(positive, cv2.COLOR_BGR2RGB)) axes[2].set_title('Negative') axes[2].imshow(cv2.cvtColor(negative, cv2.COLOR_BGR2RGB))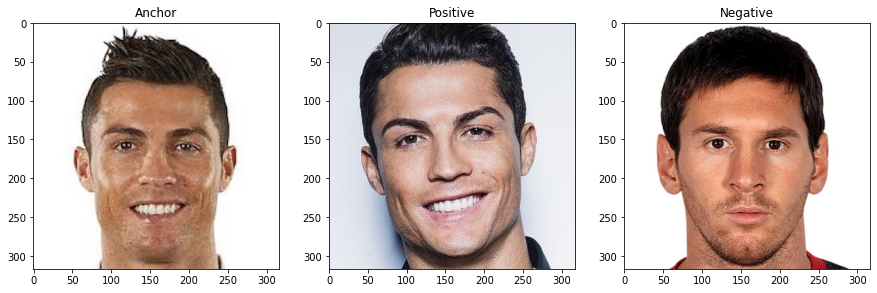
-
ต่อมาก็สร้างโมเดล เอาแบบง่าย ๆ เลย กับสร้าง optimizer เตรียมไว้
input_layer = Input(shape=(317,317,3)) cnn = Conv2D(filters=20,kernel_size=(10,10),activation='relu')(input_layer) pooling = MaxPooling2D((10,10))(cnn) cnn = Conv2D(filters=20,kernel_size=(3,3),activation='relu')(pooling) pooling = MaxPooling2D((2,2))(cnn) flatten = Flatten()(pooling) dense = Dense(100, activation='relu')(flatten) output = Dense(2, activation='linear')(dense) embedding = l2_normalize(output, axis=1) model = Model(input_layer,embedding) optimizer = Adam(learning_rate=0.000001) -
แล้วก็เทรนโมเดลด้วย Triplet loss ด้วย code ด้านล่าง
## เอาไว้เก็บประวัติการเทรน list_of_embedding_anchor = [] list_of_embedding_positive = [] list_of_embedding_negative = [] list_loss = [] ## ค่า margin alpha = 0.5 ## เทรนไป 1000 รอบ for i in range(1000): with tf.GradientTape() as tape: ## หา embedding ของทั้ง 3 รูป embedding_anchor = model(anchor.flatten()[np.newaxis,:]) embedding_positive = model(positive.flatten()[np.newaxis,:]) embedding_negative = model(negative.flatten()[np.newaxis,:]) ############ ## คำนวณ loss ############ ## หาระยะทางระหว่าง embedding ของ anchor และ positive images หรือค่า d(a,p) d_ap = tf.norm(embedding_anchor-embedding_positive, ord='euclidean', axis=1) ## หาระยะทางระหว่าง embedding ของ anchor และ negative images หรือค่า d(a,n) d_an = tf.norm(embedding_anchor-embedding_negative, ord='euclidean', axis=1) ## max(d(a,p) - d(a,n) + alpha,0.0) loss = tf.maximum(d(a,p) - d(a,n) + alpha, 0.0) ## หา mean ของ loss จากทุก triplet (แต่จริง ๆ แล้วตอนนี้เราเทรนด้วย triplet เดียว) loss = tf.reduce_mean(loss, axis=0) ## หา gradient ของ model parameter ต่อค่า loss ที่หาไว้ grad = tape.gradient(loss, model.trainable_variables) ## อัพเดท neural network ไปตาม gradient ที่หาไว้ optimizer.apply_gradients(zip(grad, model.trainable_variables)) ## เก็บประวัติการเทรนว่าในแต่ละ epoch นั้น ตัว embedding vector ที่ทำนายออกมาหน้าตาเป็นอย่างไร list_of_embedding_anchor.append(embedding_anchor.numpy()[0]) list_of_embedding_positive.append(embedding_positive.numpy()[0]) list_of_embedding_negative.append(embedding_negative.numpy()[0]) list_loss.append(loss.numpy()) ## ถ้า loss เป็น 0 แล้วก็ไม่ต้องเทรนแล้ว if loss.numpy()==0: break ## แปลงประวัติเป็น numpy array และนำไปทำ animation ในข้อต่อไป list_of_embedding_anchor = np.vstack(list_of_embedding_anchor) list_of_embedding_positive = np.vstack(list_of_embedding_positive) list_of_embedding_negative = np.vstack(list_of_embedding_negative) triplet_history = np.concatenate([list_of_embedding_anchor[:,np.newaxis], list_of_embedding_positive[:,np.newaxis], list_of_embedding_negative[:,np.newaxis]], axis=1) -
มาดูกันว่าระหว่างที่เทรน neural network นั้น ตัว embedding vector ของแต่ละภาพอยู่ตรงไหนและเคลื่อนที่อย่างไรบ้าง โดยที่
- วงกลมสีน้ำเงินคือตำแหน่งของ embedding ของ anchor
- วงกลมสีน้ำเขียวคือตำแหน่งของ embedding ของ positive
- วงกลมสีน้ำแดงคือตำแหน่งของ embedding ของ negative
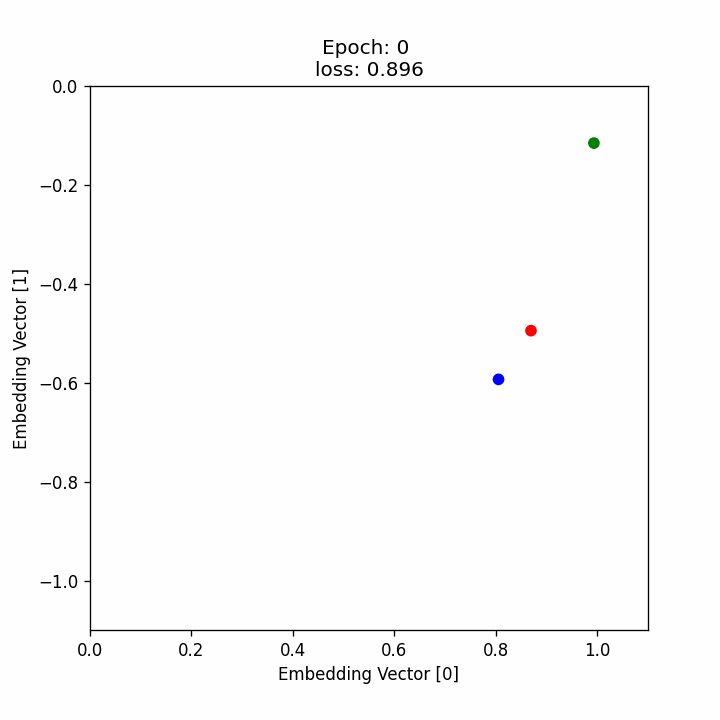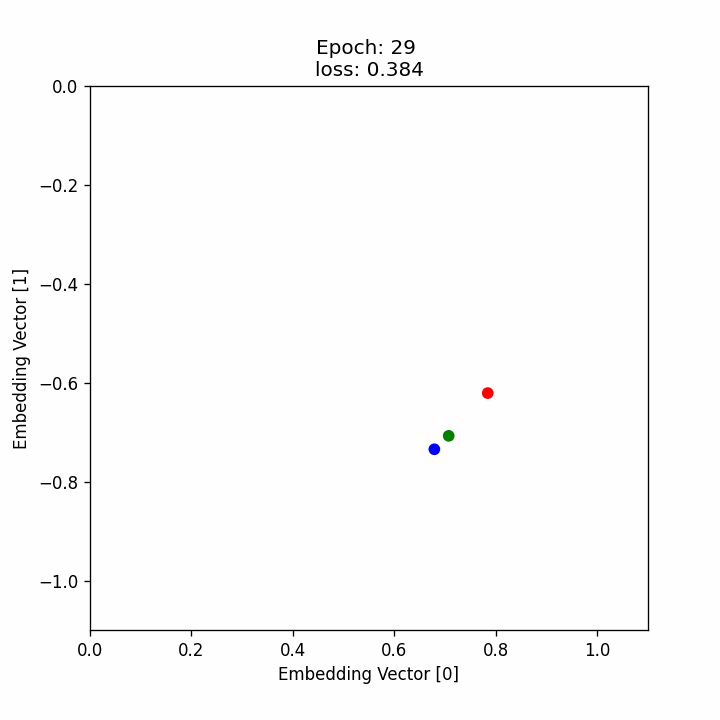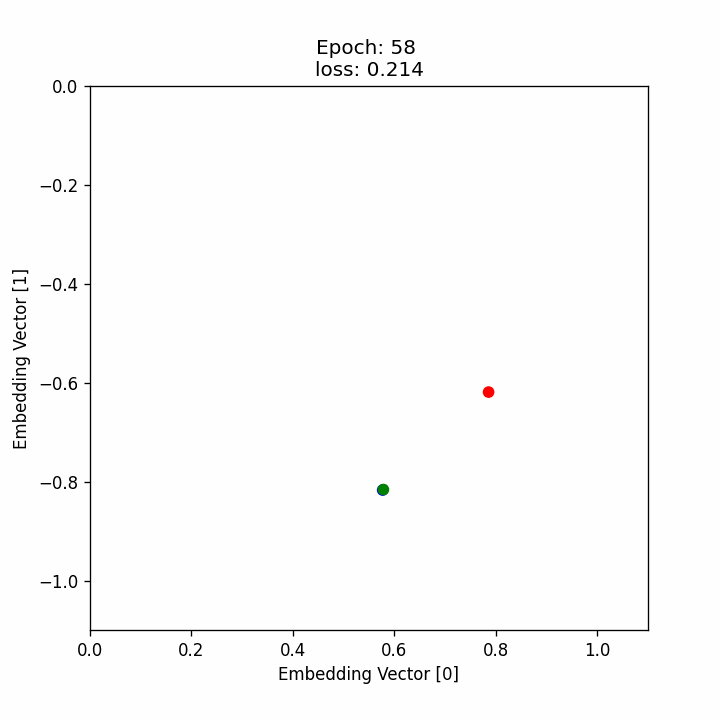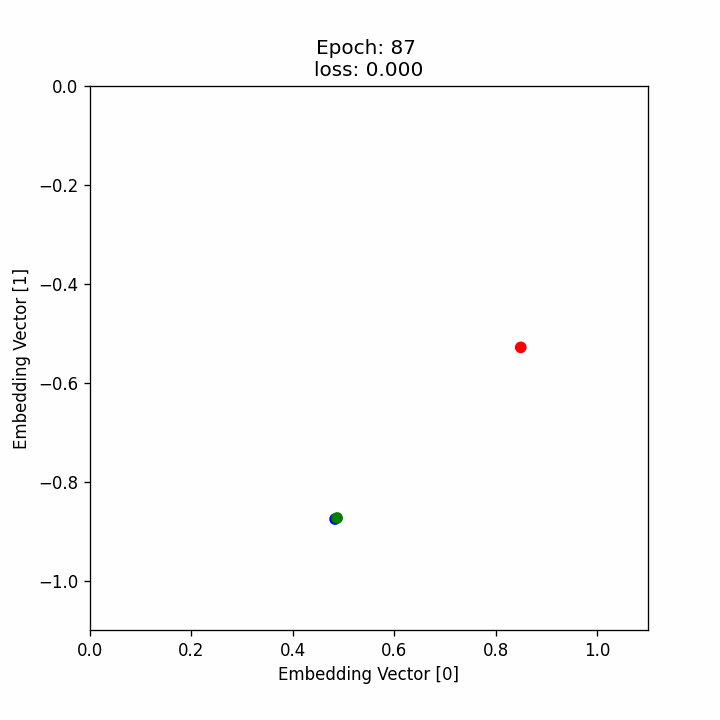
ซึ่งจะเห็นได้ว่า เมื่อเทรนไปเรื่อย ๆ จุดสีเขียวจะขยับเข้าไปหาจุดสีน้ำเงิน ในขณะที่จุดสีแดงจะขยับออกห่างจุดสีน้ำเงินมากขึ้นเรื่อย ๆ หรือก็คือค่า embedding vector ของ anchor และ positive image นั้นจะมีค่าใกล้กันมากขึ้นเรื่อย ๆ ในขณะที่ค่า embedding vector ของ anchor และ negative image นั้นจะมีค่าต่างกันมากขึ้นเรื่อย ๆ
สำหรับใครที่อยากลองเข้าไปเล่น ไปลองเปลี่ยนภาพดู หรือเปลี่ยนค่า $\alpha$ ก็สามารถเข้าไปตาม colab นี้ได้เลยครับ
Tip:Triplet Selection
ที่จริงแล้ว หลัก ๆ ของ Facenet ก็คือการใช้ Triplet loss น่ะแหละจะจบตรงนี้เลยก็ได้ แต่ว่ามันก็ยังมีอีกปัญหานึงคือวิธีการเลือก triplet (ภาพ 3 ภาพ) แต่ละชุดนั้น ถ้าเราเลือกแบบสุ่มมั่ว ๆ มีโอกาสที่ neural network จะเรียนรู้ช้ามาก ๆๆๆๆๆ ได้
เนื่องจากว่าเกิดกรณีของ triplet ที่มีภาพ anchor กับภาพ positive ที่เหมือนกันมาก และภาพ anchor กับ negative ที่ต่างกันมาก ๆ (ซึ่งก็มักจะต่างกันพอสมควรอยู่แล้ว) จะทำให้ loss function ของ triplet นั้นเป็น 0 ซึ่งจะทำให้ neural network นั้นไม่ได้เรียนรู้อะไรเพิ่มเติมจากเดิมเลย
เพราะฉะนั้นแล้วในการสร้าง triplet นั้น เราก็ควรจะเลือกภาพ positive ที่ไม่เหมือนกับ anchor มากไป และภาพ negative ที่ไม่ต่างกับ anchor มากไป
Disclaimer
รายละเอียดในบทความนี้มาจากความเข้าใจส่วนตัว อาจมีข้อผิดพลาด หากพบจุดผิดพลาด ขอความกรุณาแจ้งทาง facebook หรือ email: thammasorn.han@hotmail.com