บทความนี้มาจากเปเปอร์ mixup: Beyond Empirical Risk Minimization
TL;DR
mixup คือการ augment data ด้วยการสุ่มหยิบข้อมูลมา 2 ชิ้น (ข้อมูลจะเป็นตัวเลข หรือรูป หรือเป็นเสียงก็ได้) แล้วเอาทั้ง feature และ label ของทั้ง 2 รูปมาบวกกันแบบ weighted sum เพื่อสร้างข้อมูลใหม่ขึ้นมา เค้าบอกว่าจะช่วยให้โมเดลสามารถทำงานกับ unseen data ได้ดีขึ้น (ลด overfit) โดยที่ weighted นั้นจะสุ่มมาจาก $\beta(\alpha,\alpha)$ distribution โดยเรามักจะตั้งค่า $\alpha$ ประมาณ 0.2-0.4
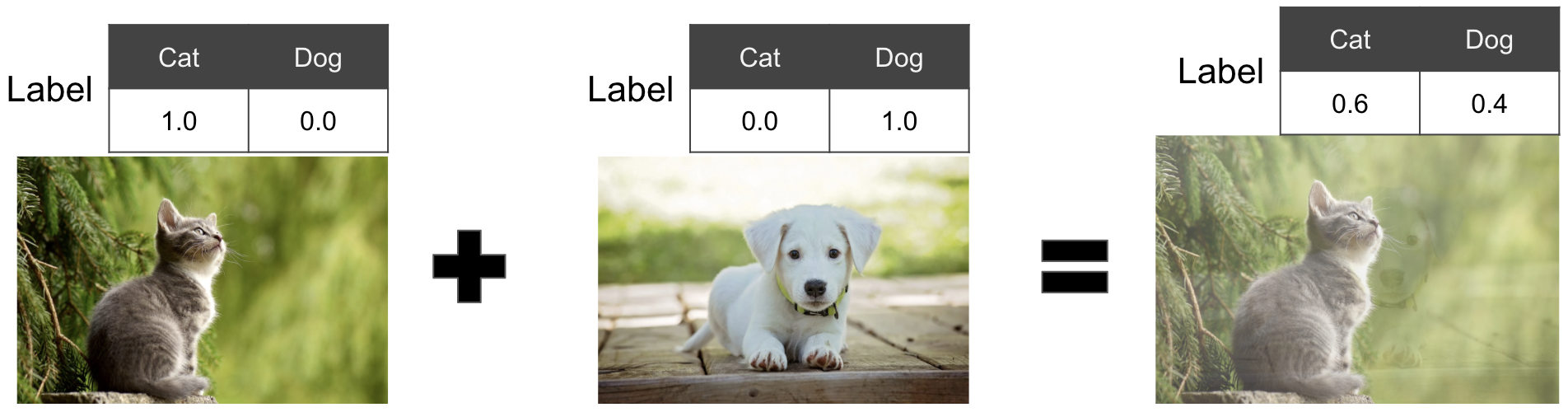
Mixup คืออะไร เอาไว้แก้ปัญหาอะไร?
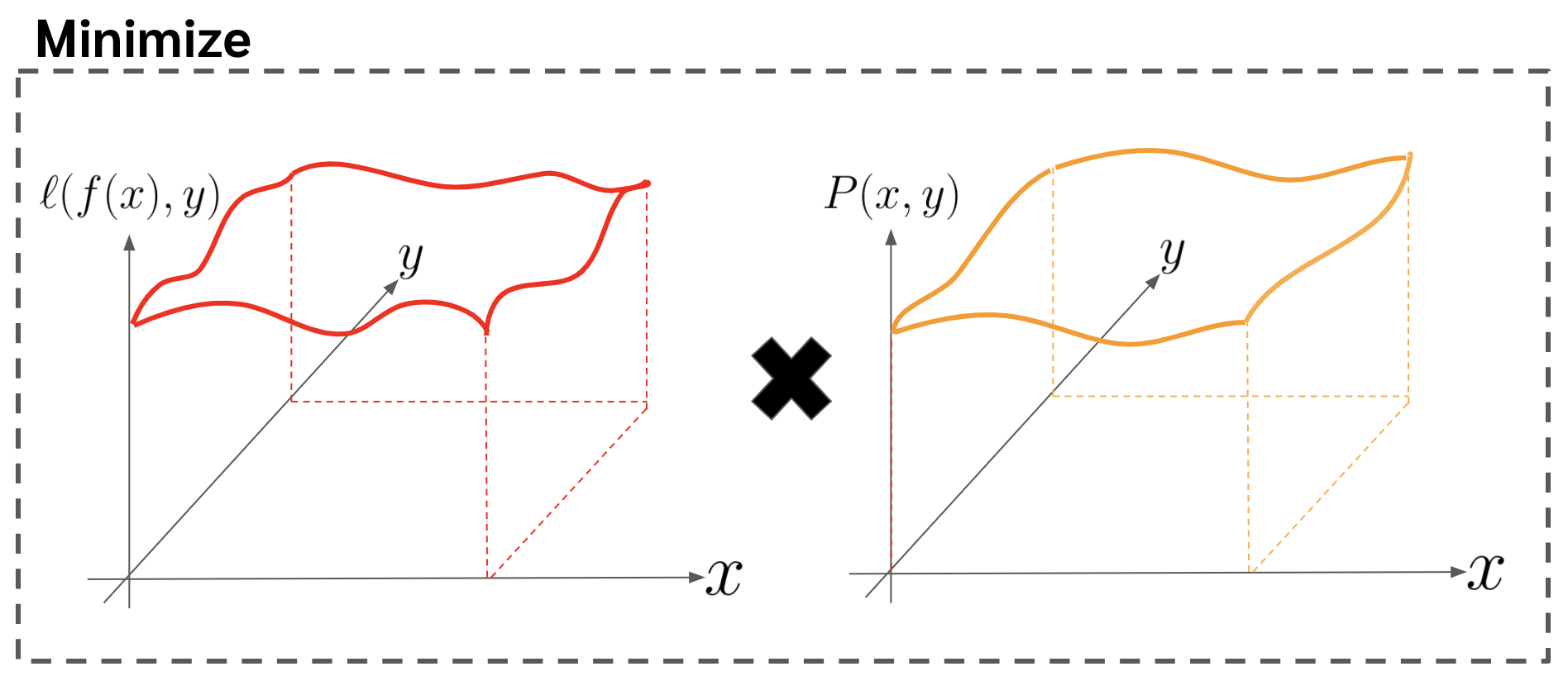
ในเปเปอร์เค้าบอกว่าจริง ๆ แล้ว objective function ของการ classsification นั้น เป็นการที่เราพยายามที่จะลด loss ดังสมการด้านล่าง
\begin{equation} \label{eq:loss_integrate} R(f) = \int \ell (f(x),y)dP(x,y) \end{equation}
โดยที่
- $x$ คือ feature
- $y$ คือ label
- $\ell$ คือ loss function เช่น cross entropy loss
- $f(x)$ คือ classification model ที่ใส่ data $x$ เข้าไปและทำนายออกมาเป็น probability ของแต่ละ class
- $P(x,y)$ คือ probability ของการมีอยู่ของคู่อันดับ $(x,y)$
ซึ่งก็คือเค้าสมมติว่าเรามี data อยู่จำนวนอนันต์ สิ่งที่เราต้องการจะลดคือ loss ของทุก data point ตามน้ำหนัก probability ของแต่ละ data point นั้น
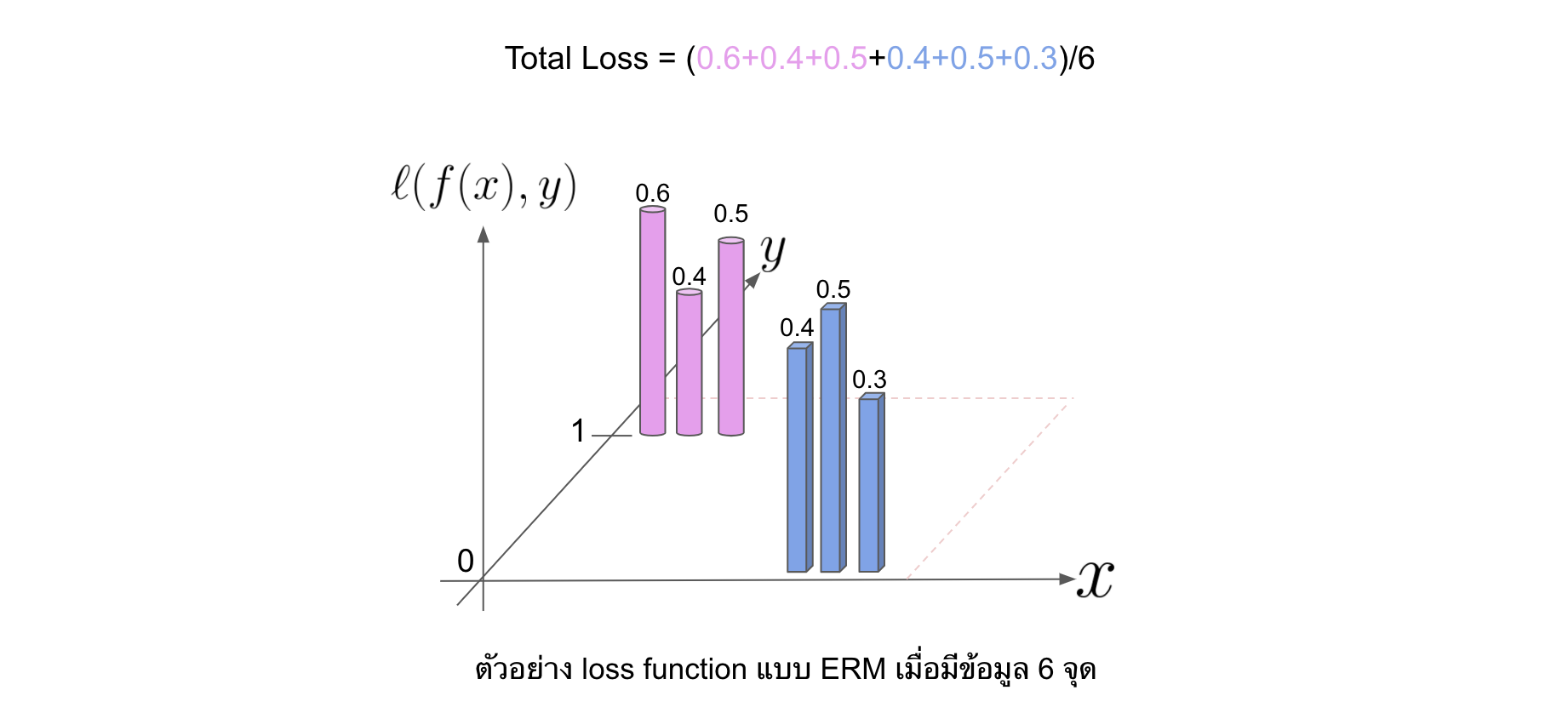
แต่ในโลกแห่งความเป็นจริง เรามี dataset จำนวนจำกัด (เช่น 1,000 รูป) เพราะฉะนั้นแล้วสิ่งที่เราทำอยู่ตอนนี้คือการลด average loss ที่คำนวณมาจาก dataset ที่มีจำนวนจำกัดดังสมการด้านล่าง โดยที่วิธีนี้ก็มีชื่อเรียกแบบเก๋ ๆ ว่า Empirical Risk Minimization (ERM)
\begin{equation} \label{eq:loss_sum} R(f) = \frac{1}{n} \sum_{i=1}^{n} \mathcal{\ell}(f(x_i),y_i) \end{equation}
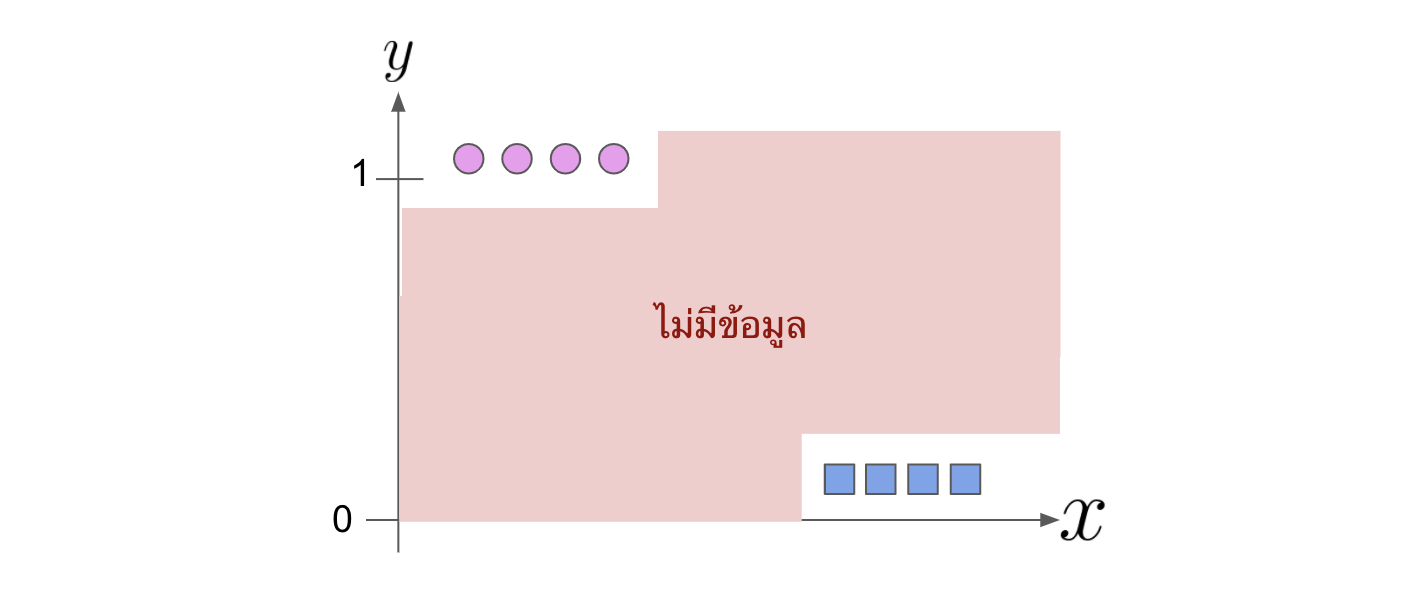
ซึ่งมันก็ถูกแหละ แต่มันมีปัญหาหนึ่งคือข้อมูลที่อยู่ตรงกลางระหว่างแต่ละ class นั้นเราจะไม่มีเลย เพราะเวลาเรา label ตอนเทรน เราก็ label เป็น probability ของแต่ละ class เป็น 0 หรือ 1 ไป แต่ว่าถ้าเรามองย้อนไปที่สมการ \eqref{eq:loss_integrate} นั้นจะพบว่าจริง ๆ แล้วเราสมมติว่าค่า y นั้นเป็น continuous หรือก็คือเราสมมติว่ามันมีข้อมูลที่อยู่ตรงกลางระหว่างสอง class ด้วย งั้นก็แปลว่าจริง ๆ เรามีข้อมูลไม่ครบน่ะสิ ซึ่งปัญหาที่ตามมาก็คือ model มัน overfit ง่าย
ที่นี้คนเขียน mixup เค้าเลยเสนอวิธีแบบง่าย ๆ (แต่ใช้งานได้ดีนะ) ขึ้นมา ก็คือเราก็สร้าง data ระหว่าง class ขึ้นมาเองเลยซะสิ ด้วยการสุ่มหยิบ data จากทั้งสอง class มา weighted sum กัน ทั้งฟีเจอร์หรือ $x$ และ label หรือ $y$ เพื่อสร้างข้อมูลใหม่ $(\widetilde{x},\widetilde{y})$
\begin{equation} \label{eq:mixup_x} \widetilde{x} = \lambda x_1 + (1-\lambda) x_2 \end{equation}
\begin{equation} \label{eq:mixup_y} \widetilde{y} = \lambda y_1 + (1-\lambda) y_2 \end{equation}
โดยที่ตัว $\lambda$ นั้นมีค่าอยู่ระหว่าง 0 ถึง 1 ซึ่งในการสร้างข้อมูล $(\widetilde{x},\widetilde{y})$ แต่ละครั้งนั้น เราจะสุ่มค่า $\lambda$ มาจาก $\beta(\alpha,\alpha)$ ซึ่งตัว probability density function ของ $\beta$ distribution ที่แต่ละระดับของ $\alpha$ นั้นจะแสดงดังรูปด้านล่าง
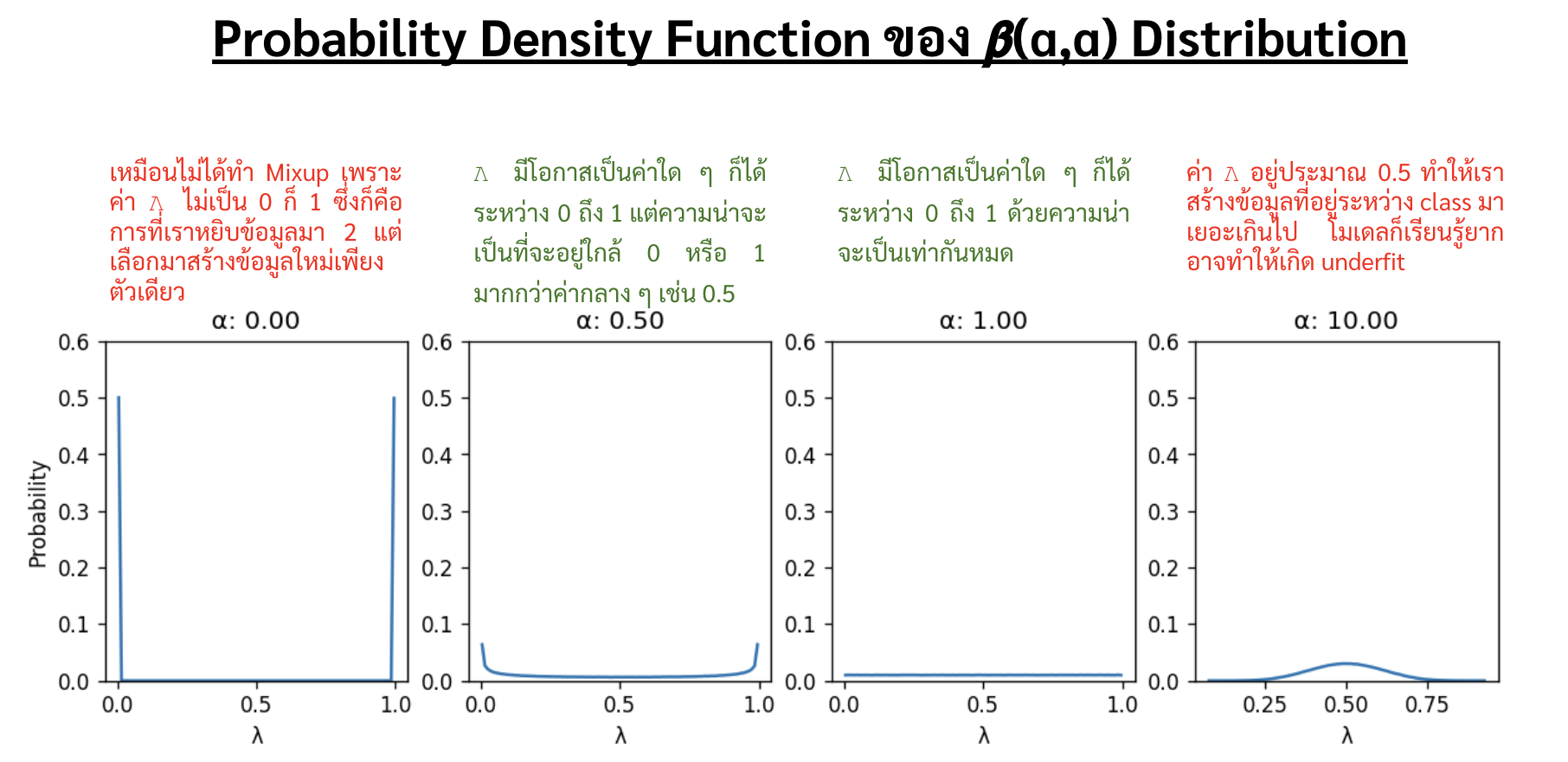
ซึ่งจะเห็นได้ว่า ค่า $\alpha$ นั้นเป็นตัวกำหนดระดับของการเอาฟีเจอร์มาผสมกัน ถ้า $\alpha = 0$ ก็คือเราไม่ได้ทำ mixup เลย (จากรูป PDF จะเห็นได้ว่าเมื่อ $\alpha=0$ เราจะได้ $\lambda$ อยู่ที่ไม่ 0 ก็ 1 ซึ่งเป็นการให้น้ำหนักข้อมูลแค่เพียงชิ้นเดียว) แต่ถ้า $\alpha$ เยอะเกินไปนั้นค่า $\lambda$ จะอยู่แค่แถว ๆ 0.5 อย่างเดียว ซึ่งอาจจะทำให้ underfit ได้ เพราะเราสร้างข้อมูลตรงครึ่ง ๆ กลาง ๆ ให้โมเดลเรียนเยอะไป
เพื่อให้เห็นภาพชัดขึ้น เลยทำรูปด้านล่างมาให้ดู
- สมมติว่าเรามีข้อมูลดังรูปซ้ายสุด ($\alpha=0$) จะเห็นว่าทั้ง 2 classes ของเรานั้นห่างกันพอสมควร
- พอทำ mixup ที่ค่า $\alpha=0.1,1.0$ นั้นจะเห็นว่าข้อมูลที่ mixup สร้างขึ้นมานั้นเป็นเหมือนสะพานทอดระหว่าง 2 classes
- แต่ถ้า $\alpha=10.0$ จะเห็นได้ว่าข้อมูลจะถูกแบ่งเป็น 3 กลุ่ม โดยมีกลุ่มตรงกลางโผล่มา ซึ่งกลุ่มสีน้ำเงินกับสีแดงนั้น ที่จริงมันเกิดจากการสุ่มหยิบข้อมูลสองข้อมูลในคลาสเดียวกันมา weighted sum กันเอง มันเลยได้ข้อมูลในกลุ่มตัวเอง ส่วนกลุ่มสีเหลืองตรงกลางนั้นเกิดจากค่า $\lambda$ ที่มักจะกอง ๆ อยู่แถว 0.5 แล้วเอาข้อมูลมาบวกกันระหว่างสองคลาส

ในเปเปอร์เค้าก็ทดลองใช้ mixup กับข้อมูล ImageNet แล้วก็พบว่าเทคนิค mixup สามารถลด error ได้ประมาณ 1% ถ้วน ซึ่งที่จริงหลาย ๆ คนก็อาจจะคิดว่าไม่เยอะเท่าไหร่ แต่ว่าก็เป็นทางเลือกที่ดีในการเพิ่ม accuracy ให้โมเดล เพราะก็เป็นวิธีที่นำมาใช้ไม่ยาก ไม่ต้องปรับอะไรมากมายแต่ได้ผล ในการแข่งขันบน kaggle ก็จะเห็นคนเอามาใช้อยู่บ่อย ๆ
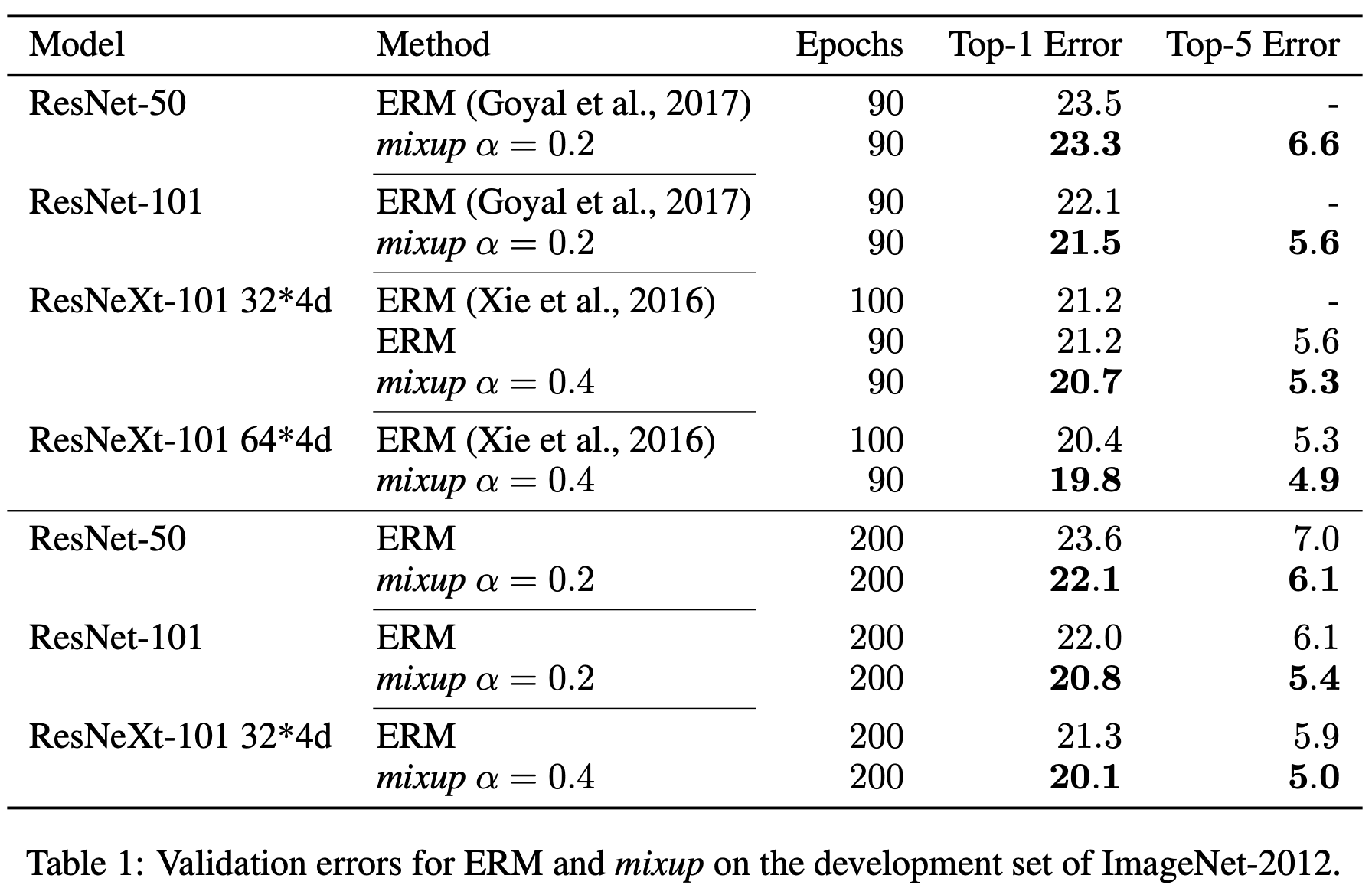
Ref: mixup: BEYOND EMPIRICAL RISK MINIMIZATION
สำหรับคนที่ต้องการใช้ mixup กับข้อมูลประเภทรูปภาพก็สามารถตามไปที่ github ของคุณ yu4u ได้เลย เค้า implement เป็น data generator ของ tensorflow ไว้ทำให้เราใช้ง่าย ๆ
Disclaimer
รายละเอียดในบทความนี้มาจากความเข้าใจส่วนตัว อาจมีข้อผิดพลาด หากพบจุดผิดพลาด ขอความกรุณาแจ้งทาง facebook หรือ email: thammasorn.han@hotmail.com