อธิบายวิธีจากเปเปอร์ Deep Clustering for Unsupervised Learning of Visual Features (2018)
Introduction
ในโลกนี้ เราอาจจะอยาก classify รูปอะไรก็ได้เต็มไปหมด ซึ่งก่อนหน้านี้เราก็ใช้วิธีแบบ supervised-learning ซึ่งเราก็ต้องมีทั้งข้อมูลรูปและข้อมูลที่บอกว่ารูปนั้นเป็นรูปอะไร หรือก็คือจัดกลุ่มรูปให้ก่อน แต่สมมติว่าถ้ารูปพวกนั้นมันเยอะเกิน เราจะมานั่ง label ที่ละรูปก็เหนื่อยอยู่นะ
ซึ่งจริง ๆ แล้วการ classify มันก็คือการที่เราพยายามสร้างโมเดลมาจัดกลุ่มรูปน่ะแหละ ให้รูปประเภทเดียวกันอยู่ในกลุ่มเดียวกันอะไรแบบนี้
ซึ่งจากปัญหาว่าถ้าเราขี้เกียจ label รูปทั้งหมดก่อนมาเทรนโมเดล เราจะจัดกลุ่มรูปยังไง? ก็เลยมีนักวิจัยเค้าพยายามจะใช้ deep learning ในการ extract ฟีเจอร์ออกจากรูปก่อน (ซึ่งฟีเจอร์พวกนั้นถูกเรียกได้หลายแบบ representation, high-level feature, latent vector) แล้วค่อยเอาฟีเจอร์พวกนั้นไปทำ clustering อีกที ซึ่งวิธีที่เค้าทำกันมาก็เช่น
-
การสร้าง autoencoder กับรูปพวกนั้นขึ้นมาก่อน แล้วค่อยพอ autoencoder ดีพอแล้ว เราก็เอาตัว encoded vector ไปทำ cluster แต่ว่าด้วยความที่วิธีนี้มันต้อง operate กันในระดับ pixel หรือก็คือโมเดลเราต้อง learn ทุก pixel แล้วเราต้องสร้างทุก pixel ให้เหมือนเดิมอีก ทำให้วิธีนี้มันค่อนข้างจะ conputational expensive (รันนาน รันหนัก)
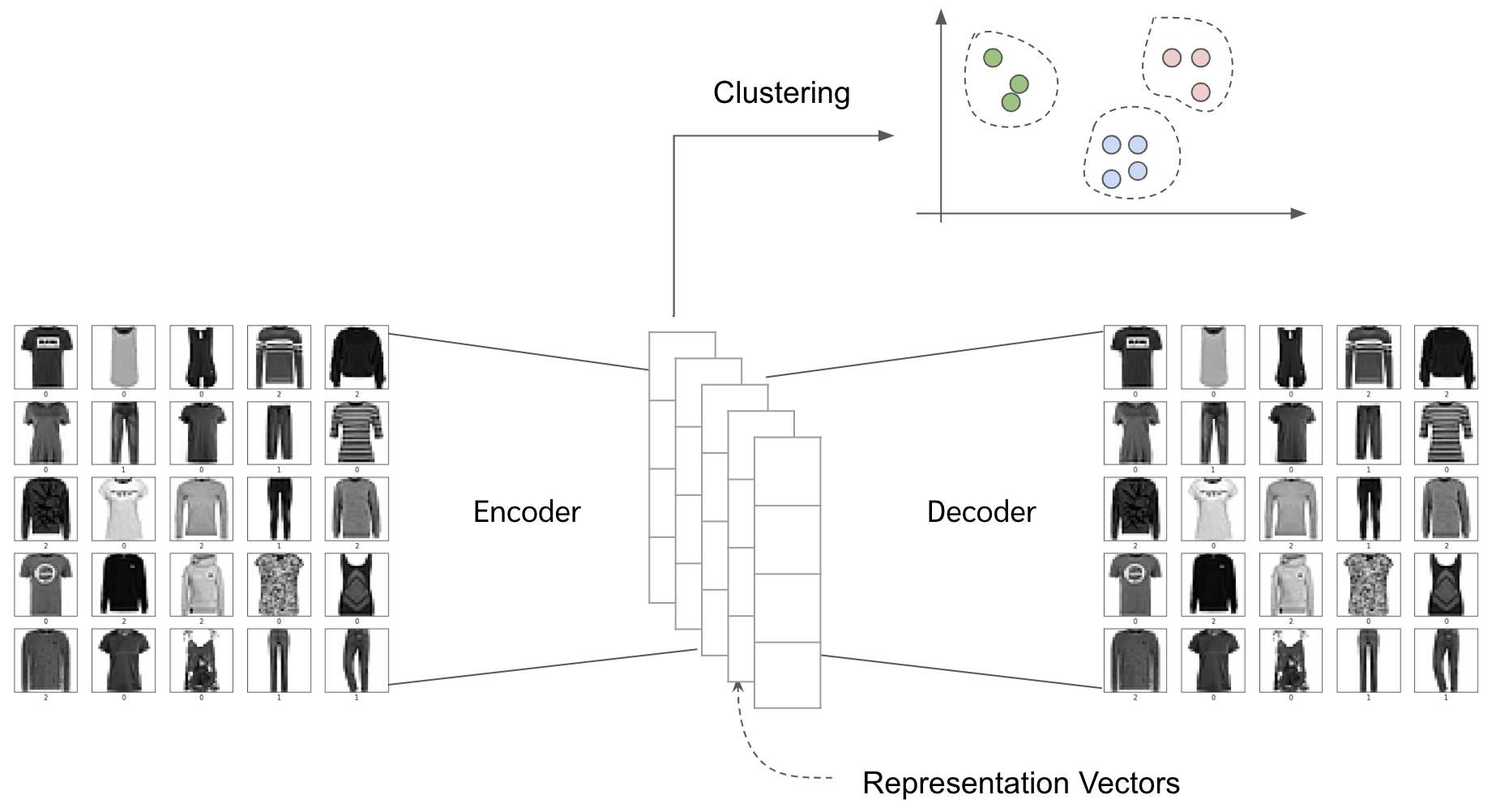
- การสร้างโมเดลที่ฝึกด้วย pretext task หรือก็คือฝึกให้โมเดลมันทำอย่างอื่นจนเก่งก่อน แล้วเราค่อยดึง activation value จาก layer ท้าย ๆ มาใช้ ตัวอย่าง pretext task ได้แก่
-
การประมาณองศาการหมุนของรูป
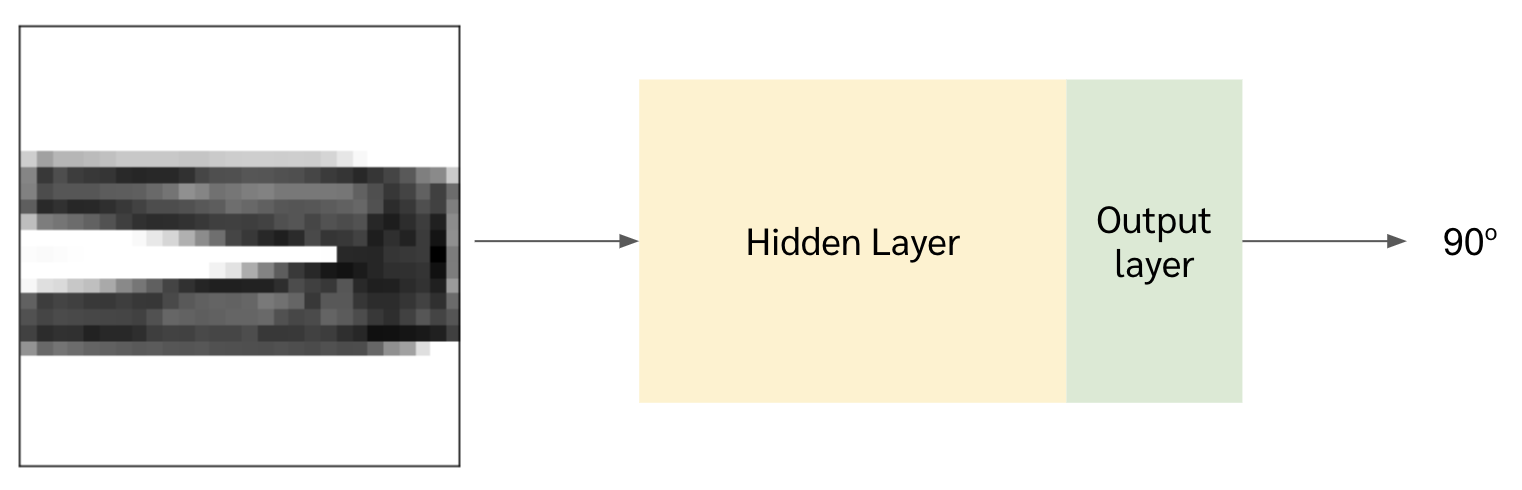
ปล. ต้องอย่าลืมว่าเราไม่มี label แต่เราเล่นกับรูปได้ จะเอามาหมุนหรือจะเอามาทำอะไรก็แล้วแต่
ทีนี้อาจจะงงกันว่าการประมาณองศาการหมุนของรูปนี่มันเกี่ยวอะไรด้วยหว่า หรือมัน make sense ตรงไหน ทำไมเราถึงบอกได้ว่าโมเดลเรามันเข้าใจรูปภาพนั้น ๆ จากการที่ให้มันเรียนที่จะหมุนภาพ
งั้นสมมติว่า เราเห็นอักขระโบราณตัวนึงที่เราไม่เคยเห็นเลยตามด้านล่าง สมมติผมถามว่าเรารู้รึเปล่าว่ารูปไหนคือรูปที่ถูกต้องของอักขระนั้น (จะเห็นได้ว่าทุกรูปคือรูปเดียวกัน แต่หมุนคนละองศากันเฉย ๆ) ?
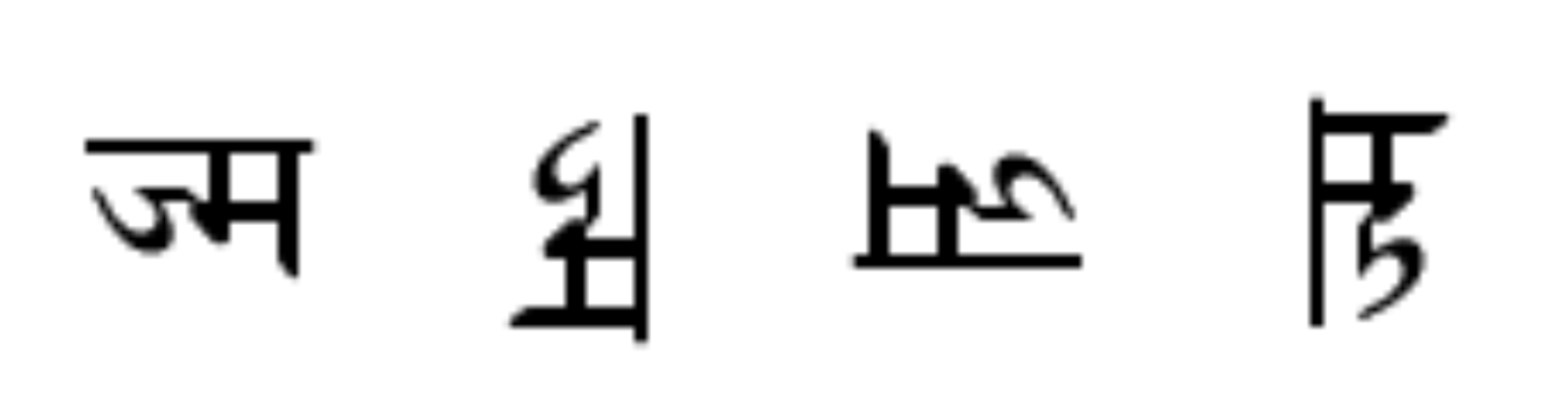
คำตอบคือผมเองก็ไม่รู้ (เป็นคนเอามาหมุนเองยังจำไม่ได้เลย 555) แต่ในรูปด้านบนที่เป็นกางเกงหมุนนั้น เราดูปุ๊ปก็รู้เลยว่ามันหมุนไป 90 องศา มันเป็นเพราะว่าเรารู้จักมันอยู่ก่อนแล้ว เราเลยรู้ว่าจริง ๆ แล้วมันหน้าตายังไง เพราะฉะนั้นเค้าเลยเชื่อกันว่าถ้าเราฝึกให้โมเดลมันเรียนรู้ที่จะรู้ได้ว่ารูปที่มันเห็นผ่านการหมุนมากี่องศา จะทำให้โมเดลเรารู้ลึก ๆ ว่ารูปนั้นคือรูปอะไร
-
ที่จริงยังมี pretext task อื่น ๆ อีก เช่น การระบายสีรูป บลาๆ เอาไว้ถ้ามีโอกาสจะเขียนรายละเอียดให้เพิ่มเติมนะครับ
ซึ่งที่จริงแล้ว pretext task เนี่ยมีให้เลือกทำเยอะแยะมากมาย ประเด็นคือเราจะเลือก pretext task ไหนมาทำดี ซึ่งในเปเปอร์นี้เค้าก็บอกว่าการเลือก pretext task นี่ก็แอบลำบากหน่อย ๆ เพราะมันเป็น domain dependent อย่าง pretext task ที่เป็นการประมาณองศาการหมุนรูปนี่ถ้าเราเอาไปใช้กับ dataset ที่ประกอบไปด้วย ลูกบอล ลูกตะกร้อ ลูกกอล์ฟอะไรงี้ก็คงจะไม่ได้ (หมุนยังไงมันก็เหมือน ๆ กัน)
-
-
ที่จริงแล้วเดี๋ยวนี้เหมือนเค้าจะไปฮิตวิธี contrastive learning กัน ซึ่งเป็นวิธีที่โมเดลจะพยายามขยับ representation ของรูปเดียวกัน (แต่เอา crop มา หรือหมุนนิดหน่อย) ให้ใกล้กัน และขยับตัว representation ของคนละรูปให้ไปไกล ๆ กัน
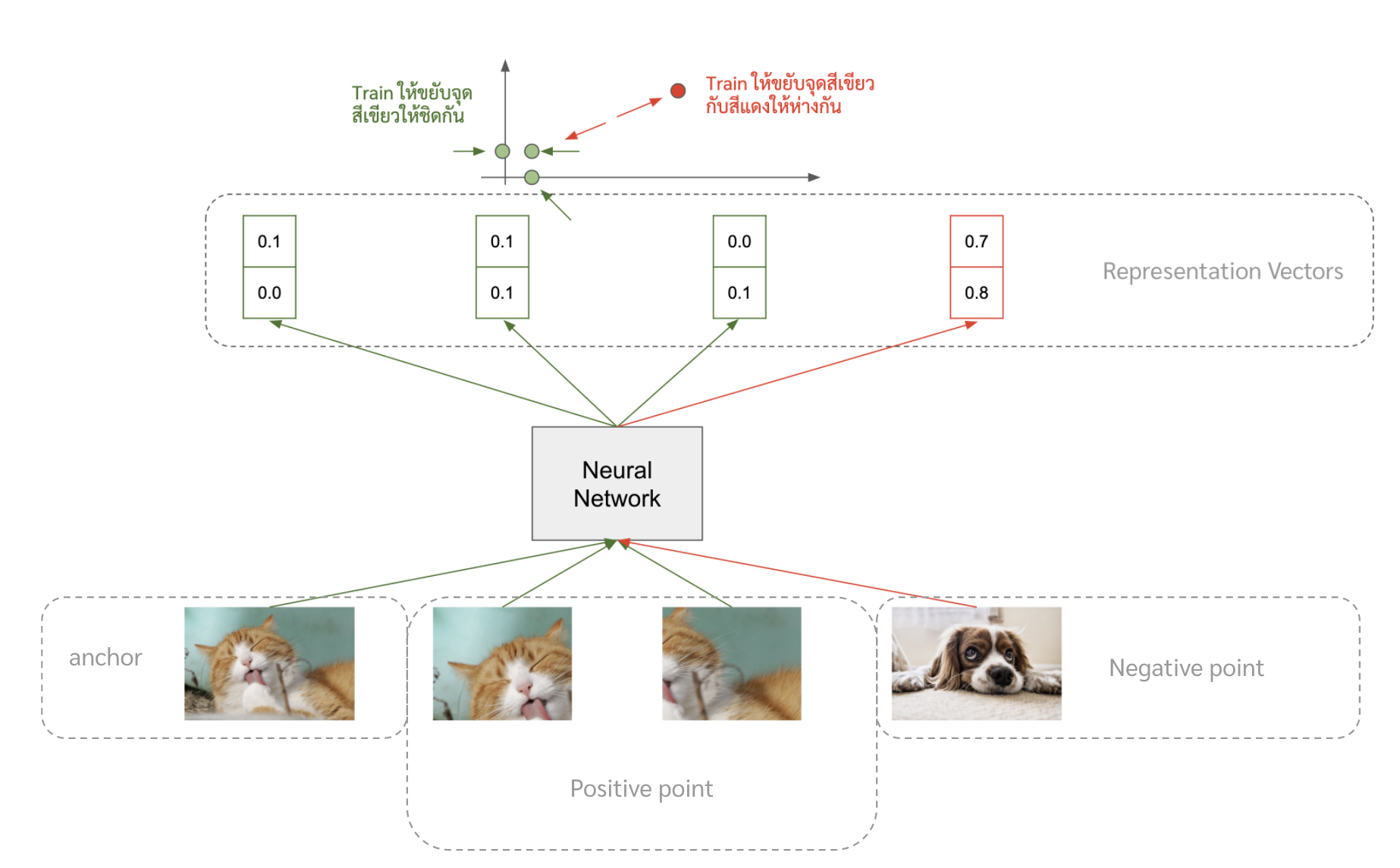
เอาไว้ถ้ามีโอกาสจะเขียนรายละเอียดของพวกนี้ให้เพิ่มเติมนะครับ
Deep Clustering
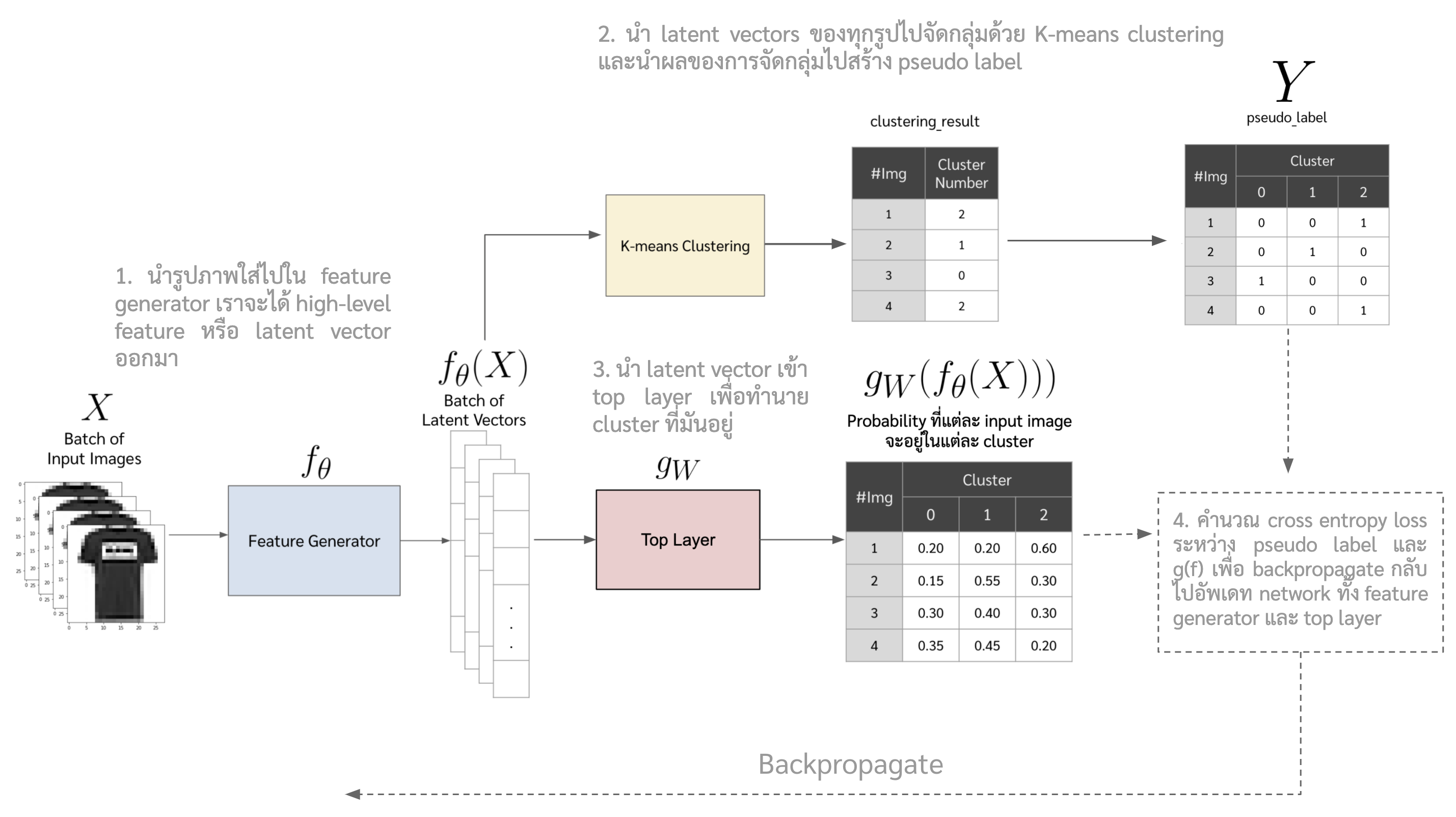
ในเปเปอร์นี้เค้านำเสนอวิธีการการจัดกลุ่มของรูปแบบ end-to-end แบบที่ไม่ได้อยู่ในสองกลุ่มข้างต้น ซึ่งวิธีก็คือสร้าง label ปลอม ๆ ขึ้นมา (pseudolabel) ด้วยการเอา high level feature ของ image ไป clustering แล้วเอาผลของการ clustering มาเป็น pseudo label ให้ network เราเทรน แล้วก็วนกลับไปสร้าง pseudo label แล้วก็เทรนไปเรื่อย ๆ ตอนนี้อาจจะงง ๆ หน่อย แต่เดี๋ยวไว้ดูวิธีข้างล่างเอาแล้วกันนะ
สมการนี้ไม่ต้องดูก็ได้ ไปดูอีกทีภาพรวมของ DeepCluster เลย
เป้าหมายหรือ objective function ที่นำเสนอในเปเปอร์นี้แสดงดังสมการด้านล่าง
\begin{equation} \label{eq:deep_cluster} \min_{\theta,W} \frac{1}{N} \sum_{n=1}^{N} \ell (g_{W}(f_{\theta}(x_n)),y_n) \end{equation}
โดยที่
- \(x_n\) คือรูปหรือข้อมูลนำเข้า
- \(f_{\theta}\) คือ neural network ชุดแรกที่เราเรียกว่า feature generator ซึ่งมีไว้ extract ฟีเจอร์จากรูป ซึ่งฟีเจอร์จากรูปนั้นจะเป็น vector ขนาดตามที่เรากำหนดไว้ หรือเราจะเรียก vector พวกนั้นว่า latent vector
- \(g_W\) คือ neural network ที่เราเรียกว่า top layer จะต่อออกไปจาก feature generator และจะให้ output เป็นเลข pseudo label ซึ่งถ้าดูตามสมการข้างบนจะเห็นว่า
- $g_W$ เป็นฟังก์ชันของ $f_{\theta}$ ซึ่งก็คือมันรับ output ของ $f_{\theta}$ มาเป็น input ของตัวมัน
- และเรานำ $g_W(f_{\theta})$ ไปเทียบกับ $y$ ซึ่งก็คือ pseudo label เพื่อคำนวณ loss
- \(y\) คือ pseudo label ที่เกิดจากการนำ output จาก \(f_{\theta}\) ไปเข้า Kmeans clustering แล้วเอาเลข cluster มาเป็น pseudo label
- \(\ell\) คือ cross entropy loss
ซึ่งภาพรวมของ DeepCluster ก็จะประมาณนี้
Implementation (Simplified version)
ในส่วนนี้จะขอ implement เป็น simplified version เพื่อให้เข้าใจ step การทำงานได้ง่ายขึ้น (ซึ่ง performance ของเวอร์ชั่นที่ implement นี้จะแย่กว่าของจริงมาก 55) และเดี๋ยวจะเขียนรายละเอียดที่เค้าทำจริง ๆ ในเปเปอร์ควบคู่ไปด้วยครับ
ซึ่งถ้าใครอยากเอาวิธีนี้ไปใช้จริง ๆ แนะนำให้ไปใช้โค้ดที่ผู้เขียนเปเปอร์เค้า implement ไว้ดีกว่าครับ ^^
- สำหรับโค้ดที่ทางผู้เขียนเปเปอร์เค้า implement ไว้ ตามไปที่ link นี้ได้เลยครับ (เป็น Pytorch)
- สำหรับโค้ดที่เรา implement แบบง่าย ๆ เองก็ตามไปที่ link นี้ครับ (เป็น Keras)
ในบทความนี้เราจะใช้ข้อมูล mnist แค่ 3 classes จำนวน 5,000 รูปเท่านั้น

ขั้นตอน
-
อ่านข้อมูลรูปมา
from tensorflow.keras.datasets import fashion_mnist, mnist, cifar10 (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() train_labels = train_labels.ravel() train_images = train_images[np.isin(train_labels,[0,1,2])][:5000,:,:]/255.0 train_labels= train_labels[np.isin(train_labels,[0,1,2])][:5000]ที่จริงแล้ว ในเปเปอร์เค้าทำเป็น pipeline แล้วมีการ augment รูป (การ shift, rotate, crop, ฯลฯ) แบบสุ่มด้วย
-
ทำ sobel ซึ่งเป็น edge detection algorithm หนึ่งใช้เพื่อหาขอบของวัตถุในรูป
from tensorflow.image import sobel_edges,rgb_to_grayscale from tensorflow.keras import backend as K import tensorflow as tf image = tf.constant(train_images[:,:,:,np.newaxis], dtype=tf.float32) grad_components = sobel_edges(image) grad_mag_components = grad_components**2 grad_mag_square = tf.math.reduce_sum(grad_mag_components,axis=-1) grad_mag_img = tf.sqrt(grad_mag_square) images = (K.eval(grad_mag_img))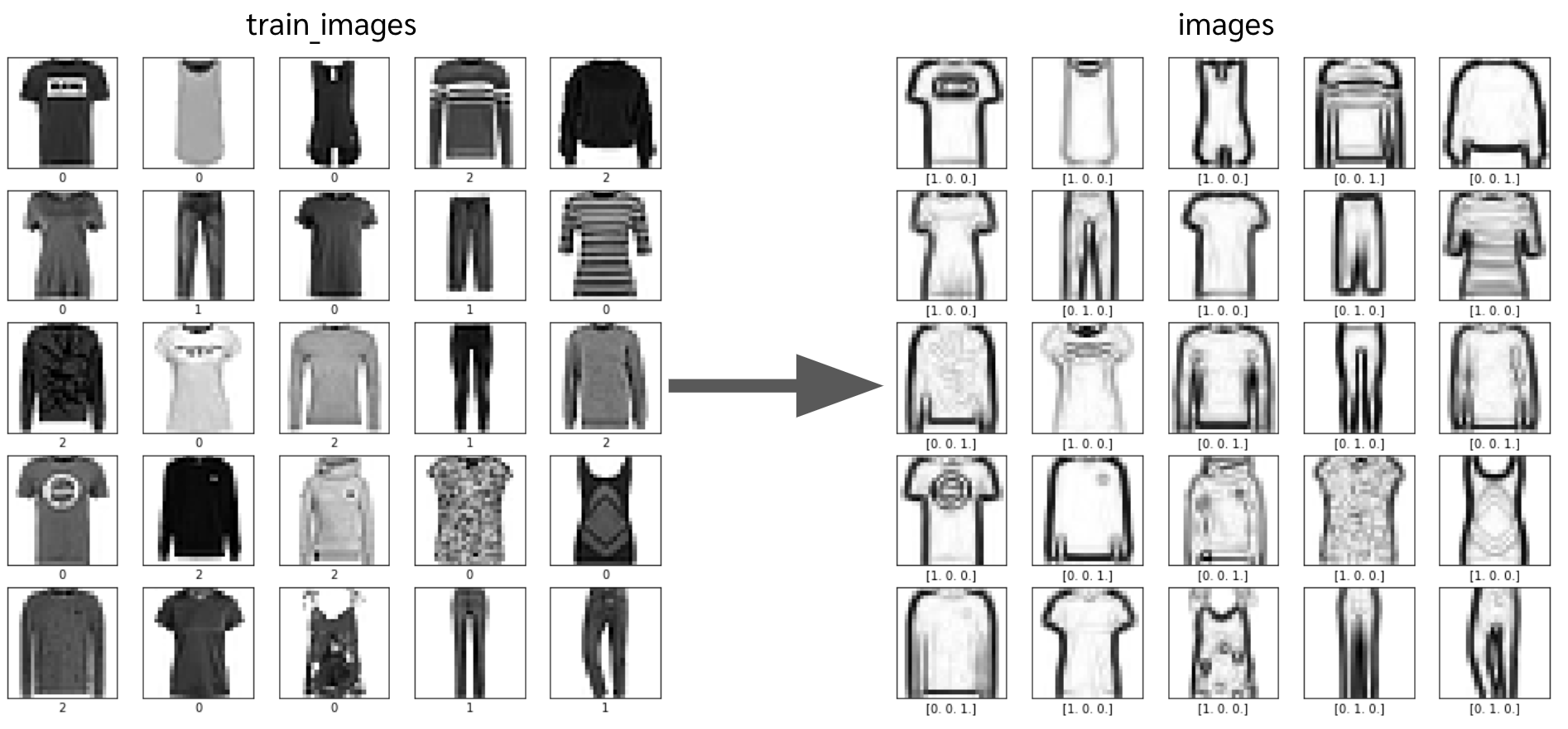
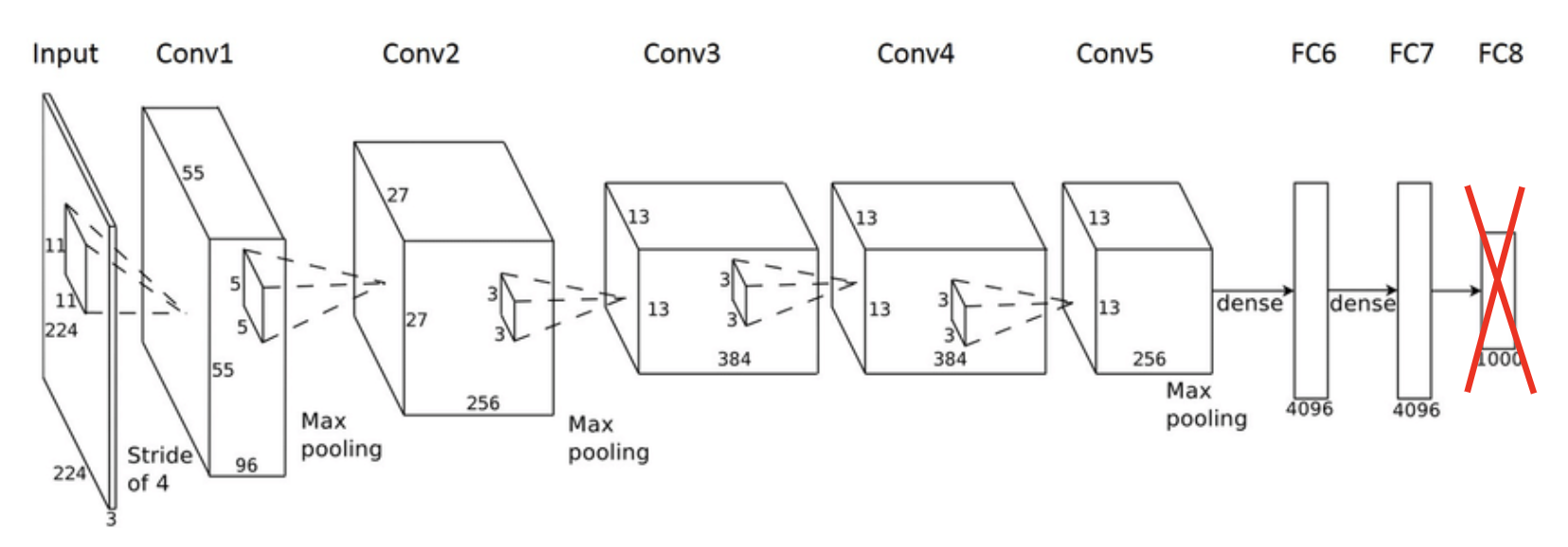
- สร้างโมเดลส่วน feature generator ซึ่งเป็นโมเดลที่เอาไว้สกัด high-level feature ของแต่ละรูปออกมา
-
ในที่นี้ขอ implement เป็น CNN2D + Fully Connected ง่าย ๆ แล้วกัน
input_layer = Input(shape=(28,28,1)) cnn = Conv2D(8, (4, 4), padding="same", activation="relu")(input_layer) cnn = MaxPooling2D((2, 2))(cnn) cnn = Flatten()(cnn) dense = Dense(128,kernel_initializer='random_normal', bias_initializer='zeros',activation='relu')(cnn) feature_vector = Dense(4,kernel_initializer='random_normal', bias_initializer='zeros')(dense) feature_generator = Model(input_layer,feature_vector) feature_generator.summary()
โดยที่ในเปเปอร์เค้าจะใช้เป็น VGG16 หรือ Alexnet ตัด layer สุดท้ายออก (ไม่ต้อง pretrain มาก่อน)
-
-
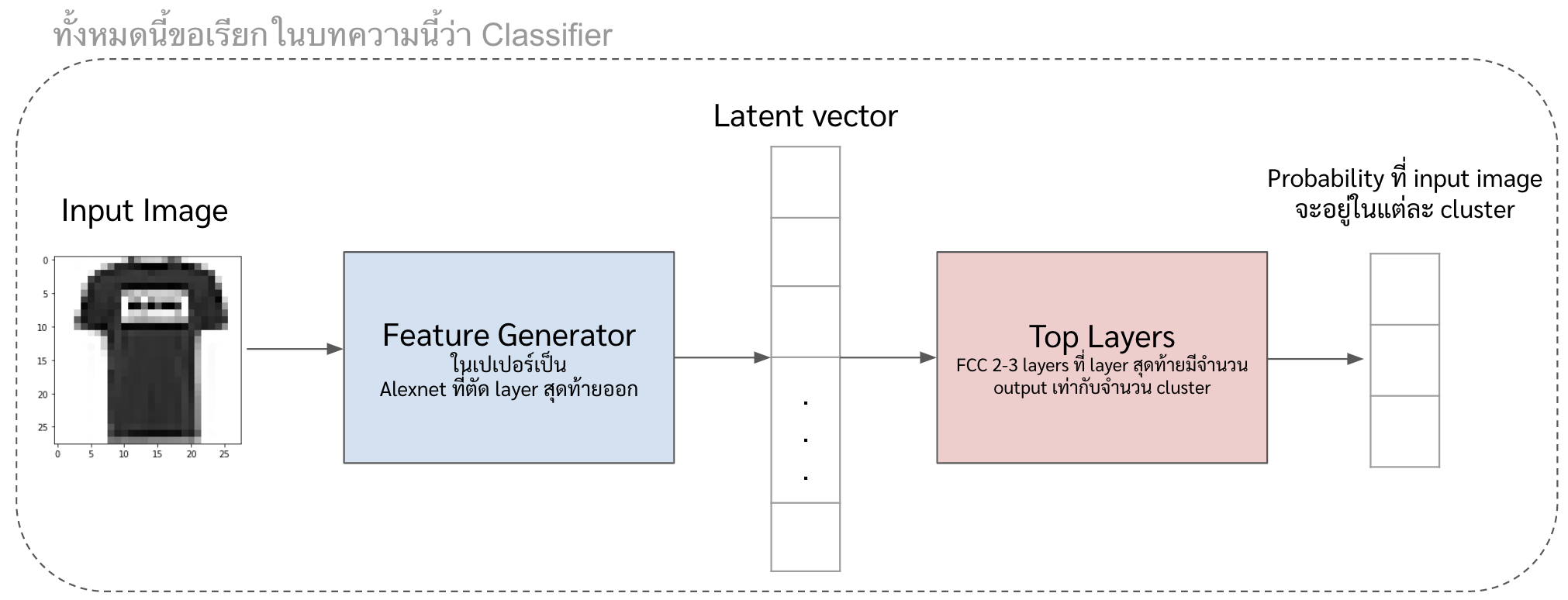
ทำฟังก์ชันสร้างโมเดล classifier โดยการต่อ layers (เราจะเรียกว่า top layers) ออกมาจาก feature generator อีกที
ซึ่ง top layers ทำหน้าที่รับ input เป็น high-level feature (ที่ออกมาจาก feature generator) แล้ว classify feature พวกนั้นตาม pseudo label
-
ที่นี้โค้ดที่ implement ออกมาจะประมาณนี้ จะเห็นได้ว่าใน layer แรก หรือ
ReLUนั้นรับ input เป็นfeature_vectorซึ่งก็คือ layers สุดท้ายของfeature_generatorในข้อก่อนหน้าfrom tensorflow.keras.initializers import RandomNormal def gen_classifier(): dense_w = ReLU()(feature_vector) dense_w = Dense(16, activation='relu',kernel_initializer='random_normal', bias_initializer='zeros')(dense_w) classify_output = Dense(n_cluster, activation='softmax', kernel_initializer=RandomNormal(mean=0.0, stddev=0.01, seed=None), bias_initializer='zeros')(dense_w) classifier = Model(input_layer,classify_output) classifier.compile(optimizer=SGD(learning_rate=0.0005, momentum=0.0), loss='categorical_crossentropy', metrics='accuracy') return classifier
-
-
ทดลองทำ clustering ตอนนี้เลย แล้วดูผล จะได้เก็บไว้เทียบหลังเทรนได้
from sklearn.cluster import KMeans from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import normalized_mutual_info_score from sklearn.metrics import confusion_matrix import matplotlib.gridspec as gridspec n_cluster = 3 ## ใช้ feature generator ในการหา latent_vector ออกมา features = feature_generator.predict(images) ## เอา latent_vector ไปทำ kmeans kmeans = KMeans(n_clusters=n_cluster, random_state=131).fit_predict(features) ## หา NMI Score nmi_score = normalized_mutual_info_score(kmeans, train_labels) ## โค้ดในการพล็อต รบกวนตามไปดูในโค้ดฉบับเต็มนะครับ .... ....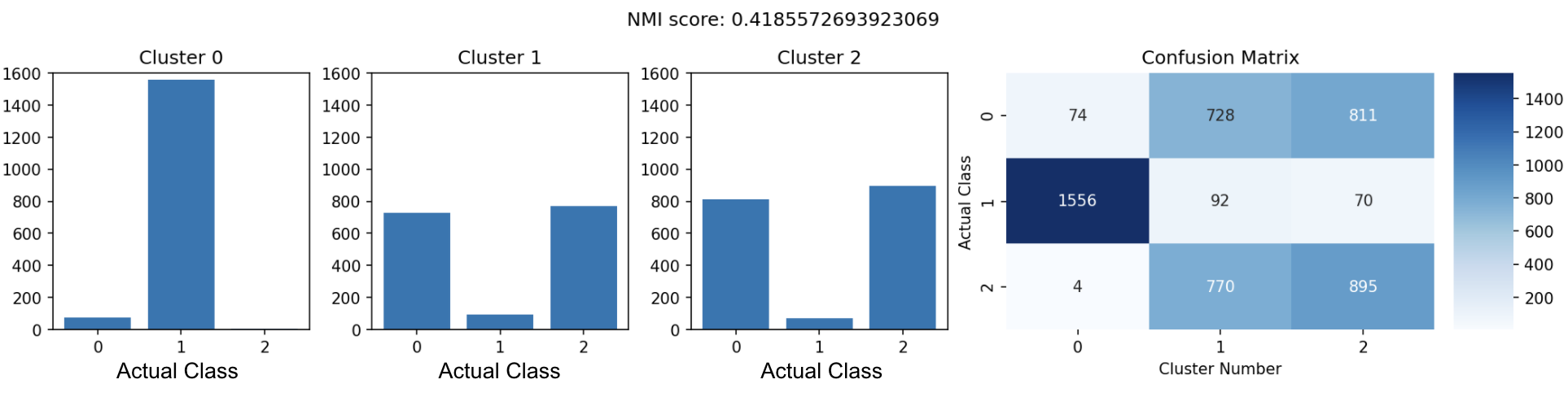
จะเห็นได้ว่าตอนนี้ NMI score ได้แค่ 0.42 แล้วก็ใน cluster 1 กับ 2 นัั้นมันจะปน ๆ กันระหว่างรูปเสื้อแขนยาว (class 0) กับเสื้อแขนสั้น (class 2)
ถ้าไม่รู้ว่า NMI score คืออะไรมีอธิบายอยู่ล่างสุดเลยจ้า
-
เทรนไปเรื่อย ๆ โดยที่ในแต่ละ epoch จะมีโค้ดรวม ๆ ง่าย ๆ ดังนี้
for i in tqdm.tqdm(range(0,1000+1)): features = feature_generator.predict(images) kmean = KMeans(n_clusters=n_cluster, random_state=np.random.randint(1234)) clustering_result = kmean.fit_predict(features) pseudo_label = to_categorical(clustering_result, num_classes=n_cluster) classifier = gen_classifier() classifier.fit(images,pseudo_label, epochs=1, verbose=False)ซึ่งเดี๋ยวจะอธิบายทีละบรรทัดเลย
-
ก่อนอื่น เราสร้าง latent vector หรือ feature ของแต่ละรูปด้วย feature generator ก่อน
features = feature_generator.predict(images)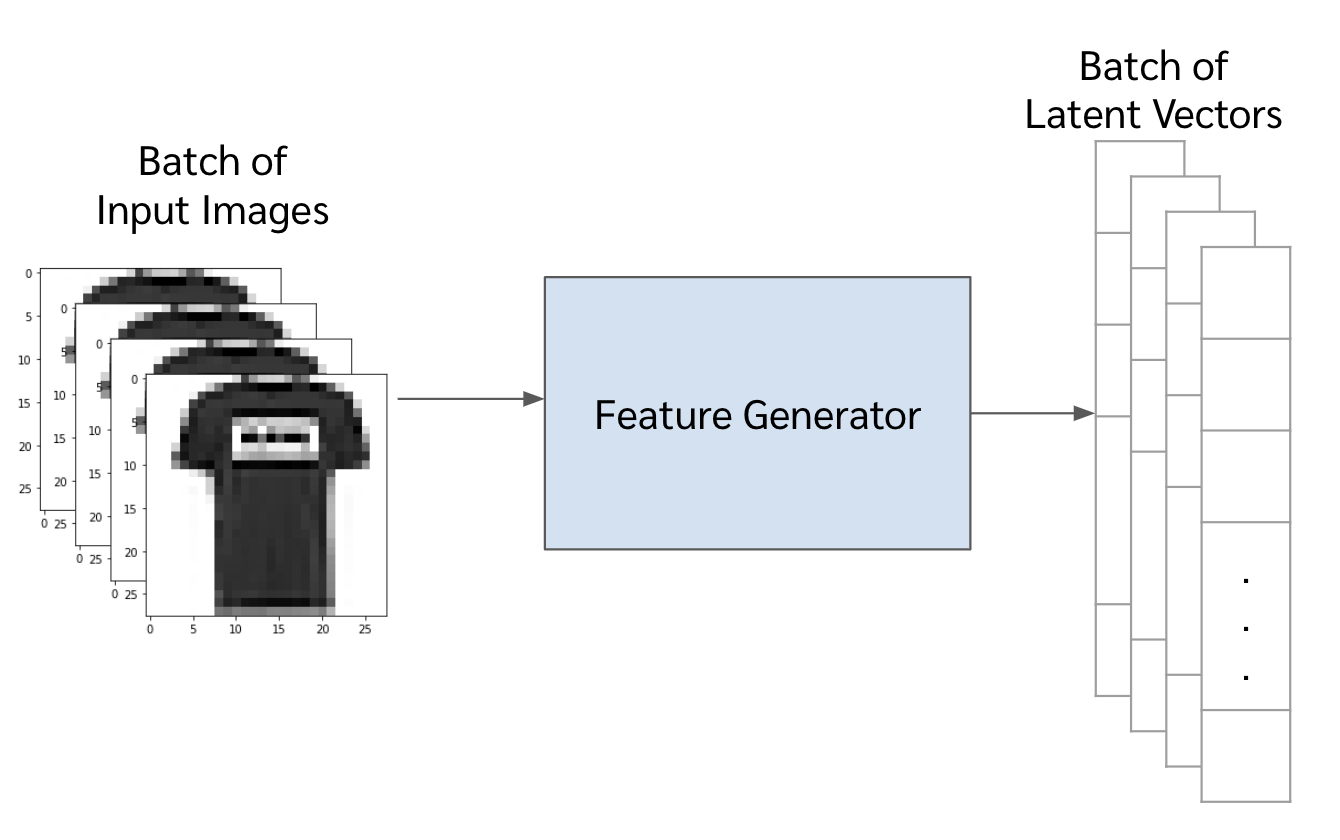
ที่จริงแล้วในเปเปอร์มีการนำ latent_vectors ขนาด 4096 ไปแปลงต่อด้วย PCA ให้เหลือแค่ขนาด 256 แล้ว regularize ด้วย l2 แล้วจึงนำเข้า K-mean แต่ ในบทความนี้ข้ามไปเพราะตัว latent vector เราก็เล็กอยู่แล้ว
-
ต่อมาเอา vectors พวกนั้นไปจัดกลุ่มด้วย Kmean clustering
kmean = KMeans(n_clusters=n_cluster, random_state=np.random.randint(1234)) clustering_result = kmean.fit_predict(features)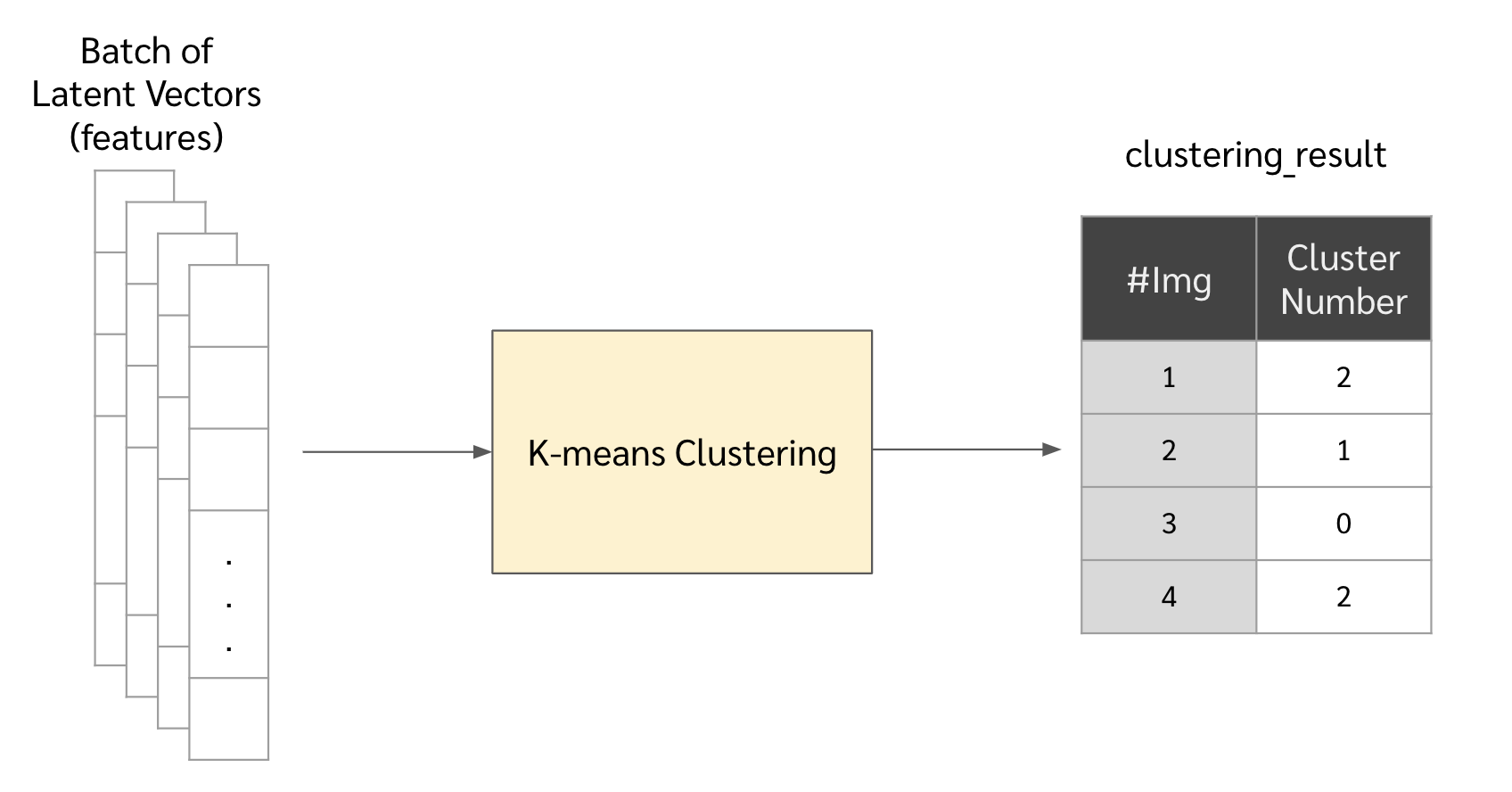
-
แล้วเอาผลของการจัดกลุ่มมาเป็น pseudo label
pseudo_label = to_categorical(clustering_result, num_classes=n_cluster)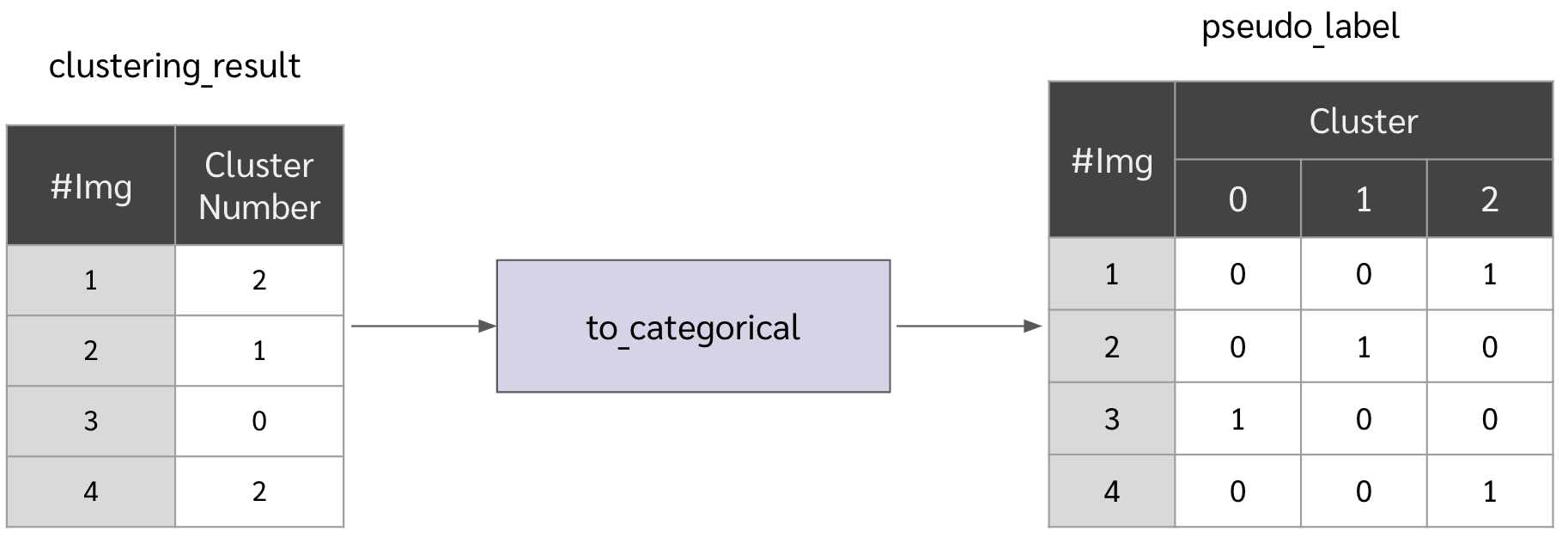
ที่จริงแล้วในขั้นตอนนี้ในเปเปอร์มีการทำเพิ่มเติมอีก 2 อย่างด้วยกัน เพื่อป้องกันปัญหา empty clusters และ trivial parameterization ซึ่งเดี๋ยวจะพูดถึงใน section ถัดไป ว่ามันคืออะไรแล้วผู้เขียนเปเปอร์เสนอให้แก้ปัญหานี้อย่างไร
-
ใช้ฟังก์ชันในข้อที่ 2. มาสร้าง classifier (หรือก็คือสร้าง top layer ขึ้นมาใหม่ แล้วต่อมันไปบน feature generator)
classifier = gen_classifier()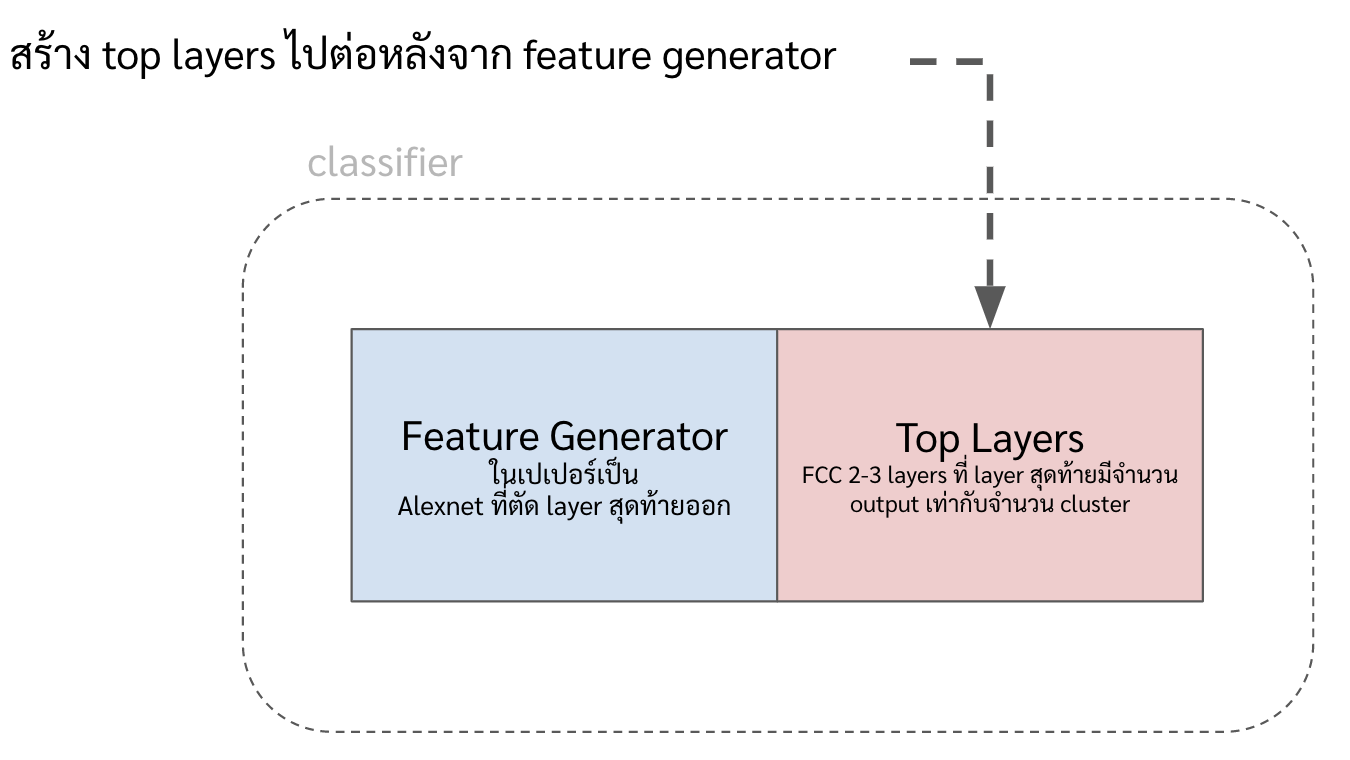
ปล. สำหรับคนที่งงว่าทำไมเราต้องสร้างตัว top layer ใหม่ทุกรอบเลย (ทำไมเราไม่เก็บ classifier ไว้ใช้ จะสร้างใหม่ทำไมทุก epoch) เอาจริง ๆ เหมือนเค้าไม่ได้ discuss เรื่องนี้ในเปเปอร์นะ แต่ผมคิดว่ามันน่าจะเป็นเพราะว่าตัวเลข cluster มันอาจจะเปลี่ยนไปเรื่อย ๆ ในแต่ละ epoch เราเลยต้องลบตัว top layer ทิ้ง คือให้มองว่าตัว feature_generator จะมีหน้าที่ในการสร้างฟีเจอร์ขึ้นมา ส่วนตัว top layer มีหน้าที่ในการแมพฟีเจอร์พวกนั้นไปแต่ละ cluster (แต่ละเลข cluster)
-
เทรน classifier โดยมี input เป็น image และ label เป็น pseudo label ที่ได้มาในข้อก่อนหน้า ซึ่งในขั้นตอนนี้ตอนที่เราใช้คำสั่ง
fitนั้น มันจะทำการ backpropagate กลับไปอัพเดท weight ทั้งใน top layers และใน feature generatorclassifier = gen_classifier() classifier.fit(images, pseudo_label, epochs=1, verbose=False)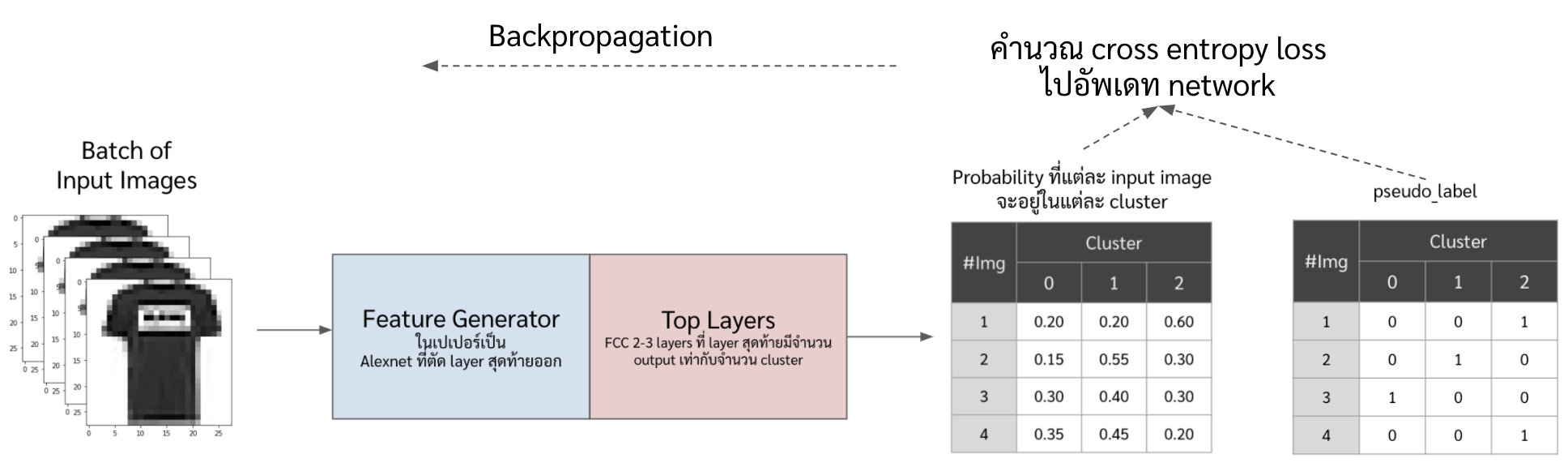
-
ขั้นสุดท้ายก็คือตัด top layer ทิ้ง (แต่ขั้นนี้ไม่ต้องเขียนโค้ดอะไร เพราะเดี๋ยวเราสร้าง classifier ด้วยการสร้าง top layer อันใหม่ไปต่อจาก feature generator อยู่แล้ว ในนี้แค่อยากใส่ไว้ให้ดูเฉย ๆ)
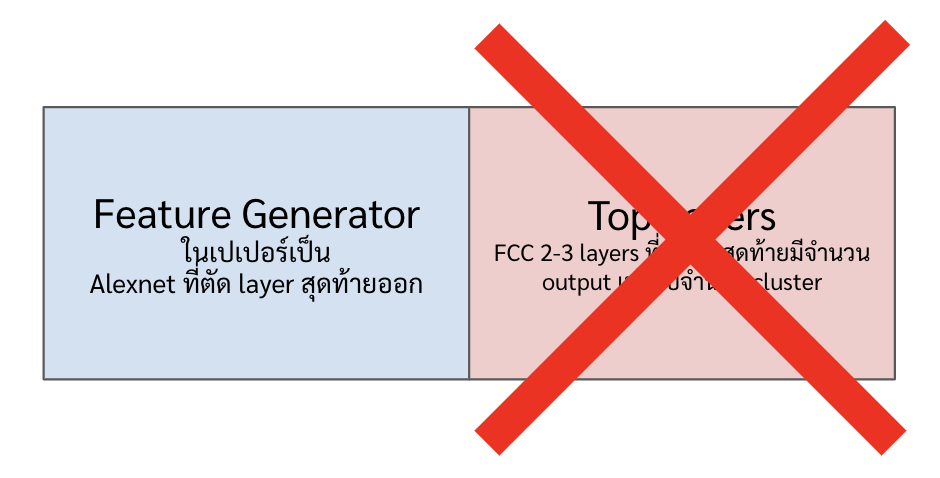
-
-
พอเทรนเสร็จตามจำนวน epoch ที่เราตั้งไว้ก็มาดูผลกัน
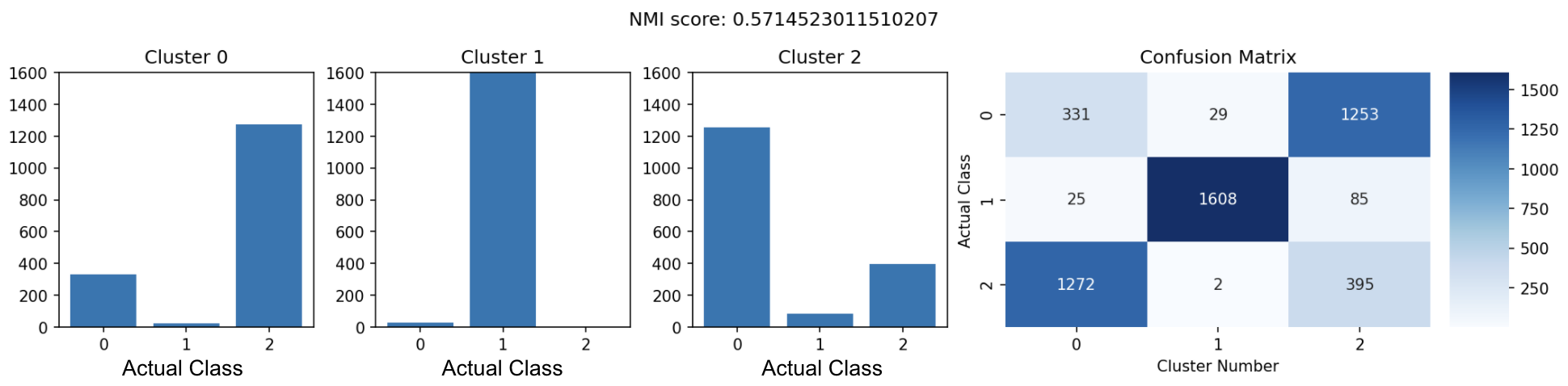
จะเห็นได้ว่าตอนนี้ NMI score เพิ่มจาก 0.42 มาเป็น 0.57 แล้วก็ใน cluster 0 กับ 2 นัั้นมันจะหนักไปทาง label ใด label หนึ่งมากขึ้น เช่น cluster 0 นั้นก็จะเป็นกลุ่มของเสื้อแขนยาว (class 2)
ประเด็นอื่น ๆ
ปัญหา Trivial Solution
Empty Cluster
ปัญหา: คือที่จริงแล้ว solution ที่จะทำให้ loss ในสมการที่ \eqref{eq:deep_cluster} เหลือน้อยที่สุดก็คือการที่
- ตัว feature generator ทำให้ทุกรูปได้ latent vector เหมือนกัน
- ที่นี้ตัว Kmeans ก็เลยจัดทุกรูปให้อยู่ใน cluster เดียวกัน (ทุกรูปมี pseudo label เหมือนกันหมดเลย)
- ต่อมาตัว classifier ก็พรีดิกออกมาแค่เลขเดียว
ก็แปลว่า จากสมการที่ \eqref{eq:deep_cluster} ถ้าเราหา \(\theta\) ที่ทำให้ใส่รูปอะไรเข้าไปแล้วมันได้ latent vector หรือ \(f_{\theta}(x)\) ที่หน้าตาเหมือนกันออกมา เราจะทำให้ loss ในสมการที่ \eqref{eq:deep_cluster} กลายเป็น 0 ไปเลย สุดยอดดดดดด (ซะที่ไหนล่ะ)
วิธีแก้:ในเปเปอร์นี้แก้กันง่าย ๆ เลยก็คือ ถ้ามันมี cluster ที่ไม่มีข้อมูลอยู่เลย เราจะเอา centroid ของ cluster ที่มีข้อมูลมาเปลี่ยน ๆ นิดนึง (random +- นิดหน่อย) แล้วแบ่ง cluster นั้นออกเป็น 2 clusters ทำไปเรื่อย ๆ จนกว่าจะมีจำนวน cluster ที่มีข้อมูลเท่ากับจำนวน cluster ที่เราตั้งไว้ แล้วค่อยเอาไปทำ pseudo-label แล้วไปเทรนต่อ หรือก็คือเราบังคับมันให้ทำการแบ่งกลุ่มอยู่ตลอดเวลา และหวังว่าเมื่อเทรนไปเรื่อย ๆ กลุ่มพวกนั้นจะเป็นกลุ่มที่เราต้องการให้แบ่ง
Trivial Parametrization
ปัญหา:เป็นปัญหาที่เกิดจากเกิด cluster นึงที่ใหญ่มากกว่า cluster กลุ่มอื่นขึ้นมา ซึ่งที่จริงอาจจะเกิดจากจำนวนรูปแต่ละประเภทมีไม่เท่ากันก็ได้ ถ้าเกิดแบบนี้ขึ้นมา neural network เราก็จะ classify ได้ไม่ดี (ที่จริงมันก็คือปัญหา imbalance class ธรรมดานั่นแหละ)
วิธีแก้:ซึ่งในเปเปอร์นี้เค้าแก้ด้วยการ sample ข้อมูลจากแต่ละ cluster ให้เท่า ๆ กันก่อนเอามาเทรน (เท่าที่เข้าใจมันก็คือ downsampling)
Trivial Feature
ปัญหา:เป็นปัญหาที่เกิดจากตัว CNN เราไปเรียนรู้อย่างอื่นแทนที่จะเป็นสิ่งที่เราต้องการ เช่น เราต้องการให้แยกรูปนกกะแมว มันดันไปเรียนรู้เรื่องสีแล้ว deepcluster เราก็ไป cluster ตามสี แทนที่จะไปเรียนรู้เรื่องฟีเจอร์ที่เกี่ยวกับนกหรือแมวจริงๆเช่น มีปีกหรือไม่มีปีก, มีสองหรือสี่ขา, ฯลฯ
จากรูปด้านล่างเค้าลองเอา filter ของ alexnet ที่เทรนด้วยรูปสี (ทางซ้าย) และรูปขาวดำที่ผ่านการทำ edge detection มา (ทางขวา) ออกมาดู เราจะพบว่ามันมีพวก filter จำนวนนึงในรูปทางซ้ายที่เป็นสีเหลี่ยมที่มีแต่สี ไม่มีลายอะไรเลย ซึ่งก็คือ filter พวกนั้นมันโฟกัสแต่สีของภาพ ไม่ได้เรียนรู้การจับขอบหรือรูปทรงของวัตถุในภาพซึ่งสำคัญกว่าสี

วิธีแก้:ในเปเปอร์นี้เค้าเลยเสนอให้ทำ edge detection ด้วย sobel ก่อนนำเข้าโมเดล (ก็คือเค้าไม่เอาสีเข้าโมเดล) ซึ่งเป็นการช่วยสกัดฟีเจอร์ให้นิดนึงก่อน
จำนวน cluster (ค่า k) เป็นเท่าไหร่ดี ?
ก็ที่จริงก็เหมือนเวลาเราทำ clustering ทั่ว ๆ ไปก็คือเราก็ต้องหาเอาว่าเท่าไหร่ดีที่สุด อย่างในเปเปอร์เค้าลองทำกับข้อมูล ImageNet ที่มี 1,000 classes แต่เค้าจูนค่า k ไปเรื่อย ๆ จนพบว่าค่า k ที่ 10,000 น่ะดีที่สุด
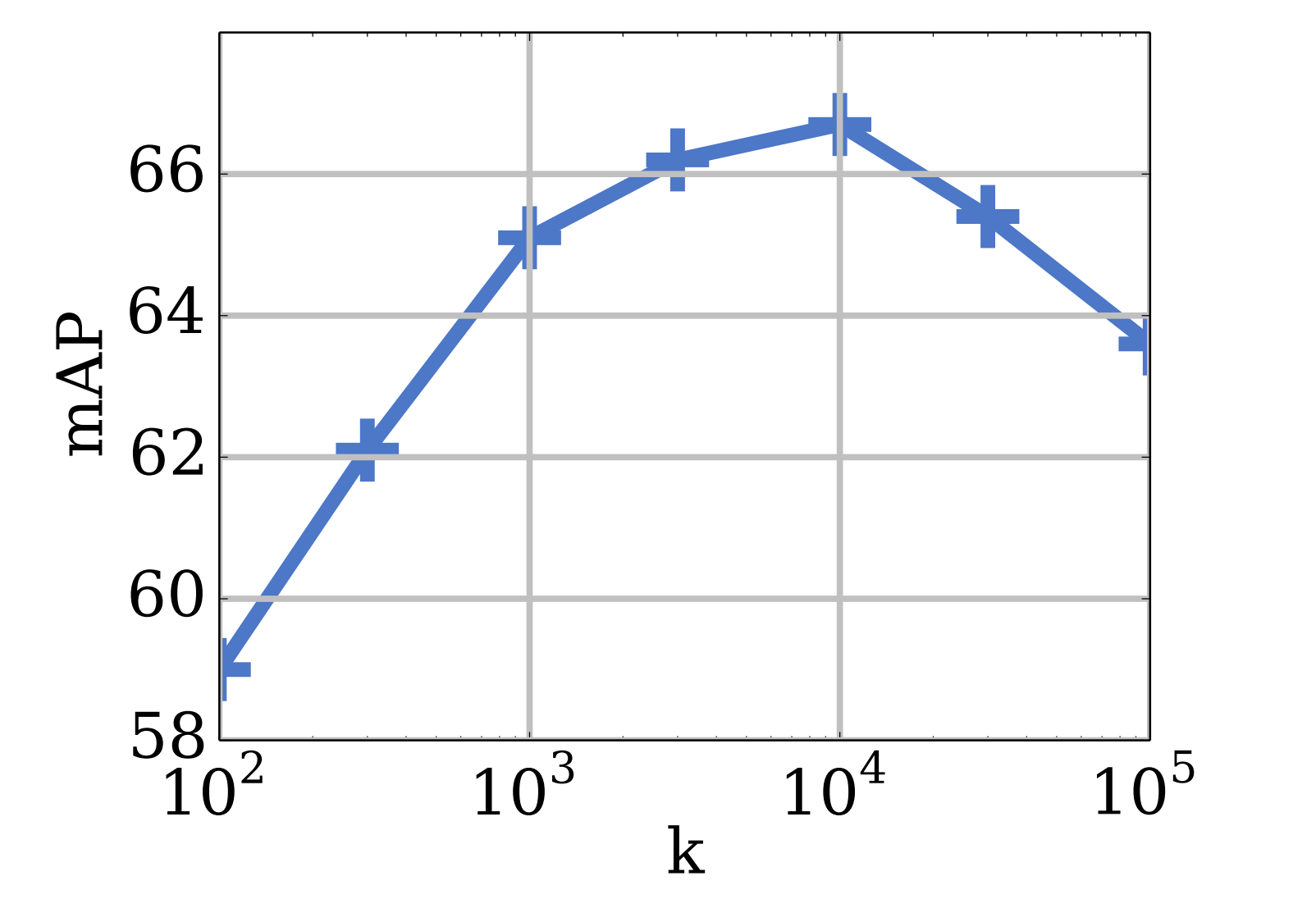
Appendix
Normalized Mutual Information (NMI Score)
NMI score เป็น score ที่มีค่าระหว่าง 0-1 ซึ่งวัดว่า information ระหว่างข้อมูลสองชุดนั้นตรงกันแค่ไหนโดยที่ไม่สนตัวเลข label เช่น
- ถ้าเรามีข้อมูลสองชุด ได้แก่ $[0,2,2,1,1,0]$ และ $[2,1,1,0,0,2]$
- ในกรณีนี้เราจะได้ NMI score เป็น 1
- จะเห็นได้ว่าการแบ่งกลุ่มข้อมูลนั้นเหมือนกันในสองกลุ่ม เพียงแค่เลข label เราเปลี่ยนไป (จากเลข 0 เป็น 2, จาก 2 เป็น 1, จาก 1 เป็น 0)
- ถ้าเรามีข้อมูลสองชุด ได้แก่ $[0,2,2,1,1,0]$ และ $[0,0,2,1,0,1]$
- ในกรณีนี้เราจะได้ NMI score เป็นแค่ 0.30 เท่านั้น
โดยสูตรของ NMI score นั้น เป็นดังนี้
\begin{equation} \label{eq:NMI} \frac{I(Y;C)}{H(Y)H(C)} \end{equation}
โดยที่
- \(I(Y;C)\) คือ mutual information ระหว่าง \(Y\) และ \(C\)
- \(H(x)\) คือ entropy ของ \(x\)
Discliamer
รายละเอียดในบทความนี้มาจากความเข้าใจส่วนตัว อาจมีข้อผิดพลาด หากพบจุดผิดพลาด ขอความกรุณาแจ้งทาง facebook หรือ email: thammasorn.han@hotmail.com