นอกจาก Supervised-learning และ Unsupervised-learning ที่ใช้ในการทำนายหรือการจัดกลุ่ม ใน Machine learning นั้นยังมีอีกประเภทหนึ่งของ algorithm ที่ชื่อว่า reinforcement learning ซึ่งเราจะไปทำความรู้จักมันโดยคร่าวว่าในบทความนี้กันครับ
Outline
- Reinforcement Learning คืออะไร ?
- Markov Decision Process คืออะไร ?
- ประเภทของ Reinforcement Learning
Reinforcement Learning คืออะไร ?
Reinforcement Learning เป็นด้านหนึ่งของ machine learning หรือ artificial intelligence(AI) ที่ใช้สำหรับพัฒนา robot (ซึ่งปกติเรียกกันว่า agent) ให้สามารถตัดสินใจภายใต้แต่ละสถานการณ์เพื่อนำมาซึ่งผลลัพธ์ที่ดีที่สุดในระยะยาว โดยที่ robot นั้นจะไม่ได้ถูกบอกให้รู้ถึงกฎเกณฑ์ในการเลือกกระทำสิ่งใดภายใต้สถานการณ์ใดโดยตรง แต่ robot จะพยายามพัฒนาระบบความคิดการตัดสินใจเองจากการทดลองผิดลองถูกและเรียนรู้ไปเรื่อย ๆ
ตัวอย่างเช่น ถ้าเราต้องการจะสร้าง robot ที่สามารถซื้อขายหุ้นให้ได้กำไรได้มากที่สุด robot จะต้องตัดสินใจที่จะซื้อ, ขาย หรือจะอยู่เฉย ๆ ภายใต้สถานการณ์ที่อาจจะเป็นราคาหุ้นย้อนหลัง 30 วัน, จำนวนหุ้นในพอร์ต, จำนวนเงินคงเหลือในพอร์ต ฯลฯ ซึ่งในปัจจุบันอาจจะมีการพัฒนาระบบเพื่อซื้อขายหุ้นอัตโนมัติขึ้นมาที่มีกฎเกณฑ์การตัดสินใจที่แน่นอนอยู่แล้ว เช่น ถ้าราคาวันนี้มากกว่าค่าเฉลี่ยย้อนหลัง 5 วันให้ซื้อ ถ้าราคาวันนี้น้อยว่าค่าเฉลี่ยย้อนหลัง 5 วันให้ขาย ฯลฯ แต่ robot ที่พัฒนาใต้แนวคิด reinforcement learning จะแตกต่างกันออกไป
reinforcement learning นั้นตั้งอยู่ภายใต้แนวคิดที่ว่า robot จะเลือกกระทำสิ่งที่ทำให้ได้ผลลัพธ์มากที่สุด ถ้าเราเปรียบเทียบกับการเล่นหุ้น
- สมมติว่าวันนี้ในพอร์ตหุ้นมีหุ้น CPALL ในราคา 62 บาท (ซื้อมา 59 บาท) ซึ่งในวันนี้ราคานั้นลดต่ำกว่าค่าเฉลี่ยย้อนหลัง 5 วันไปแล้ว
- robot ของเราจะต้องตัดสินใจว่าจะขายหรือจะถือต่อ
- ถ้า robot ตัดสินใจจะขายเลย จะได้กำไรแน่ ๆ แล้ว 3 บาทต่อหุ้นหนึ่งตัว แต่ถ้ายังถือหุ้นตัวนั้นต่อไปราคาอาจจะขึ้นทำให้ได้กำไรมากกว่าที่ได้อยู่ก็ได้ เพราะฉะนั้นสิ่งที่ robot ตัวนี้ทำคือมันจะไม่ได้มองแค่สถานการณ์ในปัจจุบัน แต่คาดการณ์ไปถึงความน่าจะเป็นของสถานการณ์ต่อ ๆ ไปเพื่อเลือกการกระทำที่ดีที่สุด เช่น ถ้า robot คิดแล้วว่าในอนาคตราคาอาจจะกลับขึ้นมาอีกในเวลาอันใกล้ robot ก็จะไม่ขาย
คำถามต่อมาคือแล้ว robot ของเราจะรู้ได้อย่างไร ว่าการกระทำใดจะทำให้ได้ผลลัพธ์มากที่สุด คำตอบของคำถามนี้เป็นหัวใจหลักของ reinforcement learning เลยก็ว่าได้ ก็คือ robot จะทำการเรียนรู้จากการลองผิดลองถูก (trial-and-error) ในสถานการณ์ในอดีตหรือระบบจำลองและพยายามที่จะพัฒนาระบบการตัดสินใจของตัวเองให้ดีขึ้นเรื่อย ๆ โดยที่วิธีในการนำประสบการณ์มาพัฒนาระบบการตัดสินใจนั้น สามารถแบ่งออกเป็นได้หลายวิธีด้วยกันซึ่งเราจะมาดูกันใน section ถัดไปของบทความนี้
ในปัจจุบัน reinforcement learning ถูกนำไปประยุกต์ใช้ในหลายด้านด้วยกัน เช่น Google นำไปพัฒนา AlphaGo ที่สามารถเล่นเกมโกะให้ชนะผู้เล่นระดับโลกหลายต่อหลายคนได้ หรือจะเป็น OpenAI ของ Elon Musk ก็นำไปพัฒนา OpenAI Five ให้สามารถเล่นเกม DotA2 กับผู้เล่นมืออาชีพได้อย่างสูสี นอกจากงานวิจัยด้านเกมเพื่อโชว์ความสามารถของ reinforcement learning แล้ว ยังมีคนนำไปประยุกต์เพื่อใช้ในด้านการเงิน เช่น นำไปพัฒนาระบบการจัดการ portfolio ให้ตัดสินใจเลือกอัตราส่วนของสินทรัพย์ high risk กับ low risk ใน portfolio ให้สามารถทำกำไร ภายใต้ความเสี่ยงที่ต่ำ (ตัวอย่าง arXiv:1706.10059) นอกจากที่กล่าวมายังมีด้านอื่น ๆ อีกหลายด้านให้ตามกันต่อไป
Markov Decision Process
ก่อนจะไปไกลกว่านี้ อยากให้เข้าใจรูปแบบของปัญหาที่เราจะใช้ RL แก้กันก่อน รูปแบบบของปัญหาที่เราจะใช้ RL แก้นั้นจะอยู่ในรูปแบบของ Markov Decision Process (MDP) โดยที่ MDP นั้นจะคล้าย ๆ กับ Markov Chain แต่มีการเพิ่มส่วนของ Action และ Reward เข้าไป
Markov Chain model นั้นเป็นโมเดลที่มีไว้จำลอง environment หรือสถานการณ์ต่าง ๆ โดยจะแบ่งสถานการณ์ต่าง ๆ ที่อยู่ใน environement นั้นออกเป็น state และแต่ละ state นั้นจะมีความน่าจะเป็นที่จะเปลี่ยนไป state อื่น ๆ ที่แตกต่างกัน
เพื่อให้เข้าใจได้โดยง่าย ขอยกตัวอย่างดังรูปด้านล่าง ใน Markov Chain ของรูปด้านล่างนั้น ประกอบด้วย 2 states ด้วยกัน ได้แก่ฟ้าใสและฝนตก
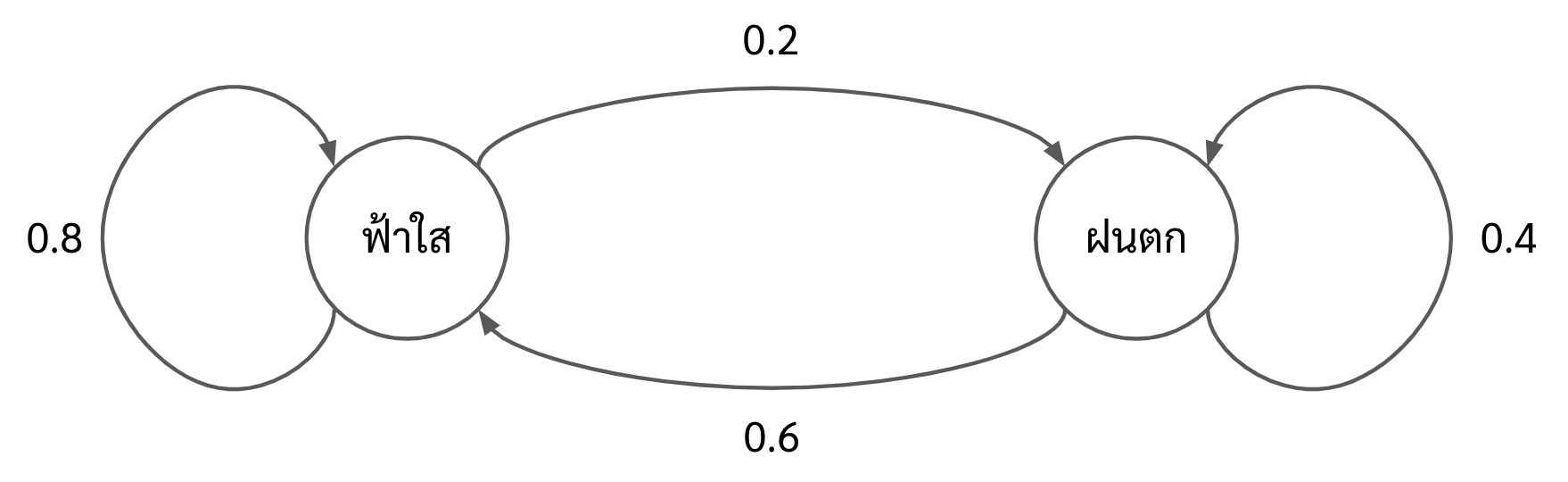
ซึ่งเราสามารถอธิบาย Markov Chain จากรูปด้านบนได้ดังนี้
- ถ้าวันนี้ฟ้าใสแล้ว
- โอกาสที่วันพรุ่งนี้จะฟ้าใสด้วยเป็น 80%
- โอกาสที่วันพรุ่งนี้จะฝนตกเป็น 20%
- ถ้าวันนี้ฝนตกแล้ว
- โอกาสที่วันพรุ่งนี้จะฝนตกด้วยเป็น 40%
- โอกาสที่วันพรุ่งนี้จะฟ้าใสเป็น 60% โดยที่ความน่าจะเป็นในการเปลี่ยน state ทั้งหลายนั้น เราเรียกว่า transition probability
ซึ่งอย่างที่กล่าวไปข้างต้น ในส่วนของ Markov Decision Process นั้น มันคือ Markov Chain ที่เพิ่ม action และ reward เข้าไป โดยที่ action นั้นจะมีผลต่อ transition probability ด้วย และในแต่ละ transition probability นั้นจะมีโอกาสในการได้รับ reward ที่แตกต่างกันไป ตัวอย่าง MDP นั้นแสดงดังรูปด้านล่าง
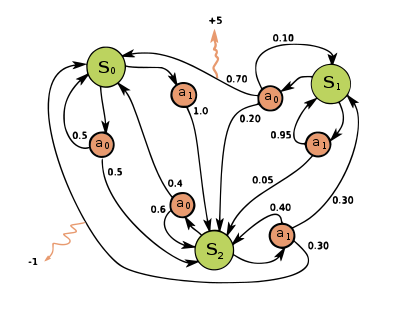
จะเห็นได้ว่าในรูปด้านบนนั้นประกอบไปด้วย 3 states ด้วยกัน และในแต่ละ state นั้นจะมี action ให้เลือกทำได้ 2 actions ด้วยกัน ซึ่งจะเห็นได้ว่าหากเลือก action แตกต่างกันในแต่ละ state นั้นจะทำให้ความน่าจะเป็นของ state ถัดไปนั้นก็จะแตกต่างกันไปด้วย เช่น สมมติว่าเราอยู่ใน state ที่ 1 หรือ \(S_1\) แล้วเราเลือก action ที่ 0 หรือ \(a_0\) นั้น
- มีโอกาส 70% ที่ timestep ถัดไป เราจะอยู่ใน state \(S_0\) และได้รับ reward +5
- มีโอกาส 20% ที่ timestep ถัดไป เราจะอยู่ใน state \(S_2\) และไม่ได้รับ reward เลย
- มีโอกาส 10% ที่ timestep ถัดไป เราจะอยู่ใน state \(S_1\) หรือ state เดิม และไม่ได้รับ reward เลย
ซึ่งหากเราเลือก action \(a_1\) แทนนั้นโอกาสของ timestep ถัดไปจะแตกต่างกันไปโดยที่
- มีโอกาส 95% ที่ timestep ถัดไป เราจะอยู่ใน state \(S_1\) หรือ state เดิม และไม่ได้รับ reward เลย
- มีโอกาส 5% ที่ timestep ถัดไป เราจะอยู่ใน state \(S_2\) และไม่ได้รับ reward เลย
โดยที่ปัญหาหลักของ MDP นั้นคือเราต้องดีไซน์ระบบการตัดสินใจที่สามารถตัดสินใจได้ว่าเราควรเลือกทำ action ในแต่ละ state เพื่อทำให้เราได้ reward มากที่สุดในระยะยาว หรือเราสามารถเขียน objective value ของ MDP ได้ดังสมการด้านล่าง
\begin{equation} \label{eq:Gt} G_t = \sum_{t=1}^{\infty} \gamma^t r_t \end{equation}
ซึ่ง reinforcement learning นั้นเป็นเดอะแก๊ง algorithm ที่เอาไว้แก้ปัญหา MDP โดยการสร้าง policy function หรือ \(\pi\) ขึ้นมา ซึ่งเป็น function ที่รับ state เข้าไปแล้วจะ return ออกมาเป็น optimal action ของ state นั้น ๆ
\begin{equation} \label{eq:policy} a^{\star}_t = \pi(s_t) \end{equation}
ประเภทของ reinforcement learning algorithm
-
Model based
เหล่า algorithms ในประเภทนี้จะพยายามเรียนรู้กลไกของสภาพแวดล้อม (environment) ที่เราจะให้ robot เราไปทำงาน แล้วค่อยพัฒนาระบบการตัดสินใจจากข้อมูล environment เหล่านั้น เช่น พยายามสร้างแบบจำลอง MDP ของ environment แล้วค่อยคิดต่อจากแบบจำลองนั้น ว่าควรทำ action อะไรดี ปล. ในฝั่งนี้ผมยังไม่ค่อยได้ศึกษาเท่าไหร่ เอาไว้ศึกษาดี ๆ แล้วจะมาเพิ่มรายละเอียดครับ แหะ ๆ -
Model free
ถึงแม้ว่าวิธีแบบ model base จะดู make sense ดี อย่างไรก็ตาม ไม่ใช่ว่าทุก environment ที่เราจะไปเรียนรู้กลไกลมันได้ง่าย ๆ ก็เลยเกิดวิธีแบบ model free ขึ้นมา ซึ่งเป็นวิธีที่นิยมมากกว่า model based ซะอีก
โดยที่วิธีแบบ model free นี้เราจะพยายามพัฒนา policy function แบบที่ไม่ต้องพยายามทำความเข้าใจ environment เลย แต่จะใช้ข้อมูลจากประสบการณ์ใน environment นั้น ๆ มาปรับปรุงการตัดสินใจหรือ policy function ให้ดีขึ้นไปเรื่อย ๆ
ซึ่งพวก algorithm ในตระกูลนี้ก็จะถูกแบ่งได้เป็น 3 ประเภทด้วยกัน ได้แก่- Value-Based
ในเดอะแก๊งนี้ เราจะพยายามประมาณค่า long-term reward ที่จะได้จากการทำแต่ละ action ในแต่ละ state แล้วเราก็ค่อยเลือกตัดสินใจทำ action ที่มีค่าประมาณ long-term reward มากที่สุด ตัวอย่าง algorithm ในประเภทนี้ก็เช่น SARSA, Q-learning ข้อดีของ algorithm ประเภทนี้ก็คือ เรารู้ค่าประมาณของ long-term reward ตั้งแต่ก่อนตัดสินใจ ซึ่งอาจจะช่วยในเรื่องของการตีความพฤติกรรมของ agent แต่ข้อเสียที่ใหญ่หลวงที่สุดคือมันทำงานได้กับแค่ปัญหาที่ action space เป็น discrete หรือจำนวน action มีจำกัดเท่านั้น เพราะว่าเราต้องประมาณค่า long-term reward ของทุก action ในทุก state ถ้ามีจำนวน action เป็น infinite เราก็จะประมาณไม่ไหวเอา ซึ่งรายละเอียดของเรื่องพวกนี้เดี๋ยวจะยกยอดไปในบทความ Q-learning อันต่อ ๆ ไป - Policy-Based
ในเดอะแก๊งนี้ เราจะนำค่า reward ไปกำหนดทิศทางของ gradient ในการอัพเดท policy โดยตรง เช่นถ้าเราทำ action 0 ได้ reward น้อย ซึ่งข้อดีของ algorithm ประเภทนี้คือเราสามารถให้มันทำงานได้กับปัญหาที่ action space เป็น infinite ได้ แต่ข้อเสียคือเราจะตีความพฤติกรรมของ agent ยากกว่า - Actor-Critic
ในวิธีนี้เป็นส่วนผสมระหว่าง value-based และ policy-based โดยที่เราจะใช้ทั้งคู่เลย- ตัว policy based นั้น จะถูกเรียกกว่า actor มีหน้าที่รับ state เข้าไปและ return ออกมาเป็น action
- ตัว value based นั้น จะถูกเรียกว่า critic มีหน้าที่ประเมินว่า action ที่ actor ตัดสินใจมานั้น จะทำให้เราได้รับ long-term reward ประมาณเท่าไหร่ จากนั้นตัว actor จึง update การตัดสินใจของตัวมันเองจาก feedback ที่ critic ประเมินให้ ตัวอย่าง algorithm ประเภทนี้ได้แก่ Deep deterministic policy gradient (DDPG), Proximal Policy Optimization (PPO) ซึ่งจะเอาไว้เขียนโดยละเอียดให้ในภายภาคหน้า
- Value-Based